 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeel Robot Feels: Tactile Feedback Array Glove for Dexterous Manipulation
Mar 30, 2026Teleoperation is a key approach for collecting high-quality, physically consistent demonstrations for robotic manipulation. However, teleoperation for dexterous manipulation remains constrained by: (i) inaccurate hand-robot motion mapping, which limits teleoperated dexterity, and (ii) limited tactile feedback that forces vision-dominated interaction and hinders perception of contact geometry and force variation. To address these challenges, we present TAG, a low-cost glove system that integrates precise hand motion capture with high-resolution tactile feedback, enabling effective tactile-in-the-loop dexterous teleoperation. For motion capture, TAG employs a non-contact magnetic sensing design that provides drift-free, electromagnetically robust 21-DoF joint tracking with joint angle estimation errors below 1 degree. Meanwhile, to restore tactile sensation, TAG equips each finger with a 32-actuator tactile array within a compact 2 cm^2 module, allowing operators to directly feel physical interactions at the robot end-effector through spatial activation patterns. Through real-world teleoperation experiments and user studies, we show that TAG enables reliable real-time perception of contact geometry and dynamic force, improves success rates in contact-rich teleoperation tasks, and increases the reliability of demonstration data collection for learning-based manipulation.
One-Policy-Fits-All: Geometry-Aware Action Latents for Cross-Embodiment Manipulation
Mar 15, 2026Cross-embodiment manipulation is crucial for enhancing the scalability of robot manipulation and reducing the high cost of data collection. However, the significant differences between embodiments, such as variations in action spaces and structural disparities, pose challenges for joint training across multiple sources of data. To address this, we propose One-Policy-Fits-All (OPFA), a framework that enables learning a single, versatile policy across multiple embodiments. We first learn a Geometry-Aware Latent Representation (GaLR), which leverages 3D convolution networks and transformers to build a shared latent action space across different embodiments. Then we design a unified latent retargeting decoder that extracts embodiment-specific actions from the latent representations, without any embodiment-specific decoder tuning. OPFA enables end-to-end co-training of data from diverse embodiments, including various grippers and dexterous hands with arbitrary degrees of freedom, significantly improving data efficiency and reducing the cost of skill transfer. We conduct extensive experiments across 11 different end-effectors. The results demonstrate that OPFA significantly improves policy performance in diverse settings by leveraging heterogeneous embodiment data. For instance, cross-embodiment co-training can improve success rates by more than 50% compared to single-source training. Moreover, by adding only a few demonstrations from a new embodiment (e.g., eight), OPFA can achieve performance comparable to that of a well-trained model with 72 demonstrations.
UltraDexGrasp: Learning Universal Dexterous Grasping for Bimanual Robots with Synthetic Data
Mar 05, 2026Grasping is a fundamental capability for robots to interact with the physical world. Humans, equipped with two hands, autonomously select appropriate grasp strategies based on the shape, size, and weight of objects, enabling robust grasping and subsequent manipulation. In contrast, current robotic grasping remains limited, particularly in multi-strategy settings. Although substantial efforts have targeted parallel-gripper and single-hand grasping, dexterous grasping for bimanual robots remains underexplored, with data being a primary bottleneck. Achieving physically plausible and geometrically conforming grasps that can withstand external wrenches poses significant challenges. To address these issues, we introduce UltraDexGrasp, a framework for universal dexterous grasping with bimanual robots. The proposed data-generation pipeline integrates optimization-based grasp synthesis with planning-based demonstration generation, yielding high-quality and diverse trajectories across multiple grasp strategies. With this framework, we curate UltraDexGrasp-20M, a large-scale, multi-strategy grasp dataset comprising 20 million frames across 1,000 objects. Based on UltraDexGrasp-20M, we further develop a simple yet effective grasp policy that takes point clouds as input, aggregates scene features via unidirectional attention, and predicts control commands. Trained exclusively on synthetic data, the policy achieves robust zero-shot sim-to-real transfer and consistently succeeds on novel objects with varied shapes, sizes, and weights, attaining an average success rate of 81.2% in real-world universal dexterous grasping. To facilitate future research on grasping with bimanual robots, we open-source the data generation pipeline at https://github.com/InternRobotics/UltraDexGrasp.
Robo3R: Enhancing Robotic Manipulation with Accurate Feed-Forward 3D Reconstruction
Feb 10, 20263D spatial perception is fundamental to generalizable robotic manipulation, yet obtaining reliable, high-quality 3D geometry remains challenging. Depth sensors suffer from noise and material sensitivity, while existing reconstruction models lack the precision and metric consistency required for physical interaction. We introduce Robo3R, a feed-forward, manipulation-ready 3D reconstruction model that predicts accurate, metric-scale scene geometry directly from RGB images and robot states in real time. Robo3R jointly infers scale-invariant local geometry and relative camera poses, which are unified into the scene representation in the canonical robot frame via a learned global similarity transformation. To meet the precision demands of manipulation, Robo3R employs a masked point head for sharp, fine-grained point clouds, and a keypoint-based Perspective-n-Point (PnP) formulation to refine camera extrinsics and global alignment. Trained on Robo3R-4M, a curated large-scale synthetic dataset with four million high-fidelity annotated frames, Robo3R consistently outperforms state-of-the-art reconstruction methods and depth sensors. Across downstream tasks including imitation learning, sim-to-real transfer, grasp synthesis, and collision-free motion planning, we observe consistent gains in performance, suggesting the promise of this alternative 3D sensing module for robotic manipulation.
DexImit: Learning Bimanual Dexterous Manipulation from Monocular Human Videos
Feb 10, 2026Data scarcity fundamentally limits the generalization of bimanual dexterous manipulation, as real-world data collection for dexterous hands is expensive and labor-intensive. Human manipulation videos, as a direct carrier of manipulation knowledge, offer significant potential for scaling up robot learning. However, the substantial embodiment gap between human hands and robotic dexterous hands makes direct pretraining from human videos extremely challenging. To bridge this gap and unleash the potential of large-scale human manipulation video data, we propose DexImit, an automated framework that converts monocular human manipulation videos into physically plausible robot data, without any additional information. DexImit employs a four-stage generation pipeline: (1) reconstructing hand-object interactions from arbitrary viewpoints with near-metric scale; (2) performing subtask decomposition and bimanual scheduling; (3) synthesizing robot trajectories consistent with the demonstrated interactions; (4) comprehensive data augmentation for zero-shot real-world deployment. Building on these designs, DexImit can generate large-scale robot data based on human videos, either from the Internet or video generation models. DexImit is capable of handling diverse manipulation tasks, including tool use (e.g., cutting an apple), long-horizon tasks (e.g., making a beverage), and fine-grained manipulations (e.g., stacking cups).
MMSI-Bench: A Benchmark for Multi-Image Spatial Intelligence
May 29, 2025Spatial intelligence is essential for multimodal large language models (MLLMs) operating in the complex physical world. Existing benchmarks, however, probe only single-image relations and thus fail to assess the multi-image spatial reasoning that real-world deployments demand. We introduce MMSI-Bench, a VQA benchmark dedicated to multi-image spatial intelligence. Six 3D-vision researchers spent more than 300 hours meticulously crafting 1,000 challenging, unambiguous multiple-choice questions from over 120,000 images, each paired with carefully designed distractors and a step-by-step reasoning process. We conduct extensive experiments and thoroughly evaluate 34 open-source and proprietary MLLMs, observing a wide gap: the strongest open-source model attains roughly 30% accuracy and OpenAI's o3 reasoning model reaches 40%, while humans score 97%. These results underscore the challenging nature of MMSI-Bench and the substantial headroom for future research. Leveraging the annotated reasoning processes, we also provide an automated error analysis pipeline that diagnoses four dominant failure modes, including (1) grounding errors, (2) overlap-matching and scene-reconstruction errors, (3) situation-transformation reasoning errors, and (4) spatial-logic errors, offering valuable insights for advancing multi-image spatial intelligence. Project page: https://runsenxu.com/projects/MMSI_Bench .
Novel Demonstration Generation with Gaussian Splatting Enables Robust One-Shot Manipulation
Apr 17, 2025


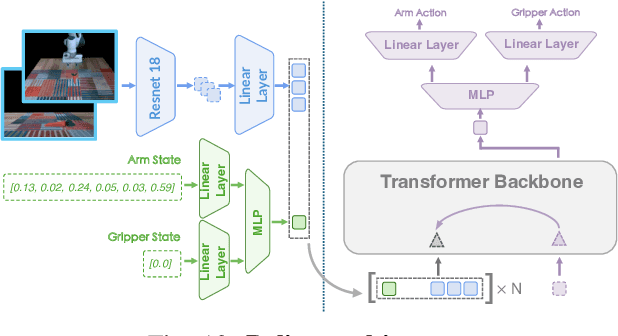
Visuomotor policies learned from teleoperated demonstrations face challenges such as lengthy data collection, high costs, and limited data diversity. Existing approaches address these issues by augmenting image observations in RGB space or employing Real-to-Sim-to-Real pipelines based on physical simulators. However, the former is constrained to 2D data augmentation, while the latter suffers from imprecise physical simulation caused by inaccurate geometric reconstruction. This paper introduces RoboSplat, a novel method that generates diverse, visually realistic demonstrations by directly manipulating 3D Gaussians. Specifically, we reconstruct the scene through 3D Gaussian Splatting (3DGS), directly edit the reconstructed scene, and augment data across six types of generalization with five techniques: 3D Gaussian replacement for varying object types, scene appearance, and robot embodiments; equivariant transformations for different object poses; visual attribute editing for various lighting conditions; novel view synthesis for new camera perspectives; and 3D content generation for diverse object types. Comprehensive real-world experiments demonstrate that RoboSplat significantly enhances the generalization of visuomotor policies under diverse disturbances. Notably, while policies trained on hundreds of real-world demonstrations with additional 2D data augmentation achieve an average success rate of 57.2%, RoboSplat attains 87.8% in one-shot settings across six types of generalization in the real world.
Predictive Inverse Dynamics Models are Scalable Learners for Robotic Manipulation
Dec 19, 2024



Current efforts to learn scalable policies in robotic manipulation primarily fall into two categories: one focuses on "action," which involves behavior cloning from extensive collections of robotic data, while the other emphasizes "vision," enhancing model generalization by pre-training representations or generative models, also referred to as world models, using large-scale visual datasets. This paper presents an end-to-end paradigm that predicts actions using inverse dynamics models conditioned on the robot's forecasted visual states, named Predictive Inverse Dynamics Models (PIDM). By closing the loop between vision and action, the end-to-end PIDM can be a better scalable action learner. In practice, we use Transformers to process both visual states and actions, naming the model Seer. It is initially pre-trained on large-scale robotic datasets, such as DROID, and can be adapted to realworld scenarios with a little fine-tuning data. Thanks to large-scale, end-to-end training and the synergy between vision and action, Seer significantly outperforms previous methods across both simulation and real-world experiments. It achieves improvements of 13% on the LIBERO-LONG benchmark, 21% on CALVIN ABC-D, and 43% in real-world tasks. Notably, Seer sets a new state-of-the-art on CALVIN ABC-D benchmark, achieving an average length of 4.28, and exhibits superior generalization for novel objects, lighting conditions, and environments under high-intensity disturbances on real-world scenarios. Code and models are publicly available at https://github.com/OpenRobotLab/Seer/.
GRUtopia: Dream General Robots in a City at Scale
Jul 15, 2024Recent works have been exploring the scaling laws in the field of Embodied AI. Given the prohibitive costs of collecting real-world data, we believe the Simulation-to-Real (Sim2Real) paradigm is a crucial step for scaling the learning of embodied models. This paper introduces project GRUtopia, the first simulated interactive 3D society designed for various robots. It features several advancements: (a) The scene dataset, GRScenes, includes 100k interactive, finely annotated scenes, which can be freely combined into city-scale environments. In contrast to previous works mainly focusing on home, GRScenes covers 89 diverse scene categories, bridging the gap of service-oriented environments where general robots would be initially deployed. (b) GRResidents, a Large Language Model (LLM) driven Non-Player Character (NPC) system that is responsible for social interaction, task generation, and task assignment, thus simulating social scenarios for embodied AI applications. (c) The benchmark, GRBench, supports various robots but focuses on legged robots as primary agents and poses moderately challenging tasks involving Object Loco-Navigation, Social Loco-Navigation, and Loco-Manipulation. We hope that this work can alleviate the scarcity of high-quality data in this field and provide a more comprehensive assessment of Embodied AI research. The project is available at https://github.com/OpenRobotLab/GRUtopia.
BBSEA: An Exploration of Brain-Body Synchronization for Embodied Agents
Feb 13, 2024



Embodied agents capable of complex physical skills can improve productivity, elevate life quality, and reshape human-machine collaboration. We aim at autonomous training of embodied agents for various tasks involving mainly large foundation models. It is believed that these models could act as a brain for embodied agents; however, existing methods heavily rely on humans for task proposal and scene customization, limiting the learning autonomy, training efficiency, and generalization of the learned policies. In contrast, we introduce a brain-body synchronization ({\it BBSEA}) scheme to promote embodied learning in unknown environments without human involvement. The proposed combines the wisdom of foundation models (``brain'') with the physical capabilities of embodied agents (``body''). Specifically, it leverages the ``brain'' to propose learnable physical tasks and success metrics, enabling the ``body'' to automatically acquire various skills by continuously interacting with the scene. We carry out an exploration of the proposed autonomous learning scheme in a table-top setting, and we demonstrate that the proposed synchronization can generate diverse tasks and develop multi-task policies with promising adaptability to new tasks and configurations. We will release our data, code, and trained models to facilitate future studies in building autonomously learning agents with large foundation models in more complex scenarios. More visualizations are available at \href{https://bbsea-embodied-ai.github.io}{https://bbsea-embodied-ai.github.io}