 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConcertoRL: An Innovative Time-Interleaved Reinforcement Learning Approach for Enhanced Control in Direct-Drive Tandem-Wing Vehicles
May 22, 2024



In control problems for insect-scale direct-drive experimental platforms under tandem wing influence, the primary challenge facing existing reinforcement learning models is their limited safety in the exploration process and the stability of the continuous training process. We introduce the ConcertoRL algorithm to enhance control precision and stabilize the online training process, which consists of two main innovations: a time-interleaved mechanism to interweave classical controllers with reinforcement learning-based controllers aiming to improve control precision in the initial stages, a policy composer organizes the experience gained from previous learning to ensure the stability of the online training process. This paper conducts a series of experiments. First, experiments incorporating the time-interleaved mechanism demonstrate a substantial performance boost of approximately 70% over scenarios without reinforcement learning enhancements and a 50% increase in efficiency compared to reference controllers with doubled control frequencies. These results highlight the algorithm's ability to create a synergistic effect that exceeds the sum of its parts.
A Novel Actuation Strategy for an Agile Bio-inspired FWAV Performing a Morphing-coupled Wingbeat Pattern
Nov 03, 2021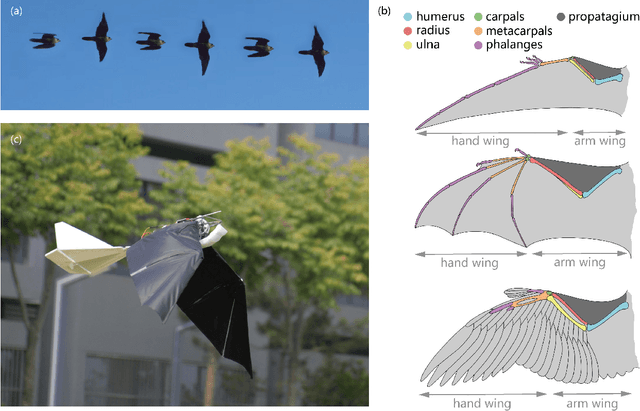

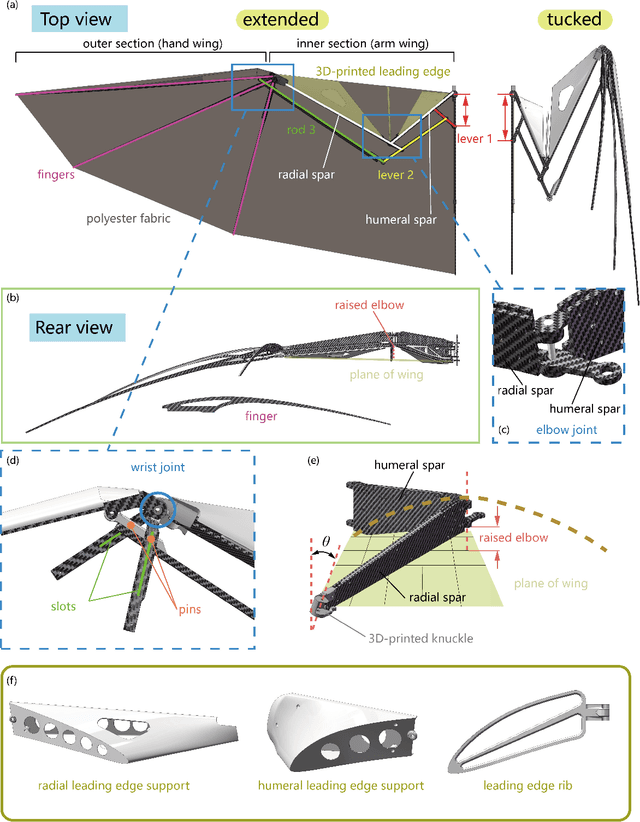
Flying vertebrates exhibit sophisticated wingbeat kinematics. Their specialized forelimbs allow for the wing morphing motion to couple with the flapping motion during their level flight, Previous flyable bionic platforms have successfully applied bio-inspired wing morphing but cannot yet be propelled by the morphing-coupled wingbeat pattern. Spurred by this, we develop a bio-inspired flapping-wing aerial vehicle (FWAV) entitled RoboFalcon, which is equipped with a novel mechanism to drive the bat-style morphing wings, performs a morphing-coupled wingbeat pattern, and overall manages an appealing flight. The novel mechanism of RoboFalcon allows coupling the morphing and flapping during level flight and decoupling these when maneuvering is required, producing a bilateral asymmetric downstroke affording high rolling agility. The bat-style morphing wing is designed with a tilted mounting angle around the radius at the wrist joint to mimic the wrist supination and pronation effect of flying vertebrates' forelimbs. The agility of RoboFalcon is assessed through several rolling maneuver flight tests, and we demonstrate its well-performing agility capability compared to flying creatures and current flapping-wing platforms. Wind tunnel tests indicate that the roll moment of the asymmetric downstroke is correlated with the flapping frequency, and the wrist mounting angle can be used for tuning the angle of attack and lift-thrust configuration of the equilibrium flight state. We believe that this work yields a well-performing bionic platform and provides a new actuation strategy for the morphing-coupled flapping flight.
Explainable Deep Reinforcement Learning for UAV Autonomous Navigation
Sep 30, 2020



Modern deep reinforcement learning plays an important role to solve a wide range of complex decision-making tasks. However, due to the use of deep neural networks, the trained models are lacking transparency which causes distrust from their user and hard to be used in the critical field such as self-driving car and unmanned aerial vehicles. In this paper, an explainable deep reinforcement learning method is proposed to deal with the multirotor obstacle avoidance and navigation problem. Both visual and textual explanation is provided to make the trained agent more transparency and comprehensible for humans. Our model can provide real-time decision explanation for non-expert users. Also, some global explanation results are provided for experts to diagnose the learned policy. Our method is validated in the simulation environment. The simulation result shows our proposed method can get useful explanations to increase the user's trust to the network and also improve the network performance.
Deep Reinforcement Learning based Local Planner for UAV Obstacle Avoidance using Demonstration Data
Aug 06, 2020



In this paper, a deep reinforcement learning (DRL) method is proposed to address the problem of UAV navigation in an unknown environment. However, DRL algorithms are limited by the data efficiency problem as they typically require a huge amount of data before they reach a reasonable performance. To speed up the DRL training process, we developed a novel learning framework which combines imitation learning and reinforcement learning and building upon Twin Delayed DDPG (TD3) algorithm. We newly introduced both policy and Q-value network are learned using the expert demonstration during the imitation phase. To tackle the distribution mismatch problem transfer from imitation to reinforcement learning, both TD-error and decayed imitation loss are used to update the pre-trained network when start interacting with the environment. The performances of the proposed algorithm are demonstrated on the challenging 3D UAV navigation problem using depth cameras and sketched in a variety of simulation environments.