 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTranslating Flow to Policy via Hindsight Online Imitation
Dec 22, 2025Recent advances in hierarchical robot systems leverage a high-level planner to propose task plans and a low-level policy to generate robot actions. This design allows training the planner on action-free or even non-robot data sources (e.g., videos), providing transferable high-level guidance. Nevertheless, grounding these high-level plans into executable actions remains challenging, especially with the limited availability of high-quality robot data. To this end, we propose to improve the low-level policy through online interactions. Specifically, our approach collects online rollouts, retrospectively annotates the corresponding high-level goals from achieved outcomes, and aggregates these hindsight-relabeled experiences to update a goal-conditioned imitation policy. Our method, Hindsight Flow-conditioned Online Imitation (HinFlow), instantiates this idea with 2D point flows as the high-level planner. Across diverse manipulation tasks in both simulation and physical world, our method achieves more than $2\times$ performance improvement over the base policy, significantly outperforming the existing methods. Moreover, our framework enables policy acquisition from planners trained on cross-embodiment video data, demonstrating its potential for scalable and transferable robot learning.
Enhancing Decision-Making of Large Language Models via Actor-Critic
Jun 04, 2025Large Language Models (LLMs) have achieved remarkable advancements in natural language processing tasks, yet they encounter challenges in complex decision-making scenarios that require long-term reasoning and alignment with high-level objectives. Existing methods either rely on short-term auto-regressive action generation or face limitations in accurately simulating rollouts and assessing outcomes, leading to sub-optimal decisions. This paper introduces a novel LLM-based Actor-Critic framework, termed LAC, that effectively improves LLM policies with long-term action evaluations in a principled and scalable way. Our approach addresses two key challenges: (1) extracting robust action evaluations by computing Q-values via token logits associated with positive/negative outcomes, enhanced by future trajectory rollouts and reasoning; and (2) enabling efficient policy improvement through a gradient-free mechanism. Experiments across diverse environments -- including high-level decision-making (ALFWorld), low-level action spaces (BabyAI-Text), and large action spaces (WebShop) -- demonstrate the framework's generality and superiority over state-of-the-art methods. Notably, our approach achieves competitive performance using 7B/8B parameter LLMs, even outperforming baseline methods employing GPT-4 in complex tasks. These results underscore the potential of integrating structured policy optimization with LLMs' intrinsic knowledge to advance decision-making capabilities in multi-step environments.
Revisiting Multi-Agent World Modeling from a Diffusion-Inspired Perspective
May 27, 2025



World models have recently attracted growing interest in Multi-Agent Reinforcement Learning (MARL) due to their ability to improve sample efficiency for policy learning. However, accurately modeling environments in MARL is challenging due to the exponentially large joint action space and highly uncertain dynamics inherent in multi-agent systems. To address this, we reduce modeling complexity by shifting from jointly modeling the entire state-action transition dynamics to focusing on the state space alone at each timestep through sequential agent modeling. Specifically, our approach enables the model to progressively resolve uncertainty while capturing the structured dependencies among agents, providing a more accurate representation of how agents influence the state. Interestingly, this sequential revelation of agents' actions in a multi-agent system aligns with the reverse process in diffusion models--a class of powerful generative models known for their expressiveness and training stability compared to autoregressive or latent variable models. Leveraging this insight, we develop a flexible and robust world model for MARL using diffusion models. Our method, Diffusion-Inspired Multi-Agent world model (DIMA), achieves state-of-the-art performance across multiple multi-agent control benchmarks, significantly outperforming prior world models in terms of final return and sample efficiency, including MAMuJoCo and Bi-DexHands. DIMA establishes a new paradigm for constructing multi-agent world models, advancing the frontier of MARL research.
Learning to Plan Before Answering: Self-Teaching LLMs to Learn Abstract Plans for Problem Solving
Apr 28, 2025In the field of large language model (LLM) post-training, the effectiveness of utilizing synthetic data generated by the LLM itself has been well-presented. However, a key question remains unaddressed: what essential information should such self-generated data encapsulate? Existing approaches only produce step-by-step problem solutions, and fail to capture the abstract meta-knowledge necessary for generalization across similar problems. Drawing insights from cognitive science, where humans employ high-level abstraction to simplify complex problems before delving into specifics, we introduce a novel self-training algorithm: LEarning to Plan before Answering (LEPA). LEPA trains the LLM to formulate anticipatory plans, which serve as abstract meta-knowledge for problem-solving, before engaging with the intricacies of problems. This approach not only outlines the solution generation path but also shields the LLM from the distraction of irrelevant details. During data generation, LEPA first crafts an anticipatory plan based on the problem, and then generates a solution that aligns with both the plan and the problem. LEPA refines the plan through self-reflection, aiming to acquire plans that are instrumental in yielding correct solutions. During model optimization, the LLM is trained to predict both the refined plans and the corresponding solutions. By efficiently extracting and utilizing the anticipatory plans, LEPA demonstrates remarkable superiority over conventional algorithms on various challenging natural language reasoning benchmarks.
Fewer May Be Better: Enhancing Offline Reinforcement Learning with Reduced Dataset
Feb 26, 2025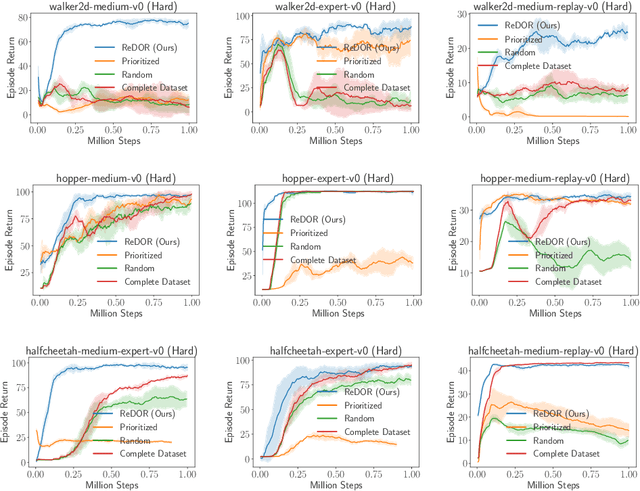
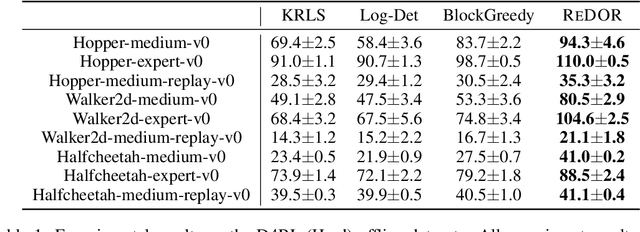

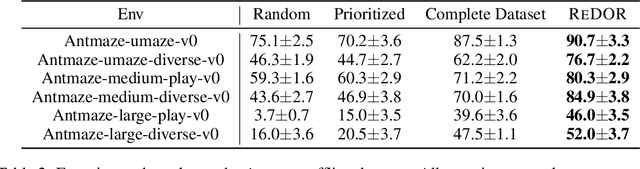
Offline reinforcement learning (RL) represents a significant shift in RL research, allowing agents to learn from pre-collected datasets without further interaction with the environment. A key, yet underexplored, challenge in offline RL is selecting an optimal subset of the offline dataset that enhances both algorithm performance and training efficiency. Reducing dataset size can also reveal the minimal data requirements necessary for solving similar problems. In response to this challenge, we introduce ReDOR (Reduced Datasets for Offline RL), a method that frames dataset selection as a gradient approximation optimization problem. We demonstrate that the widely used actor-critic framework in RL can be reformulated as a submodular optimization objective, enabling efficient subset selection. To achieve this, we adapt orthogonal matching pursuit (OMP), incorporating several novel modifications tailored for offline RL. Our experimental results show that the data subsets identified by ReDOR not only boost algorithm performance but also do so with significantly lower computational complexity.
Episodic Novelty Through Temporal Distance
Jan 26, 2025Exploration in sparse reward environments remains a significant challenge in reinforcement learning, particularly in Contextual Markov Decision Processes (CMDPs), where environments differ across episodes. Existing episodic intrinsic motivation methods for CMDPs primarily rely on count-based approaches, which are ineffective in large state spaces, or on similarity-based methods that lack appropriate metrics for state comparison. To address these shortcomings, we propose Episodic Novelty Through Temporal Distance (ETD), a novel approach that introduces temporal distance as a robust metric for state similarity and intrinsic reward computation. By employing contrastive learning, ETD accurately estimates temporal distances and derives intrinsic rewards based on the novelty of states within the current episode. Extensive experiments on various benchmark tasks demonstrate that ETD significantly outperforms state-of-the-art methods, highlighting its effectiveness in enhancing exploration in sparse reward CMDPs.
GOMAA-Geo: GOal Modality Agnostic Active Geo-localization
Jun 04, 2024



We consider the task of active geo-localization (AGL) in which an agent uses a sequence of visual cues observed during aerial navigation to find a target specified through multiple possible modalities. This could emulate a UAV involved in a search-and-rescue operation navigating through an area, observing a stream of aerial images as it goes. The AGL task is associated with two important challenges. Firstly, an agent must deal with a goal specification in one of multiple modalities (e.g., through a natural language description) while the search cues are provided in other modalities (aerial imagery). The second challenge is limited localization time (e.g., limited battery life, urgency) so that the goal must be localized as efficiently as possible, i.e. the agent must effectively leverage its sequentially observed aerial views when searching for the goal. To address these challenges, we propose GOMAA-Geo - a goal modality agnostic active geo-localization agent - for zero-shot generalization between different goal modalities. Our approach combines cross-modality contrastive learning to align representations across modalities with supervised foundation model pretraining and reinforcement learning to obtain highly effective navigation and localization policies. Through extensive evaluations, we show that GOMAA-Geo outperforms alternative learnable approaches and that it generalizes across datasets - e.g., to disaster-hit areas without seeing a single disaster scenario during training - and goal modalities - e.g., to ground-level imagery or textual descriptions, despite only being trained with goals specified as aerial views. Code and models are publicly available at https://github.com/mvrl/GOMAA-Geo/tree/main.
Bayesian Design Principles for Offline-to-Online Reinforcement Learning
May 31, 2024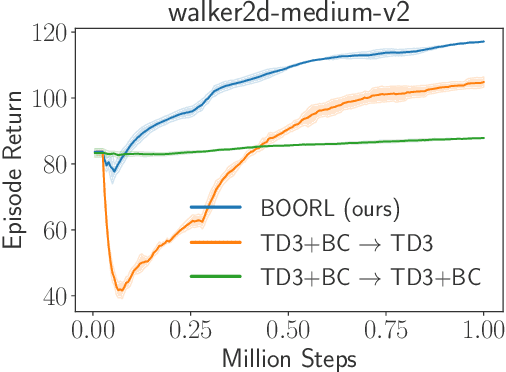

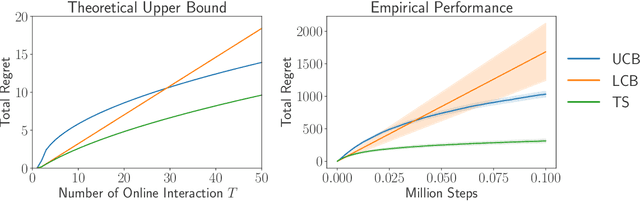

Offline reinforcement learning (RL) is crucial for real-world applications where exploration can be costly or unsafe. However, offline learned policies are often suboptimal, and further online fine-tuning is required. In this paper, we tackle the fundamental dilemma of offline-to-online fine-tuning: if the agent remains pessimistic, it may fail to learn a better policy, while if it becomes optimistic directly, performance may suffer from a sudden drop. We show that Bayesian design principles are crucial in solving such a dilemma. Instead of adopting optimistic or pessimistic policies, the agent should act in a way that matches its belief in optimal policies. Such a probability-matching agent can avoid a sudden performance drop while still being guaranteed to find the optimal policy. Based on our theoretical findings, we introduce a novel algorithm that outperforms existing methods on various benchmarks, demonstrating the efficacy of our approach. Overall, the proposed approach provides a new perspective on offline-to-online RL that has the potential to enable more effective learning from offline data.
Efficient Multi-agent Reinforcement Learning by Planning
May 20, 2024



Multi-agent reinforcement learning (MARL) algorithms have accomplished remarkable breakthroughs in solving large-scale decision-making tasks. Nonetheless, most existing MARL algorithms are model-free, limiting sample efficiency and hindering their applicability in more challenging scenarios. In contrast, model-based reinforcement learning (MBRL), particularly algorithms integrating planning, such as MuZero, has demonstrated superhuman performance with limited data in many tasks. Hence, we aim to boost the sample efficiency of MARL by adopting model-based approaches. However, incorporating planning and search methods into multi-agent systems poses significant challenges. The expansive action space of multi-agent systems often necessitates leveraging the nearly-independent property of agents to accelerate learning. To tackle this issue, we propose the MAZero algorithm, which combines a centralized model with Monte Carlo Tree Search (MCTS) for policy search. We design a novel network structure to facilitate distributed execution and parameter sharing. To enhance search efficiency in deterministic environments with sizable action spaces, we introduce two novel techniques: Optimistic Search Lambda (OS($\lambda$)) and Advantage-Weighted Policy Optimization (AWPO). Extensive experiments on the SMAC benchmark demonstrate that MAZero outperforms model-free approaches in terms of sample efficiency and provides comparable or better performance than existing model-based methods in terms of both sample and computational efficiency. Our code is available at https://github.com/liuqh16/MAZero.
Learning Interpretable Policies in Hindsight-Observable POMDPs through Partially Supervised Reinforcement Learning
Feb 14, 2024



Deep reinforcement learning has demonstrated remarkable achievements across diverse domains such as video games, robotic control, autonomous driving, and drug discovery. Common methodologies in partially-observable domains largely lean on end-to-end learning from high-dimensional observations, such as images, without explicitly reasoning about true state. We suggest an alternative direction, introducing the Partially Supervised Reinforcement Learning (PSRL) framework. At the heart of PSRL is the fusion of both supervised and unsupervised learning. The approach leverages a state estimator to distill supervised semantic state information from high-dimensional observations which are often fully observable at training time. This yields more interpretable policies that compose state predictions with control. In parallel, it captures an unsupervised latent representation. These two-the semantic state and the latent state-are then fused and utilized as inputs to a policy network. This juxtaposition offers practitioners a flexible and dynamic spectrum: from emphasizing supervised state information to integrating richer, latent insights. Extensive experimental results indicate that by merging these dual representations, PSRL offers a potent balance, enhancing model interpretability while preserving, and often significantly outperforming, the performance benchmarks set by traditional methods in terms of reward and convergence speed.