 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOLLIE: Guiding Skill Discovery in Semantically Coherent Latent Space
May 31, 2026Unsupervised skill discovery (USD) aims to learn diverse behaviors without reward functions, but often results in task-irrelevant or hazardous behaviors due to uniform exploration. Guided skill discovery (GSD) addresses this issue by incorporating human intent to focus exploration on meaningful regions. However, existing GSD methods typically require training additional guidance models, and rely on pre-defined rules or expert demonstration, which can be ineffective under sparse, online-collected human feedback. To overcome this, we propose COLLIE, a GSD framework that leverages dense unsupervised data to construct a semantically coherent skill latent space. This latent space is well-structured, enabling reliable guidance with sparse online feedback. Moreover, its semantic coherence property enables training-free construction of guidance signals, eliminating the need for additional model training beyond skill learning. Theoretical analysis justifies the effectiveness of our training-free guidance signal, while experiments across diverse state-based and pixel-based tasks show that COLLIE learns diverse, human-aligned skills, avoids hazardous behaviors, and achieves superior downstream performance with minimal human feedback.
GlobeDiff: State Diffusion Process for Partial Observability in Multi-Agent Systems
Feb 17, 2026In the realm of multi-agent systems, the challenge of \emph{partial observability} is a critical barrier to effective coordination and decision-making. Existing approaches, such as belief state estimation and inter-agent communication, often fall short. Belief-based methods are limited by their focus on past experiences without fully leveraging global information, while communication methods often lack a robust model to effectively utilize the auxiliary information they provide. To solve this issue, we propose Global State Diffusion Algorithm~(GlobeDiff) to infer the global state based on the local observations. By formulating the state inference process as a multi-modal diffusion process, GlobeDiff overcomes ambiguities in state estimation while simultaneously inferring the global state with high fidelity. We prove that the estimation error of GlobeDiff under both unimodal and multi-modal distributions can be bounded. Extensive experimental results demonstrate that GlobeDiff achieves superior performance and is capable of accurately inferring the global state.
MrCoM: A Meta-Regularized World-Model Generalizing Across Multi-Scenarios
Nov 09, 2025Model-based reinforcement learning (MBRL) is a crucial approach to enhance the generalization capabilities and improve the sample efficiency of RL algorithms. However, current MBRL methods focus primarily on building world models for single tasks and rarely address generalization across different scenarios. Building on the insight that dynamics within the same simulation engine share inherent properties, we attempt to construct a unified world model capable of generalizing across different scenarios, named Meta-Regularized Contextual World-Model (MrCoM). This method first decomposes the latent state space into various components based on the dynamic characteristics, thereby enhancing the accuracy of world-model prediction. Further, MrCoM adopts meta-state regularization to extract unified representation of scenario-relevant information, and meta-value regularization to align world-model optimization with policy learning across diverse scenario objectives. We theoretically analyze the generalization error upper bound of MrCoM in multi-scenario settings. We systematically evaluate our algorithm's generalization ability across diverse scenarios, demonstrating significantly better performance than previous state-of-the-art methods.
SC2Arena and StarEvolve: Benchmark and Self-Improvement Framework for LLMs in Complex Decision-Making Tasks
Aug 14, 2025Evaluating large language models (LLMs) in complex decision-making is essential for advancing AI's ability for strategic planning and real-time adaptation. However, existing benchmarks for tasks like StarCraft II fail to capture the game's full complexity, such as its complete game context, diverse action spaces, and all playable races. To address this gap, we present SC2Arena, a benchmark that fully supports all playable races, low-level action spaces, and optimizes text-based observations to tackle spatial reasoning challenges. Complementing this, we introduce StarEvolve, a hierarchical framework that integrates strategic planning with tactical execution, featuring iterative self-correction and continuous improvement via fine-tuning on high-quality gameplay data. Its key components include a Planner-Executor-Verifier structure to break down gameplay, and a scoring system for selecting high-quality training samples. Comprehensive analysis using SC2Arena provides valuable insights into developing generalist agents that were not possible with previous benchmarks. Experimental results also demonstrate that our proposed StarEvolve achieves superior performance in strategic planning. Our code, environment, and algorithms are publicly available.
Preference-based Multi-Objective Reinforcement Learning
Jul 18, 2025Multi-objective reinforcement learning (MORL) is a structured approach for optimizing tasks with multiple objectives. However, it often relies on pre-defined reward functions, which can be hard to design for balancing conflicting goals and may lead to oversimplification. Preferences can serve as more flexible and intuitive decision-making guidance, eliminating the need for complicated reward design. This paper introduces preference-based MORL (Pb-MORL), which formalizes the integration of preferences into the MORL framework. We theoretically prove that preferences can derive policies across the entire Pareto frontier. To guide policy optimization using preferences, our method constructs a multi-objective reward model that aligns with the given preferences. We further provide theoretical proof to show that optimizing this reward model is equivalent to training the Pareto optimal policy. Extensive experiments in benchmark multi-objective tasks, a multi-energy management task, and an autonomous driving task on a multi-line highway show that our method performs competitively, surpassing the oracle method, which uses the ground truth reward function. This highlights its potential for practical applications in complex real-world systems.
S-EPOA: Overcoming the Indivisibility of Annotations with Skill-Driven Preference-Based Reinforcement Learning
Aug 22, 2024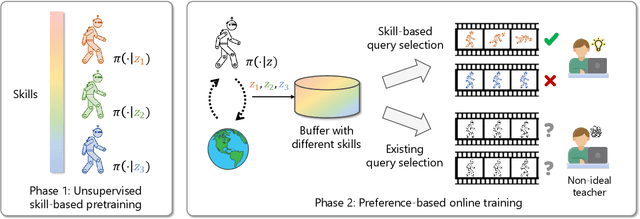
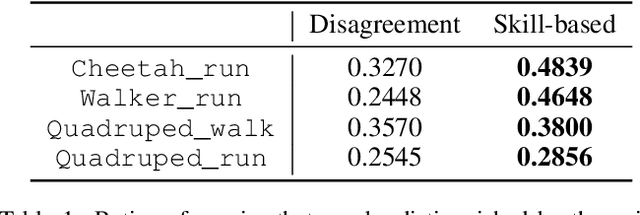
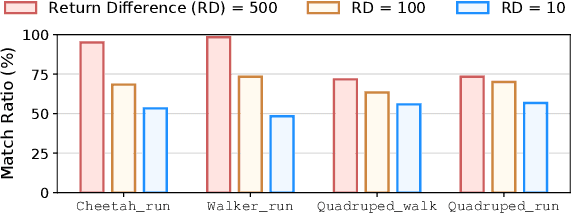

Preference-based reinforcement learning (PbRL) stands out by utilizing human preferences as a direct reward signal, eliminating the need for intricate reward engineering. However, despite its potential, traditional PbRL methods are often constrained by the indivisibility of annotations, which impedes the learning process. In this paper, we introduce a groundbreaking approach, Skill-Enhanced Preference Optimization Algorithm~(S-EPOA), which addresses the annotation indivisibility issue by integrating skill mechanisms into the preference learning framework. Specifically, we first conduct the unsupervised pretraining to learn useful skills. Then, we propose a novel query selection mechanism to balance the information gain and discriminability over the learned skill space. Experimental results on a range of tasks, including robotic manipulation and locomotion, demonstrate that S-EPOA significantly outperforms conventional PbRL methods in terms of both robustness and learning efficiency. The results highlight the effectiveness of skill-driven learning in overcoming the challenges posed by annotation indivisibility.
E-MAPP: Efficient Multi-Agent Reinforcement Learning with Parallel Program Guidance
Dec 05, 2022

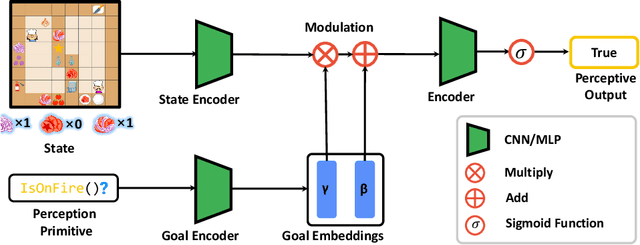

A critical challenge in multi-agent reinforcement learning(MARL) is for multiple agents to efficiently accomplish complex, long-horizon tasks. The agents often have difficulties in cooperating on common goals, dividing complex tasks, and planning through several stages to make progress. We propose to address these challenges by guiding agents with programs designed for parallelization, since programs as a representation contain rich structural and semantic information, and are widely used as abstractions for long-horizon tasks. Specifically, we introduce Efficient Multi-Agent Reinforcement Learning with Parallel Program Guidance(E-MAPP), a novel framework that leverages parallel programs to guide multiple agents to efficiently accomplish goals that require planning over $10+$ stages. E-MAPP integrates the structural information from a parallel program, promotes the cooperative behaviors grounded in program semantics, and improves the time efficiency via a task allocator. We conduct extensive experiments on a series of challenging, long-horizon cooperative tasks in the Overcooked environment. Results show that E-MAPP outperforms strong baselines in terms of the completion rate, time efficiency, and zero-shot generalization ability by a large margin.