 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeLIP: Similarity Enhanced Contrastive Language Image Pretraining for Multi-modal Head MRI
Mar 25, 2025



Despite that deep learning (DL) methods have presented tremendous potential in many medical image analysis tasks, the practical applications of medical DL models are limited due to the lack of enough data samples with manual annotations. By noting that the clinical radiology examinations are associated with radiology reports that describe the images, we propose to develop a foundation model for multi-model head MRI by using contrastive learning on the images and the corresponding radiology findings. In particular, a contrastive learning framework is proposed, where a mixed syntax and semantic similarity matching metric is integrated to reduce the thirst of extreme large dataset in conventional contrastive learning framework. Our proposed similarity enhanced contrastive language image pretraining (SeLIP) is able to effectively extract more useful features. Experiments revealed that our proposed SeLIP performs well in many downstream tasks including image-text retrieval task, classification task, and image segmentation, which highlights the importance of considering the similarities among texts describing different images in developing medical image foundation models.
ConcertoRL: An Innovative Time-Interleaved Reinforcement Learning Approach for Enhanced Control in Direct-Drive Tandem-Wing Vehicles
May 22, 2024



In control problems for insect-scale direct-drive experimental platforms under tandem wing influence, the primary challenge facing existing reinforcement learning models is their limited safety in the exploration process and the stability of the continuous training process. We introduce the ConcertoRL algorithm to enhance control precision and stabilize the online training process, which consists of two main innovations: a time-interleaved mechanism to interweave classical controllers with reinforcement learning-based controllers aiming to improve control precision in the initial stages, a policy composer organizes the experience gained from previous learning to ensure the stability of the online training process. This paper conducts a series of experiments. First, experiments incorporating the time-interleaved mechanism demonstrate a substantial performance boost of approximately 70% over scenarios without reinforcement learning enhancements and a 50% increase in efficiency compared to reference controllers with doubled control frequencies. These results highlight the algorithm's ability to create a synergistic effect that exceeds the sum of its parts.
Vision-Guided Quadrupedal Locomotion in the Wild with Multi-Modal Delay Randomization
Sep 29, 2021
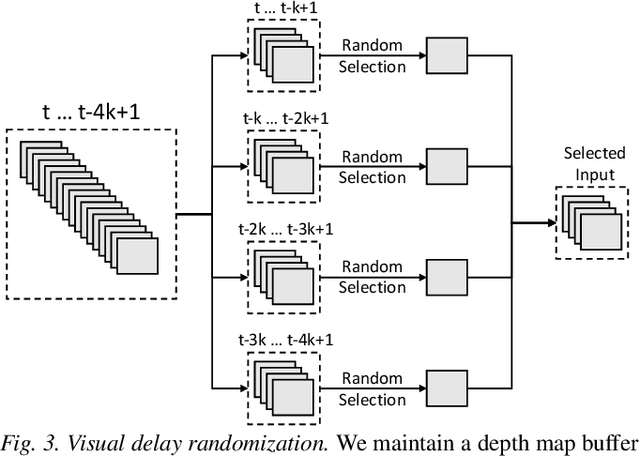

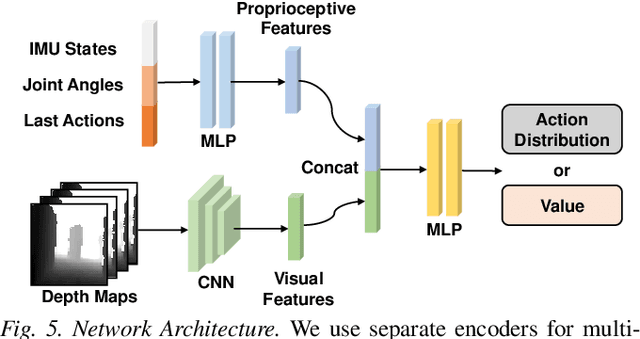
Developing robust vision-guided controllers for quadrupedal robots in complex environments, with various obstacles, dynamical surroundings and uneven terrains, is very challenging. While Reinforcement Learning (RL) provides a promising paradigm for agile locomotion skills with vision inputs in simulation, it is still very challenging to deploy the RL policy in the real world. Our key insight is that aside from the discrepancy in the domain gap, in visual appearance between the simulation and the real world, the latency from the control pipeline is also a major cause of difficulty. In this paper, we propose Multi-Modal Delay Randomization (MMDR) to address this issue when training RL agents. Specifically, we simulate the latency of real hardware by using past observations, sampled with randomized periods, for both proprioception and vision. We train the RL policy for end-to-end control in a physical simulator without any predefined controller or reference motion, and directly deploy it on the real A1 quadruped robot running in the wild. We evaluate our method in different outdoor environments with complex terrains and obstacles. We demonstrate the robot can smoothly maneuver at a high speed, avoid the obstacles, and show significant improvement over the baselines. Our project page with videos is at https://mehooz.github.io/mmdr-wild/.
Tianshou: a Highly Modularized Deep Reinforcement Learning Library
Jul 29, 2021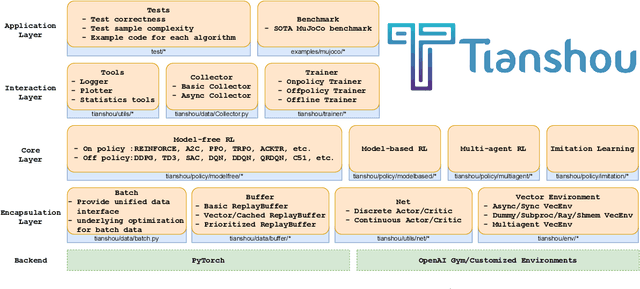

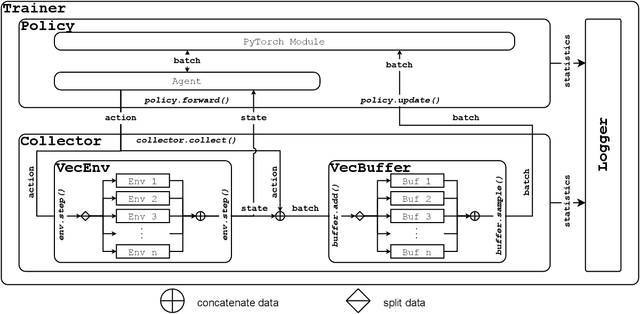

We present Tianshou, a highly modularized python library for deep reinforcement learning (DRL) that uses PyTorch as its backend. Tianshou aims to provide building blocks to replicate common RL experiments and has officially supported more than 15 classic algorithms succinctly. To facilitate related research and prove Tianshou's reliability, we release Tianshou's benchmark of MuJoCo environments, covering 9 classic algorithms and 9/13 Mujoco tasks with state-of-the-art performance. We open-sourced Tianshou at https://github.com/thu-ml/tianshou/, which has received over 3k stars and become one of the most popular PyTorch-based DRL libraries.
Learning Vision-Guided Quadrupedal Locomotion End-to-End with Cross-Modal Transformers
Jul 08, 2021



We propose to address quadrupedal locomotion tasks using Reinforcement Learning (RL) with a Transformer-based model that learns to combine proprioceptive information and high-dimensional depth sensor inputs. While learning-based locomotion has made great advances using RL, most methods still rely on domain randomization for training blind agents that generalize to challenging terrains. Our key insight is that proprioceptive states only offer contact measurements for immediate reaction, whereas an agent equipped with visual sensory observations can learn to proactively maneuver environments with obstacles and uneven terrain by anticipating changes in the environment many steps ahead. In this paper, we introduce LocoTransformer, an end-to-end RL method for quadrupedal locomotion that leverages a Transformer-based model for fusing proprioceptive states and visual observations. We evaluate our method in challenging simulated environments with different obstacles and uneven terrain. We show that our method obtains significant improvements over policies with only proprioceptive state inputs, and that Transformer-based models further improve generalization across environments. Our project page with videos is at https://RchalYang.github.io/LocoTransformer .
Disentangled Attention as Intrinsic Regularization for Bimanual Multi-Object Manipulation
Jul 06, 2021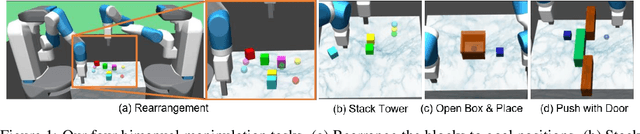

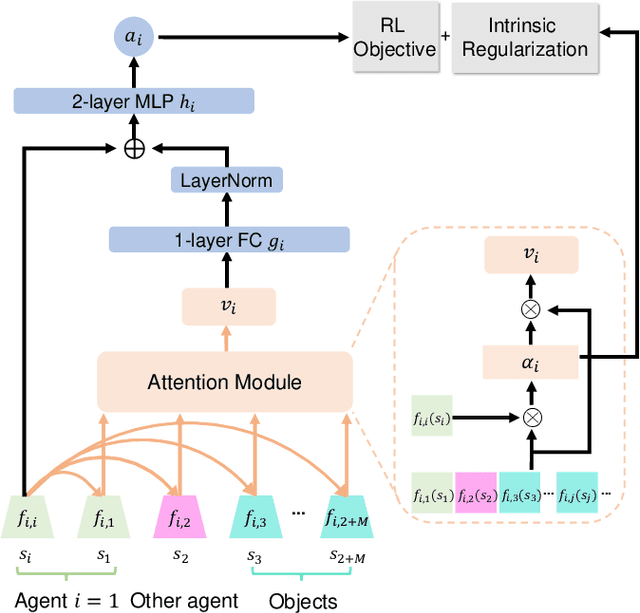

We address the problem of solving complex bimanual robot manipulation tasks on multiple objects with sparse rewards. Such complex tasks can be decomposed into sub-tasks that are accomplishable by different robots concurrently or sequentially for better efficiency. While previous reinforcement learning approaches primarily focus on modeling the compositionality of sub-tasks, two fundamental issues are largely ignored particularly when learning cooperative strategies for two robots: (i) domination, i.e., one robot may try to solve a task by itself and leaves the other idle; (ii) conflict, i.e., one robot can easily interrupt another's workspace when executing different sub-tasks simultaneously. To tackle these two issues, we propose a novel technique called disentangled attention, which provides an intrinsic regularization for two robots to focus on separate sub-tasks and objects. We evaluate our method on four bimanual manipulation tasks. Experimental results show that our proposed intrinsic regularization successfully avoids domination and reduces conflicts for the policies, which leads to significantly more effective cooperative strategies than all the baselines. Our project page with videos is at https://mehooz.github.io/bimanual-attention.
Conformal Three-Dimensional Interphase of Li Metal Anode Revealed by Low Dose Cryo-Electron Microscopy
Jun 10, 2021
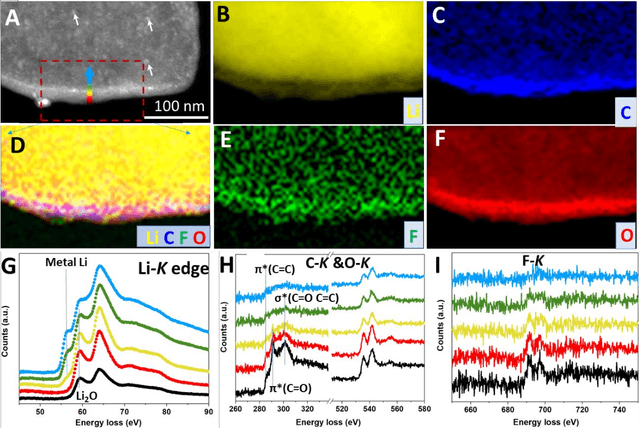
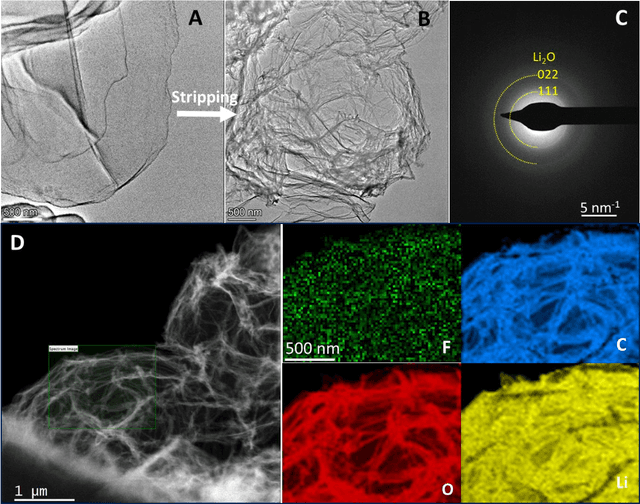
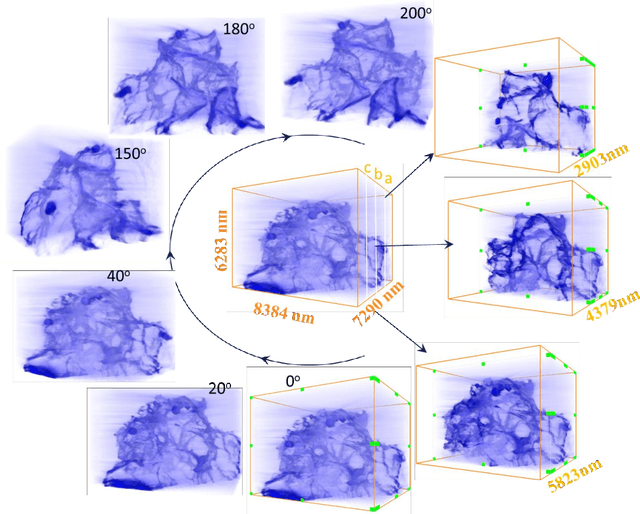
Using cryogenic transmission electron microscopy, we revealed three dimensional (3D) structural details of the electrochemically plated lithium (Li) flakes and their solid electrolyte interphase (SEI), including the composite SEI skin-layer and SEI fossil pieces buried inside the Li matrix. As the SEI skin-layer is largely comprised of nanocrystalline LiF and Li2O in amorphous polymeric matrix, when complete Li stripping occurs, the compromised SEI three-dimensional framework buckles, forming nanoscale bends and wrinkles. We showed that the flexibility and resilience of the SEI skin-layer plays a vital role in preserving an intact SEI 3D framework after Li stripping. The intact SEI network enables the nucleation and growth of the newly plated Li inside the previously formed SEI network in the subsequent cycles, preventing additional large amount of SEI formation between newly plated Li metal and the electrolyte. In addition, cells cycled under the accurately controlled uniaxial pressure can further enhance the repeated utilization of the SEI framework and improve the coulombic efficiency (CE) by up to 97%, demonstrating an effective strategy of reducing the formation of additional SEI and inactive dead Li. The identification of such flexible and porous 3D SEI framework clarifies the working mechanism of SEI in lithium metal anode for batteries. The insights provided in this work will inspire researchers to design more functional artificial 3D SEI on other metal anodes to improve rechargeable metal battery with long cycle life.
Bridging Imagination and Reality for Model-Based Deep Reinforcement Learning
Oct 23, 2020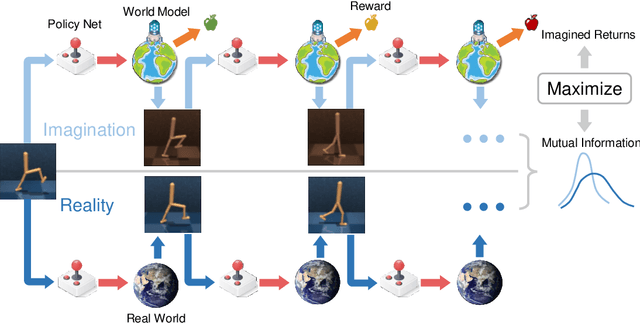

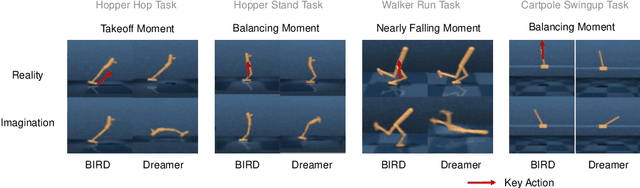
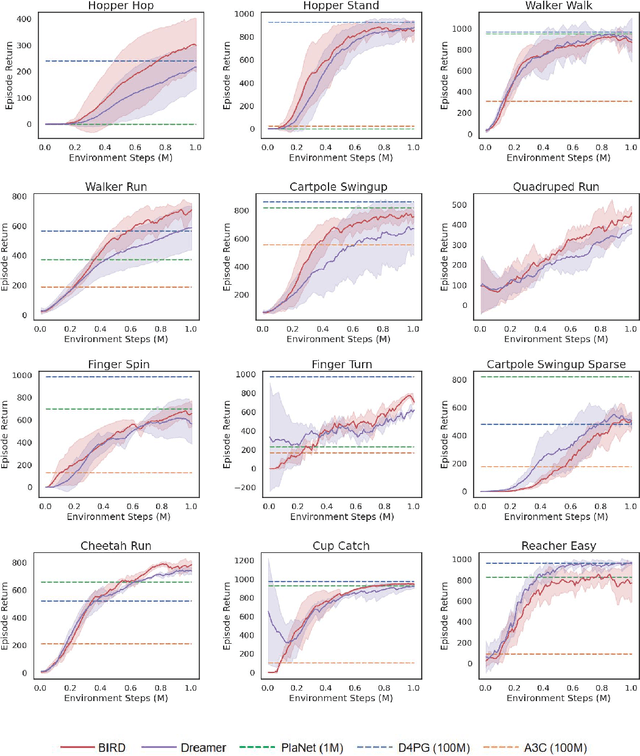
Sample efficiency has been one of the major challenges for deep reinforcement learning. Recently, model-based reinforcement learning has been proposed to address this challenge by performing planning on imaginary trajectories with a learned world model. However, world model learning may suffer from overfitting to training trajectories, and thus model-based value estimation and policy search will be pone to be sucked in an inferior local policy. In this paper, we propose a novel model-based reinforcement learning algorithm, called BrIdging Reality and Dream (BIRD). It maximizes the mutual information between imaginary and real trajectories so that the policy improvement learned from imaginary trajectories can be easily generalized to real trajectories. We demonstrate that our approach improves sample efficiency of model-based planning, and achieves state-of-the-art performance on challenging visual control benchmarks.