 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobeDiff: State Diffusion Process for Partial Observability in Multi-Agent Systems
Feb 17, 2026In the realm of multi-agent systems, the challenge of \emph{partial observability} is a critical barrier to effective coordination and decision-making. Existing approaches, such as belief state estimation and inter-agent communication, often fall short. Belief-based methods are limited by their focus on past experiences without fully leveraging global information, while communication methods often lack a robust model to effectively utilize the auxiliary information they provide. To solve this issue, we propose Global State Diffusion Algorithm~(GlobeDiff) to infer the global state based on the local observations. By formulating the state inference process as a multi-modal diffusion process, GlobeDiff overcomes ambiguities in state estimation while simultaneously inferring the global state with high fidelity. We prove that the estimation error of GlobeDiff under both unimodal and multi-modal distributions can be bounded. Extensive experimental results demonstrate that GlobeDiff achieves superior performance and is capable of accurately inferring the global state.
MrCoM: A Meta-Regularized World-Model Generalizing Across Multi-Scenarios
Nov 09, 2025Model-based reinforcement learning (MBRL) is a crucial approach to enhance the generalization capabilities and improve the sample efficiency of RL algorithms. However, current MBRL methods focus primarily on building world models for single tasks and rarely address generalization across different scenarios. Building on the insight that dynamics within the same simulation engine share inherent properties, we attempt to construct a unified world model capable of generalizing across different scenarios, named Meta-Regularized Contextual World-Model (MrCoM). This method first decomposes the latent state space into various components based on the dynamic characteristics, thereby enhancing the accuracy of world-model prediction. Further, MrCoM adopts meta-state regularization to extract unified representation of scenario-relevant information, and meta-value regularization to align world-model optimization with policy learning across diverse scenario objectives. We theoretically analyze the generalization error upper bound of MrCoM in multi-scenario settings. We systematically evaluate our algorithm's generalization ability across diverse scenarios, demonstrating significantly better performance than previous state-of-the-art methods.
SC2Arena and StarEvolve: Benchmark and Self-Improvement Framework for LLMs in Complex Decision-Making Tasks
Aug 14, 2025Evaluating large language models (LLMs) in complex decision-making is essential for advancing AI's ability for strategic planning and real-time adaptation. However, existing benchmarks for tasks like StarCraft II fail to capture the game's full complexity, such as its complete game context, diverse action spaces, and all playable races. To address this gap, we present SC2Arena, a benchmark that fully supports all playable races, low-level action spaces, and optimizes text-based observations to tackle spatial reasoning challenges. Complementing this, we introduce StarEvolve, a hierarchical framework that integrates strategic planning with tactical execution, featuring iterative self-correction and continuous improvement via fine-tuning on high-quality gameplay data. Its key components include a Planner-Executor-Verifier structure to break down gameplay, and a scoring system for selecting high-quality training samples. Comprehensive analysis using SC2Arena provides valuable insights into developing generalist agents that were not possible with previous benchmarks. Experimental results also demonstrate that our proposed StarEvolve achieves superior performance in strategic planning. Our code, environment, and algorithms are publicly available.
DPMT: Dual Process Multi-scale Theory of Mind Framework for Real-time Human-AI Collaboration
Jul 18, 2025Real-time human-artificial intelligence (AI) collaboration is crucial yet challenging, especially when AI agents must adapt to diverse and unseen human behaviors in dynamic scenarios. Existing large language model (LLM) agents often fail to accurately model the complex human mental characteristics such as domain intentions, especially in the absence of direct communication. To address this limitation, we propose a novel dual process multi-scale theory of mind (DPMT) framework, drawing inspiration from cognitive science dual process theory. Our DPMT framework incorporates a multi-scale theory of mind (ToM) module to facilitate robust human partner modeling through mental characteristic reasoning. Experimental results demonstrate that DPMT significantly enhances human-AI collaboration, and ablation studies further validate the contributions of our multi-scale ToM in the slow system.
Fewer May Be Better: Enhancing Offline Reinforcement Learning with Reduced Dataset
Feb 26, 2025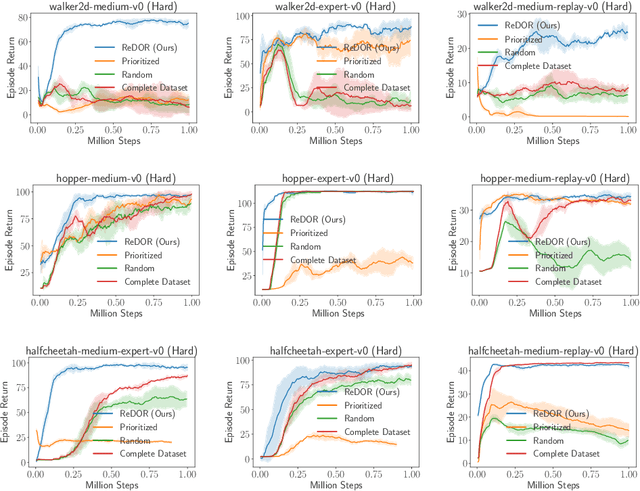
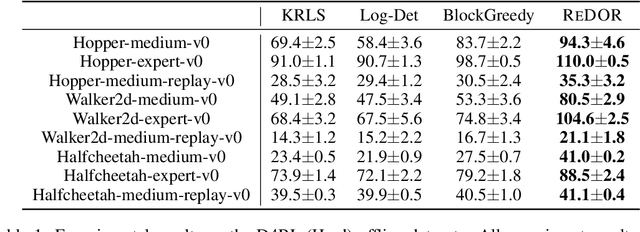

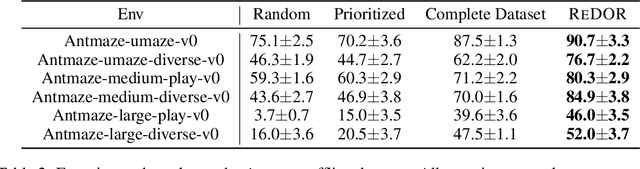
Offline reinforcement learning (RL) represents a significant shift in RL research, allowing agents to learn from pre-collected datasets without further interaction with the environment. A key, yet underexplored, challenge in offline RL is selecting an optimal subset of the offline dataset that enhances both algorithm performance and training efficiency. Reducing dataset size can also reveal the minimal data requirements necessary for solving similar problems. In response to this challenge, we introduce ReDOR (Reduced Datasets for Offline RL), a method that frames dataset selection as a gradient approximation optimization problem. We demonstrate that the widely used actor-critic framework in RL can be reformulated as a submodular optimization objective, enabling efficient subset selection. To achieve this, we adapt orthogonal matching pursuit (OMP), incorporating several novel modifications tailored for offline RL. Our experimental results show that the data subsets identified by ReDOR not only boost algorithm performance but also do so with significantly lower computational complexity.
Episodic Novelty Through Temporal Distance
Jan 26, 2025Exploration in sparse reward environments remains a significant challenge in reinforcement learning, particularly in Contextual Markov Decision Processes (CMDPs), where environments differ across episodes. Existing episodic intrinsic motivation methods for CMDPs primarily rely on count-based approaches, which are ineffective in large state spaces, or on similarity-based methods that lack appropriate metrics for state comparison. To address these shortcomings, we propose Episodic Novelty Through Temporal Distance (ETD), a novel approach that introduces temporal distance as a robust metric for state similarity and intrinsic reward computation. By employing contrastive learning, ETD accurately estimates temporal distances and derives intrinsic rewards based on the novelty of states within the current episode. Extensive experiments on various benchmark tasks demonstrate that ETD significantly outperforms state-of-the-art methods, highlighting its effectiveness in enhancing exploration in sparse reward CMDPs.
S-EPOA: Overcoming the Indivisibility of Annotations with Skill-Driven Preference-Based Reinforcement Learning
Aug 22, 2024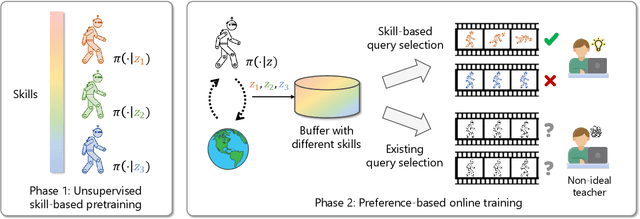
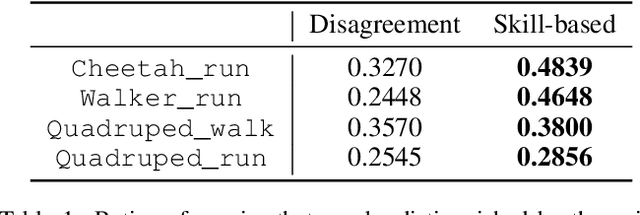
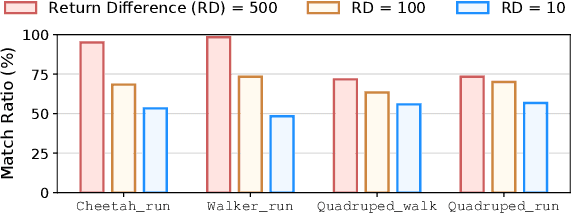

Preference-based reinforcement learning (PbRL) stands out by utilizing human preferences as a direct reward signal, eliminating the need for intricate reward engineering. However, despite its potential, traditional PbRL methods are often constrained by the indivisibility of annotations, which impedes the learning process. In this paper, we introduce a groundbreaking approach, Skill-Enhanced Preference Optimization Algorithm~(S-EPOA), which addresses the annotation indivisibility issue by integrating skill mechanisms into the preference learning framework. Specifically, we first conduct the unsupervised pretraining to learn useful skills. Then, we propose a novel query selection mechanism to balance the information gain and discriminability over the learned skill space. Experimental results on a range of tasks, including robotic manipulation and locomotion, demonstrate that S-EPOA significantly outperforms conventional PbRL methods in terms of both robustness and learning efficiency. The results highlight the effectiveness of skill-driven learning in overcoming the challenges posed by annotation indivisibility.
Bayesian Design Principles for Offline-to-Online Reinforcement Learning
May 31, 2024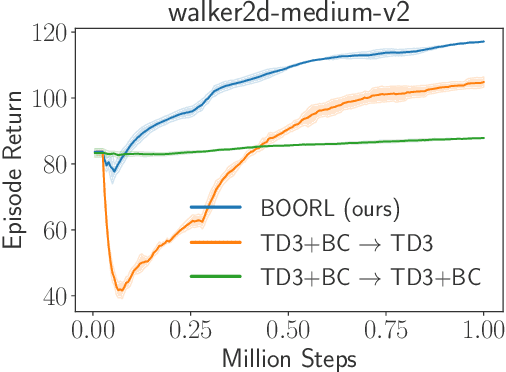

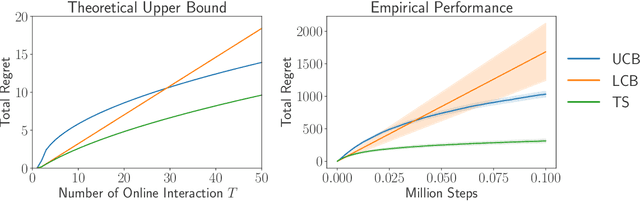

Offline reinforcement learning (RL) is crucial for real-world applications where exploration can be costly or unsafe. However, offline learned policies are often suboptimal, and further online fine-tuning is required. In this paper, we tackle the fundamental dilemma of offline-to-online fine-tuning: if the agent remains pessimistic, it may fail to learn a better policy, while if it becomes optimistic directly, performance may suffer from a sudden drop. We show that Bayesian design principles are crucial in solving such a dilemma. Instead of adopting optimistic or pessimistic policies, the agent should act in a way that matches its belief in optimal policies. Such a probability-matching agent can avoid a sudden performance drop while still being guaranteed to find the optimal policy. Based on our theoretical findings, we introduce a novel algorithm that outperforms existing methods on various benchmarks, demonstrating the efficacy of our approach. Overall, the proposed approach provides a new perspective on offline-to-online RL that has the potential to enable more effective learning from offline data.
No Prior Mask: Eliminate Redundant Action for Deep Reinforcement Learning
Dec 11, 2023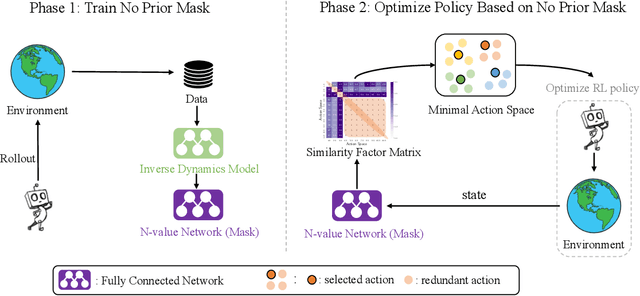
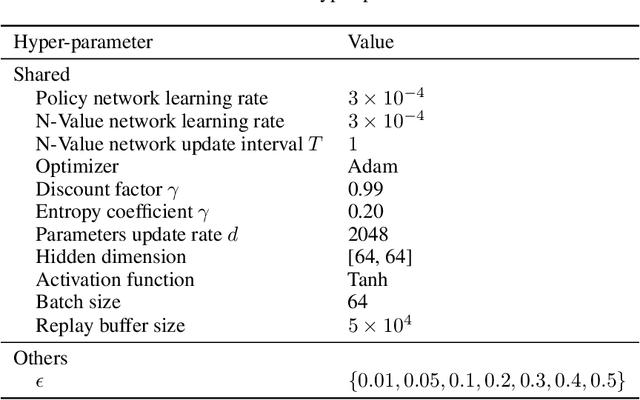
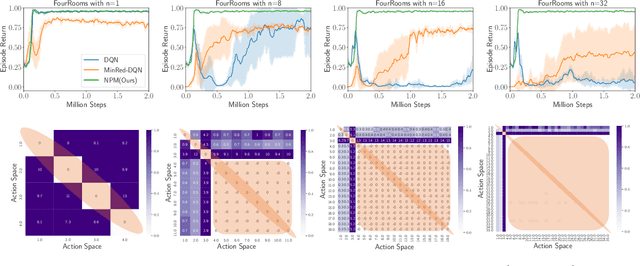
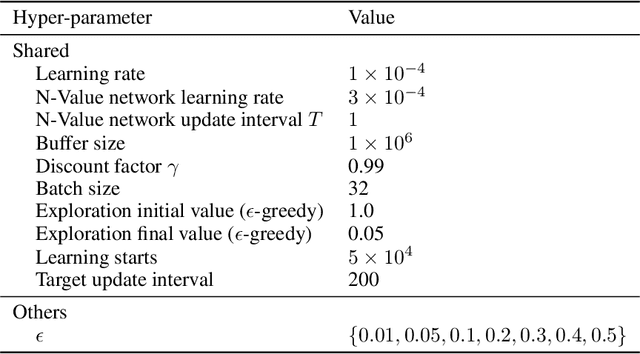
The large action space is one fundamental obstacle to deploying Reinforcement Learning methods in the real world. The numerous redundant actions will cause the agents to make repeated or invalid attempts, even leading to task failure. Although current algorithms conduct some initial explorations for this issue, they either suffer from rule-based systems or depend on expert demonstrations, which significantly limits their applicability in many real-world settings. In this work, we examine the theoretical analysis of what action can be eliminated in policy optimization and propose a novel redundant action filtering mechanism. Unlike other works, our method constructs the similarity factor by estimating the distance between the state distributions, which requires no prior knowledge. In addition, we combine the modified inverse model to avoid extensive computation in high-dimensional state space. We reveal the underlying structure of action spaces and propose a simple yet efficient redundant action filtering mechanism named No Prior Mask (NPM) based on the above techniques. We show the superior performance of our method by conducting extensive experiments on high-dimensional, pixel-input, and stochastic problems with various action redundancy. Our code is public online at https://github.com/zhongdy15/npm.
Unsupervised Behavior Extraction via Random Intent Priors
Oct 28, 2023Reward-free data is abundant and contains rich prior knowledge of human behaviors, but it is not well exploited by offline reinforcement learning (RL) algorithms. In this paper, we propose UBER, an unsupervised approach to extract useful behaviors from offline reward-free datasets via diversified rewards. UBER assigns different pseudo-rewards sampled from a given prior distribution to different agents to extract a diverse set of behaviors, and reuse them as candidate policies to facilitate the learning of new tasks. Perhaps surprisingly, we show that rewards generated from random neural networks are sufficient to extract diverse and useful behaviors, some even close to expert ones. We provide both empirical and theoretical evidence to justify the use of random priors for the reward function. Experiments on multiple benchmarks showcase UBER's ability to learn effective and diverse behavior sets that enhance sample efficiency for online RL, outperforming existing baselines. By reducing reliance on human supervision, UBER broadens the applicability of RL to real-world scenarios with abundant reward-free data.