 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFewer May Be Better: Enhancing Offline Reinforcement Learning with Reduced Dataset
Feb 26, 2025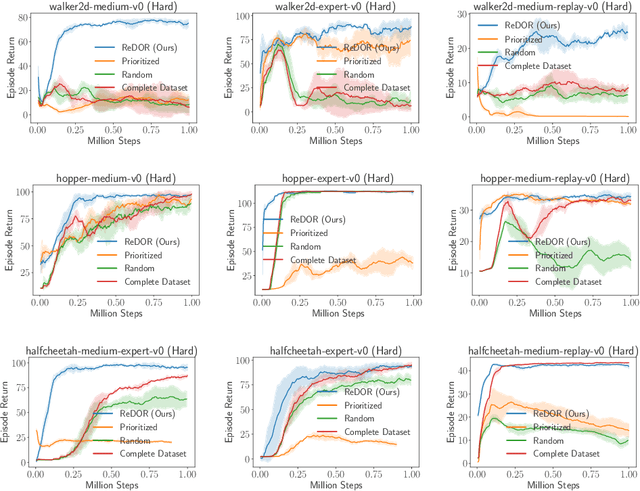
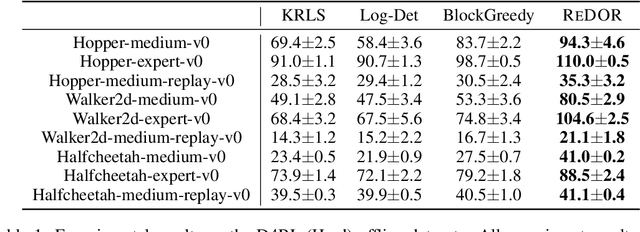

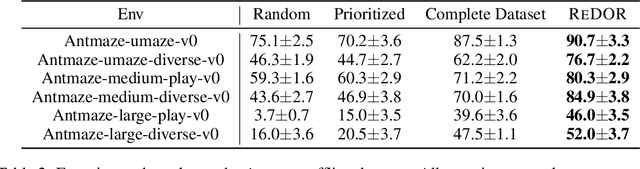
Offline reinforcement learning (RL) represents a significant shift in RL research, allowing agents to learn from pre-collected datasets without further interaction with the environment. A key, yet underexplored, challenge in offline RL is selecting an optimal subset of the offline dataset that enhances both algorithm performance and training efficiency. Reducing dataset size can also reveal the minimal data requirements necessary for solving similar problems. In response to this challenge, we introduce ReDOR (Reduced Datasets for Offline RL), a method that frames dataset selection as a gradient approximation optimization problem. We demonstrate that the widely used actor-critic framework in RL can be reformulated as a submodular optimization objective, enabling efficient subset selection. To achieve this, we adapt orthogonal matching pursuit (OMP), incorporating several novel modifications tailored for offline RL. Our experimental results show that the data subsets identified by ReDOR not only boost algorithm performance but also do so with significantly lower computational complexity.
Episodic Novelty Through Temporal Distance
Jan 26, 2025Exploration in sparse reward environments remains a significant challenge in reinforcement learning, particularly in Contextual Markov Decision Processes (CMDPs), where environments differ across episodes. Existing episodic intrinsic motivation methods for CMDPs primarily rely on count-based approaches, which are ineffective in large state spaces, or on similarity-based methods that lack appropriate metrics for state comparison. To address these shortcomings, we propose Episodic Novelty Through Temporal Distance (ETD), a novel approach that introduces temporal distance as a robust metric for state similarity and intrinsic reward computation. By employing contrastive learning, ETD accurately estimates temporal distances and derives intrinsic rewards based on the novelty of states within the current episode. Extensive experiments on various benchmark tasks demonstrate that ETD significantly outperforms state-of-the-art methods, highlighting its effectiveness in enhancing exploration in sparse reward CMDPs.
No Prior Mask: Eliminate Redundant Action for Deep Reinforcement Learning
Dec 11, 2023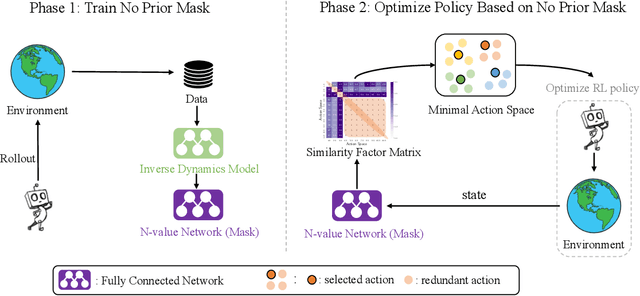
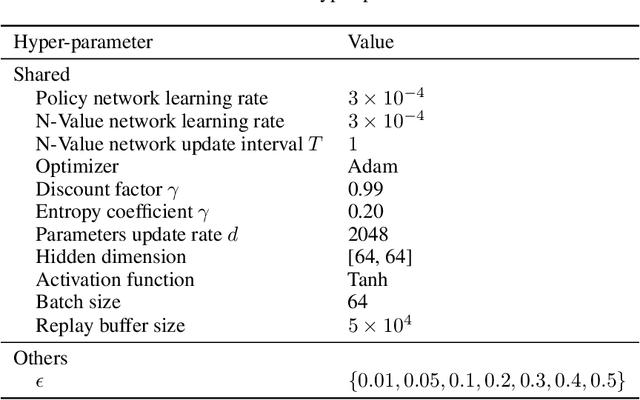
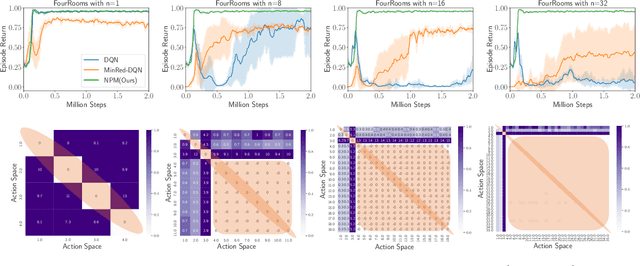
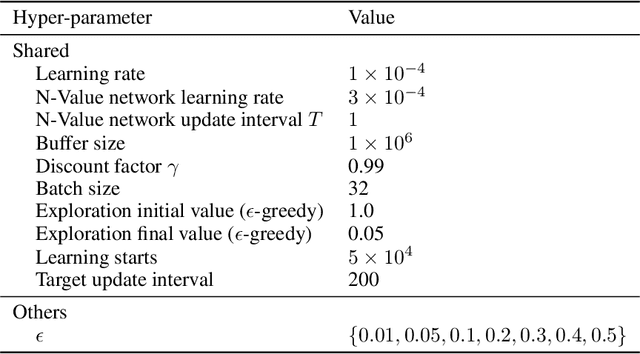
The large action space is one fundamental obstacle to deploying Reinforcement Learning methods in the real world. The numerous redundant actions will cause the agents to make repeated or invalid attempts, even leading to task failure. Although current algorithms conduct some initial explorations for this issue, they either suffer from rule-based systems or depend on expert demonstrations, which significantly limits their applicability in many real-world settings. In this work, we examine the theoretical analysis of what action can be eliminated in policy optimization and propose a novel redundant action filtering mechanism. Unlike other works, our method constructs the similarity factor by estimating the distance between the state distributions, which requires no prior knowledge. In addition, we combine the modified inverse model to avoid extensive computation in high-dimensional state space. We reveal the underlying structure of action spaces and propose a simple yet efficient redundant action filtering mechanism named No Prior Mask (NPM) based on the above techniques. We show the superior performance of our method by conducting extensive experiments on high-dimensional, pixel-input, and stochastic problems with various action redundancy. Our code is public online at https://github.com/zhongdy15/npm.