 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLooking Backward: Retrospective Backward Synthesis for Goal-Conditioned GFlowNets
Jun 03, 2024Generative Flow Networks (GFlowNets) are amortized sampling methods for learning a stochastic policy to sequentially generate compositional objects with probabilities proportional to their rewards. GFlowNets exhibit a remarkable ability to generate diverse sets of high-reward objects, in contrast to standard return maximization reinforcement learning approaches, which often converge to a single optimal solution. Recent works have arisen for learning goal-conditioned GFlowNets to acquire various useful properties, aiming to train a single GFlowNet capable of achieving different goals as the task specifies. However, training a goal-conditioned GFlowNet poses critical challenges due to extremely sparse rewards, which is further exacerbated in large state spaces. In this work, we propose a novel method named Retrospective Backward Synthesis (RBS) to address these challenges. Specifically, RBS synthesizes a new backward trajectory based on the backward policy in GFlowNets to enrich training trajectories with enhanced quality and diversity, thereby efficiently solving the sparse reward problem. Extensive empirical results show that our method improves sample efficiency by a large margin and outperforms strong baselines on various standard evaluation benchmarks.
RL-ViGen: A Reinforcement Learning Benchmark for Visual Generalization
Jul 15, 2023Visual Reinforcement Learning (Visual RL), coupled with high-dimensional observations, has consistently confronted the long-standing challenge of generalization. Despite the focus on algorithms aimed at resolving visual generalization problems, we argue that the devil is in the existing benchmarks as they are restricted to isolated tasks and generalization categories, undermining a comprehensive evaluation of agents' visual generalization capabilities. To bridge this gap, we introduce RL-ViGen: a novel Reinforcement Learning Benchmark for Visual Generalization, which contains diverse tasks and a wide spectrum of generalization types, thereby facilitating the derivation of more reliable conclusions. Furthermore, RL-ViGen incorporates the latest generalization visual RL algorithms into a unified framework, under which the experiment results indicate that no single existing algorithm has prevailed universally across tasks. Our aspiration is that RL-ViGen will serve as a catalyst in this area, and lay a foundation for the future creation of universal visual generalization RL agents suitable for real-world scenarios. Access to our code and implemented algorithms is provided at https://gemcollector.github.io/RL-ViGen/.
E-MAPP: Efficient Multi-Agent Reinforcement Learning with Parallel Program Guidance
Dec 05, 2022

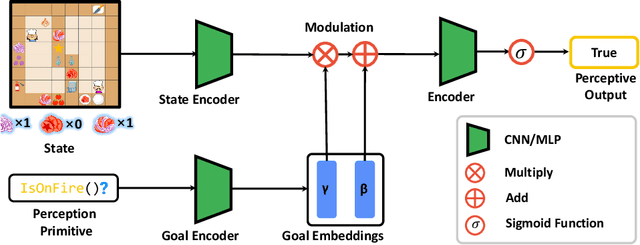

A critical challenge in multi-agent reinforcement learning(MARL) is for multiple agents to efficiently accomplish complex, long-horizon tasks. The agents often have difficulties in cooperating on common goals, dividing complex tasks, and planning through several stages to make progress. We propose to address these challenges by guiding agents with programs designed for parallelization, since programs as a representation contain rich structural and semantic information, and are widely used as abstractions for long-horizon tasks. Specifically, we introduce Efficient Multi-Agent Reinforcement Learning with Parallel Program Guidance(E-MAPP), a novel framework that leverages parallel programs to guide multiple agents to efficiently accomplish goals that require planning over $10+$ stages. E-MAPP integrates the structural information from a parallel program, promotes the cooperative behaviors grounded in program semantics, and improves the time efficiency via a task allocator. We conduct extensive experiments on a series of challenging, long-horizon cooperative tasks in the Overcooked environment. Results show that E-MAPP outperforms strong baselines in terms of the completion rate, time efficiency, and zero-shot generalization ability by a large margin.