 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEpisodic Novelty Through Temporal Distance
Jan 26, 2025Exploration in sparse reward environments remains a significant challenge in reinforcement learning, particularly in Contextual Markov Decision Processes (CMDPs), where environments differ across episodes. Existing episodic intrinsic motivation methods for CMDPs primarily rely on count-based approaches, which are ineffective in large state spaces, or on similarity-based methods that lack appropriate metrics for state comparison. To address these shortcomings, we propose Episodic Novelty Through Temporal Distance (ETD), a novel approach that introduces temporal distance as a robust metric for state similarity and intrinsic reward computation. By employing contrastive learning, ETD accurately estimates temporal distances and derives intrinsic rewards based on the novelty of states within the current episode. Extensive experiments on various benchmark tasks demonstrate that ETD significantly outperforms state-of-the-art methods, highlighting its effectiveness in enhancing exploration in sparse reward CMDPs.
Efficient Multi-agent Reinforcement Learning by Planning
May 20, 2024



Multi-agent reinforcement learning (MARL) algorithms have accomplished remarkable breakthroughs in solving large-scale decision-making tasks. Nonetheless, most existing MARL algorithms are model-free, limiting sample efficiency and hindering their applicability in more challenging scenarios. In contrast, model-based reinforcement learning (MBRL), particularly algorithms integrating planning, such as MuZero, has demonstrated superhuman performance with limited data in many tasks. Hence, we aim to boost the sample efficiency of MARL by adopting model-based approaches. However, incorporating planning and search methods into multi-agent systems poses significant challenges. The expansive action space of multi-agent systems often necessitates leveraging the nearly-independent property of agents to accelerate learning. To tackle this issue, we propose the MAZero algorithm, which combines a centralized model with Monte Carlo Tree Search (MCTS) for policy search. We design a novel network structure to facilitate distributed execution and parameter sharing. To enhance search efficiency in deterministic environments with sizable action spaces, we introduce two novel techniques: Optimistic Search Lambda (OS($\lambda$)) and Advantage-Weighted Policy Optimization (AWPO). Extensive experiments on the SMAC benchmark demonstrate that MAZero outperforms model-free approaches in terms of sample efficiency and provides comparable or better performance than existing model-based methods in terms of both sample and computational efficiency. Our code is available at https://github.com/liuqh16/MAZero.
Learning Diverse Risk Preferences in Population-based Self-play
May 19, 2023



Among the great successes of Reinforcement Learning (RL), self-play algorithms play an essential role in solving competitive games. Current self-play algorithms optimize the agent to maximize expected win-rates against its current or historical copies, making it often stuck in the local optimum and its strategy style simple and homogeneous. A possible solution is to improve the diversity of policies, which helps the agent break the stalemate and enhances its robustness when facing different opponents. However, enhancing diversity in the self-play algorithms is not trivial. In this paper, we aim to introduce diversity from the perspective that agents could have diverse risk preferences in the face of uncertainty. Specifically, we design a novel reinforcement learning algorithm called Risk-sensitive Proximal Policy Optimization (RPPO), which smoothly interpolates between worst-case and best-case policy learning and allows for policy learning with desired risk preferences. Seamlessly integrating RPPO with population-based self-play, agents in the population optimize dynamic risk-sensitive objectives with experiences from playing against diverse opponents. Empirical results show that our method achieves comparable or superior performance in competitive games and that diverse modes of behaviors emerge. Our code is public online at \url{https://github.com/Jackory/RPBT}.
Offline Reinforcement Learning with Value-based Episodic Memory
Oct 19, 2021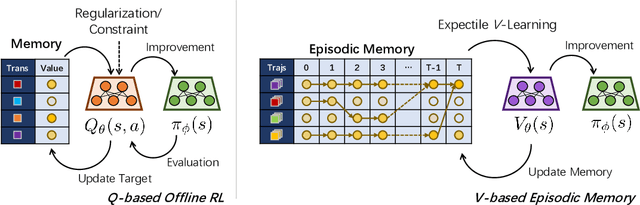
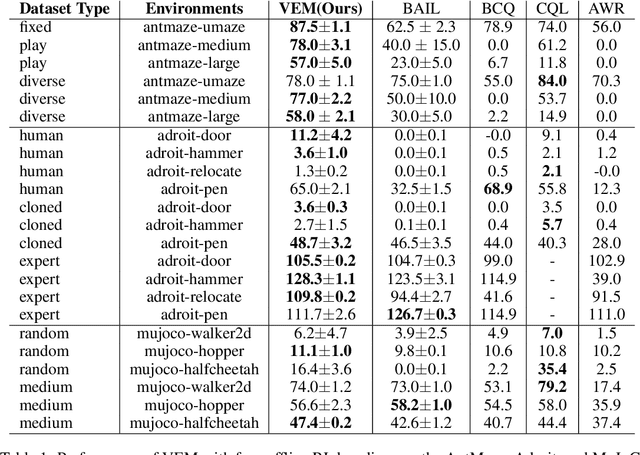
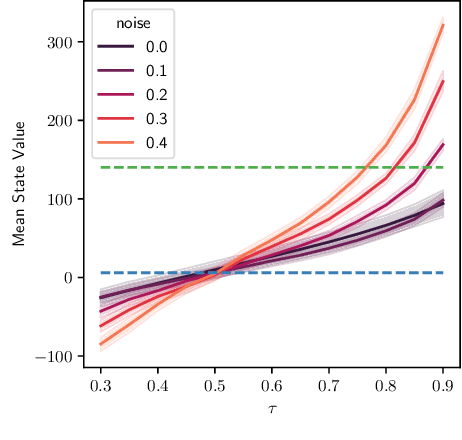
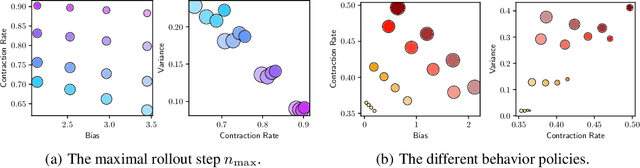
Offline reinforcement learning (RL) shows promise of applying RL to real-world problems by effectively utilizing previously collected data. Most existing offline RL algorithms use regularization or constraints to suppress extrapolation error for actions outside the dataset. In this paper, we adopt a different framework, which learns the V-function instead of the Q-function to naturally keep the learning procedure within the support of an offline dataset. To enable effective generalization while maintaining proper conservatism in offline learning, we propose Expectile V-Learning (EVL), which smoothly interpolates between the optimal value learning and behavior cloning. Further, we introduce implicit planning along offline trajectories to enhance learned V-values and accelerate convergence. Together, we present a new offline method called Value-based Episodic Memory (VEM). We provide theoretical analysis for the convergence properties of our proposed VEM method, and empirical results in the D4RL benchmark show that our method achieves superior performance in most tasks, particularly in sparse-reward tasks.