 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoVie: Visual Model-Based Policy Adaptation for View Generalization
Paper and Code
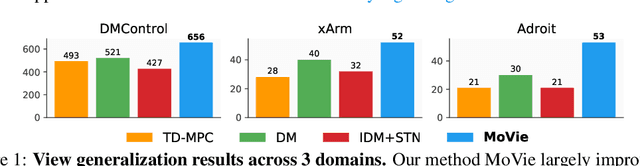
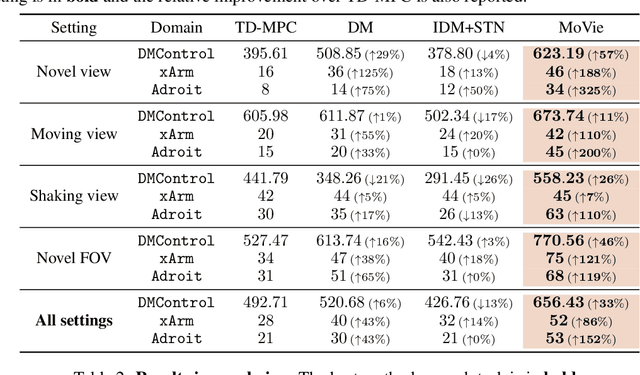
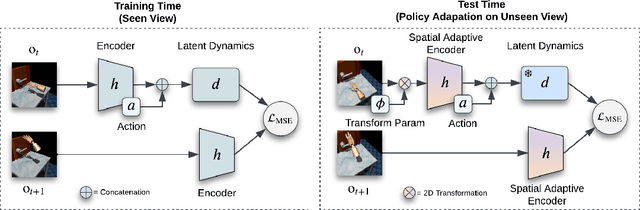
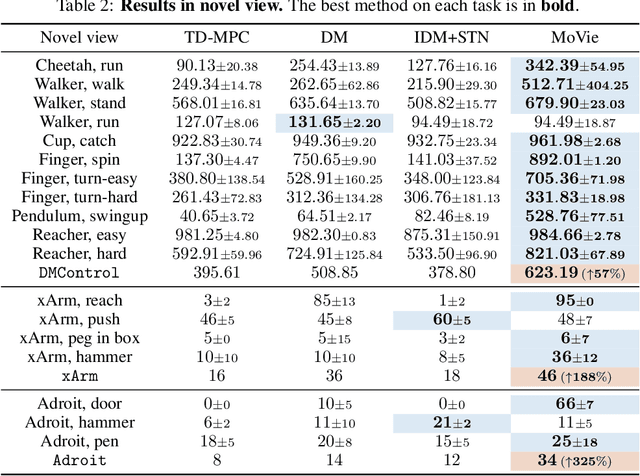
Visual Reinforcement Learning (RL) agents trained on limited views face significant challenges in generalizing their learned abilities to unseen views. This inherent difficulty is known as the problem of $\textit{view generalization}$. In this work, we systematically categorize this fundamental problem into four distinct and highly challenging scenarios that closely resemble real-world situations. Subsequently, we propose a straightforward yet effective approach to enable successful adaptation of visual $\textbf{Mo}$del-based policies for $\textbf{Vie}$w generalization ($\textbf{MoVie}$) during test time, without any need for explicit reward signals and any modification during training time. Our method demonstrates substantial advancements across all four scenarios encompassing a total of $\textbf{18}$ tasks sourced from DMControl, xArm, and Adroit, with a relative improvement of $\mathbf{33}$%, $\mathbf{86}$%, and $\mathbf{152}$% respectively. The superior results highlight the immense potential of our approach for real-world robotics applications. Videos are available at https://yangsizhe.github.io/MoVie/ .