 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResMimic: From General Motion Tracking to Humanoid Whole-body Loco-Manipulation via Residual Learning
Oct 06, 2025Humanoid whole-body loco-manipulation promises transformative capabilities for daily service and warehouse tasks. While recent advances in general motion tracking (GMT) have enabled humanoids to reproduce diverse human motions, these policies lack the precision and object awareness required for loco-manipulation. To this end, we introduce ResMimic, a two-stage residual learning framework for precise and expressive humanoid control from human motion data. First, a GMT policy, trained on large-scale human-only motion, serves as a task-agnostic base for generating human-like whole-body movements. An efficient but precise residual policy is then learned to refine the GMT outputs to improve locomotion and incorporate object interaction. To further facilitate efficient training, we design (i) a point-cloud-based object tracking reward for smoother optimization, (ii) a contact reward that encourages accurate humanoid body-object interactions, and (iii) a curriculum-based virtual object controller to stabilize early training. We evaluate ResMimic in both simulation and on a real Unitree G1 humanoid. Results show substantial gains in task success, training efficiency, and robustness over strong baselines. Videos are available at https://resmimic.github.io/ .
RoboVerse: Towards a Unified Platform, Dataset and Benchmark for Scalable and Generalizable Robot Learning
Apr 26, 2025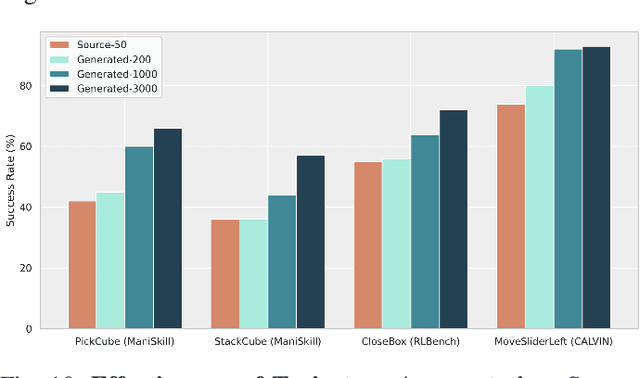



Data scaling and standardized evaluation benchmarks have driven significant advances in natural language processing and computer vision. However, robotics faces unique challenges in scaling data and establishing evaluation protocols. Collecting real-world data is resource-intensive and inefficient, while benchmarking in real-world scenarios remains highly complex. Synthetic data and simulation offer promising alternatives, yet existing efforts often fall short in data quality, diversity, and benchmark standardization. To address these challenges, we introduce RoboVerse, a comprehensive framework comprising a simulation platform, a synthetic dataset, and unified benchmarks. Our simulation platform supports multiple simulators and robotic embodiments, enabling seamless transitions between different environments. The synthetic dataset, featuring high-fidelity physics and photorealistic rendering, is constructed through multiple approaches. Additionally, we propose unified benchmarks for imitation learning and reinforcement learning, enabling evaluation across different levels of generalization. At the core of the simulation platform is MetaSim, an infrastructure that abstracts diverse simulation environments into a universal interface. It restructures existing simulation environments into a simulator-agnostic configuration system, as well as an API aligning different simulator functionalities, such as launching simulation environments, loading assets with initial states, stepping the physics engine, etc. This abstraction ensures interoperability and extensibility. Comprehensive experiments demonstrate that RoboVerse enhances the performance of imitation learning, reinforcement learning, world model learning, and sim-to-real transfer. These results validate the reliability of our dataset and benchmarks, establishing RoboVerse as a robust solution for advancing robot learning.
Learning from Massive Human Videos for Universal Humanoid Pose Control
Dec 18, 2024



Scalable learning of humanoid robots is crucial for their deployment in real-world applications. While traditional approaches primarily rely on reinforcement learning or teleoperation to achieve whole-body control, they are often limited by the diversity of simulated environments and the high costs of demonstration collection. In contrast, human videos are ubiquitous and present an untapped source of semantic and motion information that could significantly enhance the generalization capabilities of humanoid robots. This paper introduces Humanoid-X, a large-scale dataset of over 20 million humanoid robot poses with corresponding text-based motion descriptions, designed to leverage this abundant data. Humanoid-X is curated through a comprehensive pipeline: data mining from the Internet, video caption generation, motion retargeting of humans to humanoid robots, and policy learning for real-world deployment. With Humanoid-X, we further train a large humanoid model, UH-1, which takes text instructions as input and outputs corresponding actions to control a humanoid robot. Extensive simulated and real-world experiments validate that our scalable training approach leads to superior generalization in text-based humanoid control, marking a significant step toward adaptable, real-world-ready humanoid robots.
GRUtopia: Dream General Robots in a City at Scale
Jul 15, 2024Recent works have been exploring the scaling laws in the field of Embodied AI. Given the prohibitive costs of collecting real-world data, we believe the Simulation-to-Real (Sim2Real) paradigm is a crucial step for scaling the learning of embodied models. This paper introduces project GRUtopia, the first simulated interactive 3D society designed for various robots. It features several advancements: (a) The scene dataset, GRScenes, includes 100k interactive, finely annotated scenes, which can be freely combined into city-scale environments. In contrast to previous works mainly focusing on home, GRScenes covers 89 diverse scene categories, bridging the gap of service-oriented environments where general robots would be initially deployed. (b) GRResidents, a Large Language Model (LLM) driven Non-Player Character (NPC) system that is responsible for social interaction, task generation, and task assignment, thus simulating social scenarios for embodied AI applications. (c) The benchmark, GRBench, supports various robots but focuses on legged robots as primary agents and poses moderately challenging tasks involving Object Loco-Navigation, Social Loco-Navigation, and Loco-Manipulation. We hope that this work can alleviate the scarcity of high-quality data in this field and provide a more comprehensive assessment of Embodied AI research. The project is available at https://github.com/OpenRobotLab/GRUtopia.
TieBot: Learning to Knot a Tie from Visual Demonstration through a Real-to-Sim-to-Real Approach
Jul 03, 2024



The tie-knotting task is highly challenging due to the tie's high deformation and long-horizon manipulation actions. This work presents TieBot, a Real-to-Sim-to-Real learning from visual demonstration system for the robots to learn to knot a tie. We introduce the Hierarchical Feature Matching approach to estimate a sequence of tie's meshes from the demonstration video. With these estimated meshes used as subgoals, we first learn a teacher policy using privileged information. Then, we learn a student policy with point cloud observation by imitating teacher policy. Lastly, our pipeline learns a residual policy when the learned policy is applied to real-world execution, mitigating the Sim2Real gap. We demonstrate the effectiveness of TieBot in simulation and the real world. In the real-world experiment, a dual-arm robot successfully knots a tie, achieving 50% success rate among 10 trials. Videos can be found on our $\href{https://tiebots.github.io/}{\text{website}}$.
OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments
Apr 11, 2024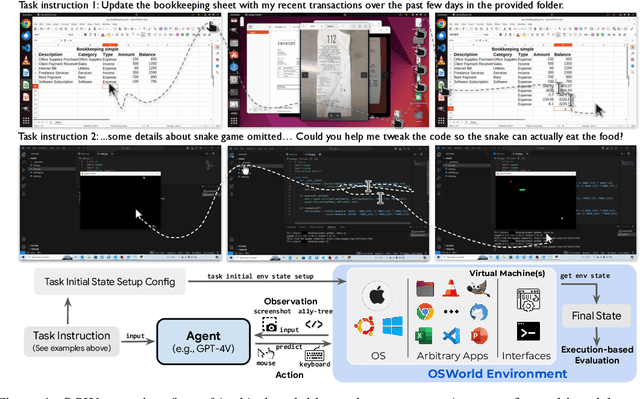

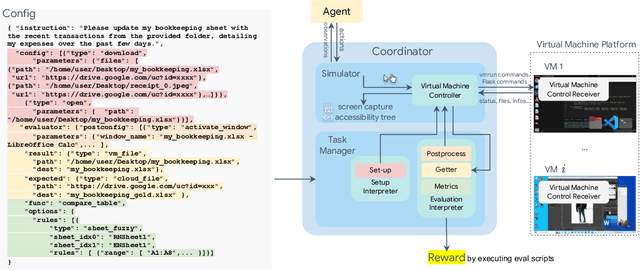

Autonomous agents that accomplish complex computer tasks with minimal human interventions have the potential to transform human-computer interaction, significantly enhancing accessibility and productivity. However, existing benchmarks either lack an interactive environment or are limited to environments specific to certain applications or domains, failing to reflect the diverse and complex nature of real-world computer use, thereby limiting the scope of tasks and agent scalability. To address this issue, we introduce OSWorld, the first-of-its-kind scalable, real computer environment for multimodal agents, supporting task setup, execution-based evaluation, and interactive learning across various operating systems such as Ubuntu, Windows, and macOS. OSWorld can serve as a unified, integrated computer environment for assessing open-ended computer tasks that involve arbitrary applications. Building upon OSWorld, we create a benchmark of 369 computer tasks involving real web and desktop apps in open domains, OS file I/O, and workflows spanning multiple applications. Each task example is derived from real-world computer use cases and includes a detailed initial state setup configuration and a custom execution-based evaluation script for reliable, reproducible evaluation. Extensive evaluation of state-of-the-art LLM/VLM-based agents on OSWorld reveals significant deficiencies in their ability to serve as computer assistants. While humans can accomplish over 72.36% of the tasks, the best model achieves only 12.24% success, primarily struggling with GUI grounding and operational knowledge. Comprehensive analysis using OSWorld provides valuable insights for developing multimodal generalist agents that were not possible with previous benchmarks. Our code, environment, baseline models, and data are publicly available at https://os-world.github.io.
Lemur: Harmonizing Natural Language and Code for Language Agents
Oct 10, 2023We introduce Lemur and Lemur-Chat, openly accessible language models optimized for both natural language and coding capabilities to serve as the backbone of versatile language agents. The evolution from language chat models to functional language agents demands that models not only master human interaction, reasoning, and planning but also ensure grounding in the relevant environments. This calls for a harmonious blend of language and coding capabilities in the models. Lemur and Lemur-Chat are proposed to address this necessity, demonstrating balanced proficiencies in both domains, unlike existing open-source models that tend to specialize in either. Through meticulous pre-training using a code-intensive corpus and instruction fine-tuning on text and code data, our models achieve state-of-the-art averaged performance across diverse text and coding benchmarks among open-source models. Comprehensive experiments demonstrate Lemur's superiority over existing open-source models and its proficiency across various agent tasks involving human communication, tool usage, and interaction under fully- and partially- observable environments. The harmonization between natural and programming languages enables Lemur-Chat to significantly narrow the gap with proprietary models on agent abilities, providing key insights into developing advanced open-source agents adept at reasoning, planning, and operating seamlessly across environments. https://github.com/OpenLemur/Lemur
Text2Reward: Automated Dense Reward Function Generation for Reinforcement Learning
Sep 21, 2023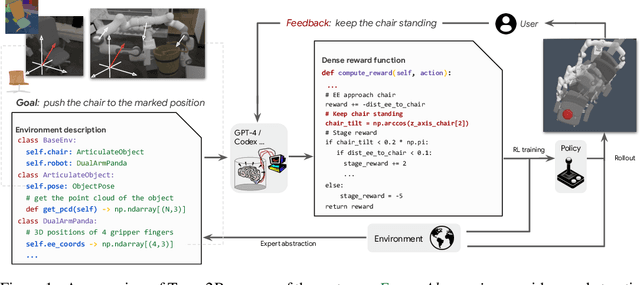
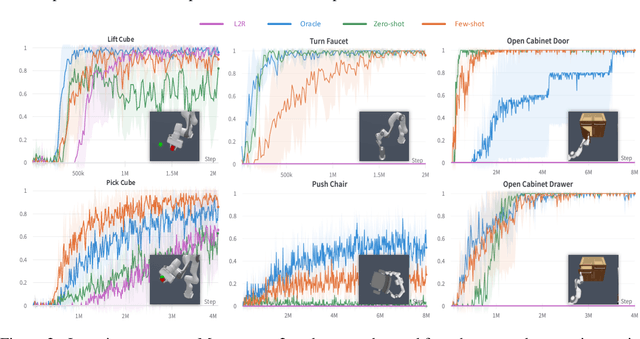
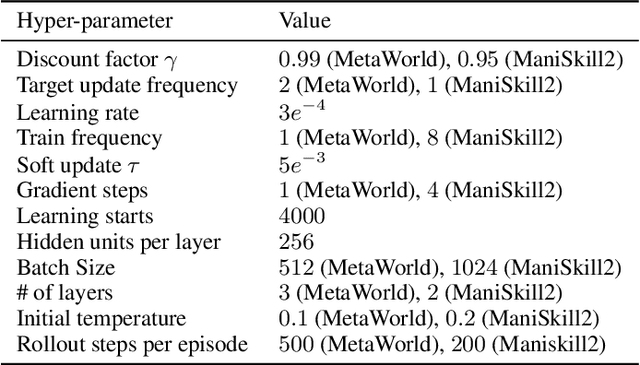
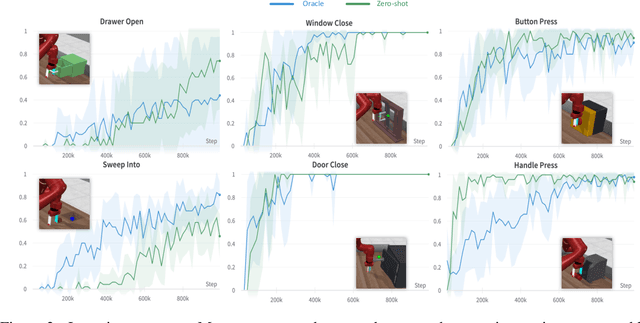
Designing reward functions is a longstanding challenge in reinforcement learning (RL); it requires specialized knowledge or domain data, leading to high costs for development. To address this, we introduce Text2Reward, a data-free framework that automates the generation of dense reward functions based on large language models (LLMs). Given a goal described in natural language, Text2Reward generates dense reward functions as an executable program grounded in a compact representation of the environment. Unlike inverse RL and recent work that uses LLMs to write sparse reward codes, Text2Reward produces interpretable, free-form dense reward codes that cover a wide range of tasks, utilize existing packages, and allow iterative refinement with human feedback. We evaluate Text2Reward on two robotic manipulation benchmarks (ManiSkill2, MetaWorld) and two locomotion environments of MuJoCo. On 13 of the 17 manipulation tasks, policies trained with generated reward codes achieve similar or better task success rates and convergence speed than expert-written reward codes. For locomotion tasks, our method learns six novel locomotion behaviors with a success rate exceeding 94%. Furthermore, we show that the policies trained in the simulator with our method can be deployed in the real world. Finally, Text2Reward further improves the policies by refining their reward functions with human feedback. Video results are available at https://text-to-reward.github.io
ClothesNet: An Information-Rich 3D Garment Model Repository with Simulated Clothes Environment
Aug 19, 2023
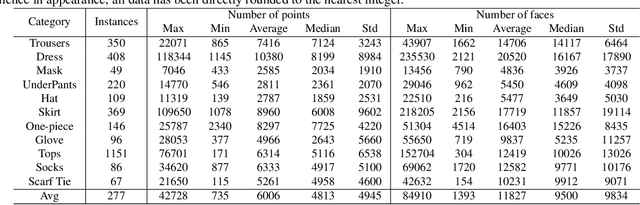


We present ClothesNet: a large-scale dataset of 3D clothes objects with information-rich annotations. Our dataset consists of around 4400 models covering 11 categories annotated with clothes features, boundary lines, and keypoints. ClothesNet can be used to facilitate a variety of computer vision and robot interaction tasks. Using our dataset, we establish benchmark tasks for clothes perception, including classification, boundary line segmentation, and keypoint detection, and develop simulated clothes environments for robotic interaction tasks, including rearranging, folding, hanging, and dressing. We also demonstrate the efficacy of our ClothesNet in real-world experiments. Supplemental materials and dataset are available on our project webpage.
kNN-BOX: A Unified Framework for Nearest Neighbor Generation
Feb 27, 2023Augmenting the base neural model with a token-level symbolic datastore is a novel generation paradigm and has achieved promising results in machine translation (MT). In this paper, we introduce a unified framework kNN-BOX, which enables quick development and interactive analysis for this novel paradigm. kNN-BOX decomposes the datastore-augmentation approach into three modules: datastore, retriever and combiner, thus putting diverse kNN generation methods into a unified way. Currently, kNN-BOX has provided implementation of seven popular kNN-MT variants, covering research from performance enhancement to efficiency optimization. It is easy for users to reproduce these existing works or customize their own models. Besides, users can interact with their kNN generation systems with kNN-BOX to better understand the underlying inference process in a visualized way. In the experiment section, we apply kNN-BOX for machine translation and three other seq2seq generation tasks, namely, text simplification, paraphrase generation and question generation. Experiment results show that augmenting the base neural model with kNN-BOX leads to a large performance improvement in all these tasks. The code and document of kNN-BOX is available at https://github.com/NJUNLP/knn-box.