 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClinically Interpretable Sepsis Early Warning via LLM-Guided Simulation of Temporal Physiological Dynamics
Apr 22, 2026Timely and interpretable early warning of sepsis remains a major clinical challenge due to the complex temporal dynamics of physiological deterioration. Traditional data-driven models often provide accurate yet opaque predictions, limiting physicians' confidence and clinical applicability. To address this limitation, we propose a Large Language Model (LLM)-guided temporal simulation framework that explicitly models physiological trajectories prior to disease onset for clinically interpretable prediction. The framework consists of a spatiotemporal feature extraction module that captures dynamic dependencies among multivariate vital signs, a Medical Prompt-as-Prefix module that embeds clinical reasoning cues into LLMs, and an agent-based post-processing component that constrains predictions within physiologically plausible ranges. By first simulating the evolution of key physiological indicators and then classifying sepsis onset, our model offers transparent prediction mechanisms that align with clinical judgment. Evaluated on the MIMIC-IV and eICU databases, the proposed method achieves superior AUC scores (0.861-0.903) across 24-4-hour pre-onset prediction tasks, outperforming conventional deep learning and rule-based approaches. More importantly, it provides interpretable trajectories and risk trends that can assist clinicians in early intervention and personalized decision-making in intensive care environments.
FLASH: Fast Learning via GPU-Accelerated Simulation for High-Fidelity Deformable Manipulation in Minutes
Apr 19, 2026Simulation frameworks such as Isaac Sim have enabled scalable robot learning for locomotion and rigid-body manipulation; however, contact-rich simulation remains a major bottleneck for deformable object manipulation. The continuously changing geometry of soft materials, together with large numbers of vertices and contact constraints, makes it difficult to achieve high accuracy, speed, and stability required for large-scale interactive learning. We present FLASH, a GPU-native simulation framework for contact-rich deformable manipulation, built on an accurate NCP-based solver that enforces strict contact and deformation constraints while being explicitly designed for fine-grained GPU parallelism. Rather than porting conventional single-instruction-multiple-data (SIMD) solvers to GPUs, FLASH redesigns the physics engine from the ground up to leverage modern GPU architectures, including optimized collision handling and memory layouts. As a result, FLASH scales to over 3 million degrees of freedom at 30 FPS on a single RTX 5090, while accurately simulating physical interactions. Policies trained solely on FLASH-generated synthetic data in minutes achieve robust zero-shot sim-to-real transfer, which we validate on physical robots performing challenging deformable manipulation tasks such as towel folding and garment folding, without any real-world demonstration, providing a practical alternative to labor-intensive real-world data collection.
FAST-LIVO2 on Resource-Constrained Platforms: LiDAR-Inertial-Visual Odometry with Efficient Memory and Computation
Jan 23, 2025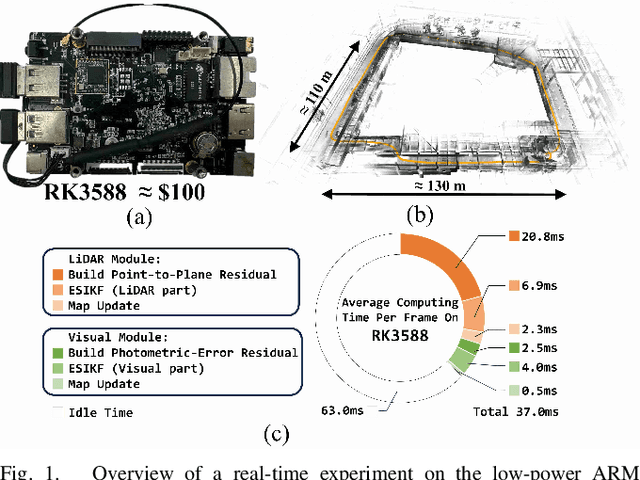

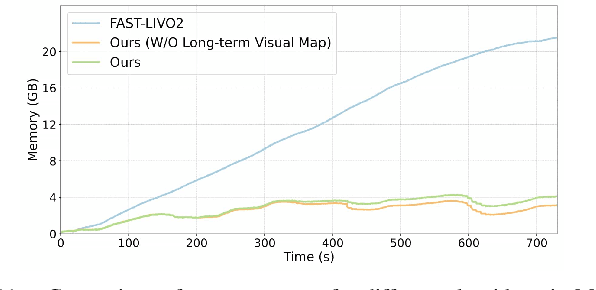
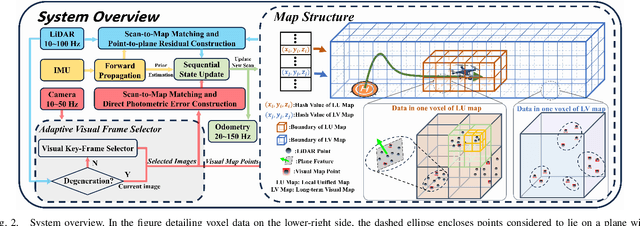
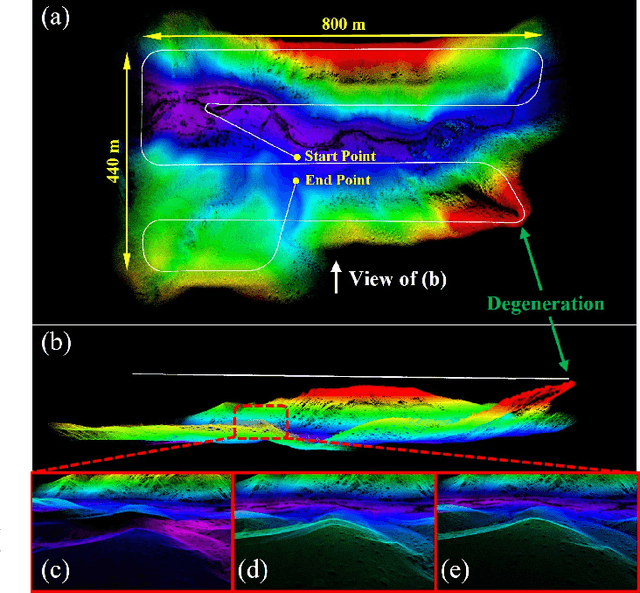
This paper presents a lightweight LiDAR-inertial-visual odometry system optimized for resource-constrained platforms. It integrates a degeneration-aware adaptive visual frame selector into error-state iterated Kalman filter (ESIKF) with sequential updates, improving computation efficiency significantly while maintaining a similar level of robustness. Additionally, a memory-efficient mapping structure combining a locally unified visual-LiDAR map and a long-term visual map achieves a good trade-off between performance and memory usage. Extensive experiments on x86 and ARM platforms demonstrate the system's robustness and efficiency. On the Hilti dataset, our system achieves a 33% reduction in per-frame runtime and 47% lower memory usage compared to FAST-LIVO2, with only a 3 cm increase in RMSE. Despite this slight accuracy trade-off, our system remains competitive, outperforming state-of-the-art (SOTA) LIO methods such as FAST-LIO2 and most existing LIVO systems. These results validate the system's capability for scalable deployment on resource-constrained edge computing platforms.
Voxel-SLAM: A Complete, Accurate, and Versatile LiDAR-Inertial SLAM System
Oct 11, 2024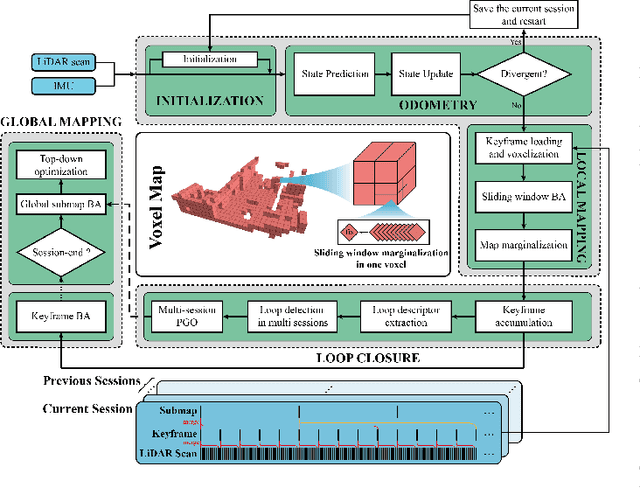
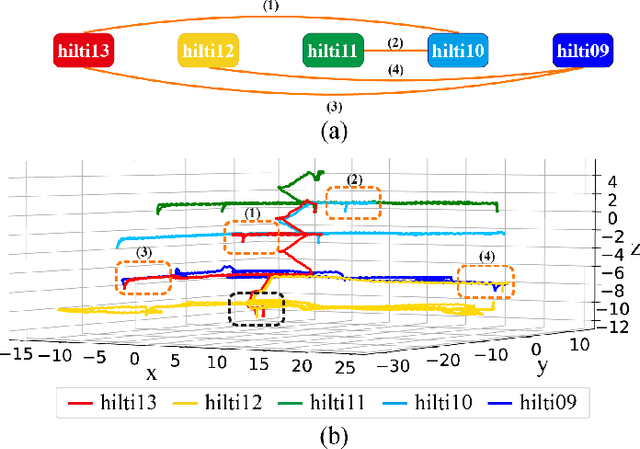

In this work, we present Voxel-SLAM: a complete, accurate, and versatile LiDAR-inertial SLAM system that fully utilizes short-term, mid-term, long-term, and multi-map data associations to achieve real-time estimation and high precision mapping. The system consists of five modules: initialization, odometry, local mapping, loop closure, and global mapping, all employing the same map representation, an adaptive voxel map. The initialization provides an accurate initial state estimation and a consistent local map for subsequent modules, enabling the system to start with a highly dynamic initial state. The odometry, exploiting the short-term data association, rapidly estimates current states and detects potential system divergence. The local mapping, exploiting the mid-term data association, employs a local LiDAR-inertial bundle adjustment (BA) to refine the states (and the local map) within a sliding window of recent LiDAR scans. The loop closure detects previously visited places in the current and all previous sessions. The global mapping refines the global map with an efficient hierarchical global BA. The loop closure and global mapping both exploit long-term and multi-map data associations. We conducted a comprehensive benchmark comparison with other state-of-the-art methods across 30 sequences from three representative scenes, including narrow indoor environments using hand-held equipment, large-scale wilderness environments with aerial robots, and urban environments on vehicle platforms. Other experiments demonstrate the robustness and efficiency of the initialization, the capacity to work in multiple sessions, and relocalization in degenerated environments.
Key-Grid: Unsupervised 3D Keypoints Detection using Grid Heatmap Features
Oct 03, 2024

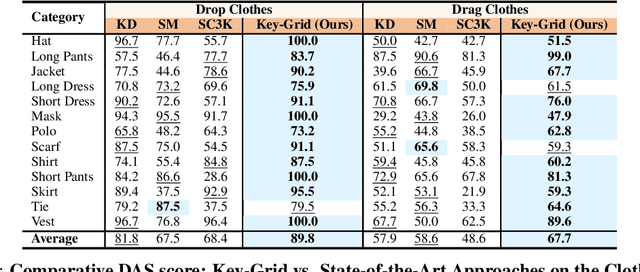
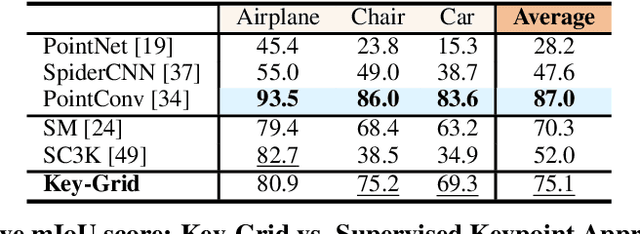
Detecting 3D keypoints with semantic consistency is widely used in many scenarios such as pose estimation, shape registration and robotics. Currently, most unsupervised 3D keypoint detection methods focus on the rigid-body objects. However, when faced with deformable objects, the keypoints they identify do not preserve semantic consistency well. In this paper, we introduce an innovative unsupervised keypoint detector Key-Grid for both the rigid-body and deformable objects, which is an autoencoder framework. The encoder predicts keypoints and the decoder utilizes the generated keypoints to reconstruct the objects. Unlike previous work, we leverage the identified keypoint in formation to form a 3D grid feature heatmap called grid heatmap, which is used in the decoder section. Grid heatmap is a novel concept that represents the latent variables for grid points sampled uniformly in the 3D cubic space, where these variables are the shortest distance between the grid points and the skeleton connected by keypoint pairs. Meanwhile, we incorporate the information from each layer of the encoder into the decoder section. We conduct an extensive evaluation of Key-Grid on a list of benchmark datasets. Key-Grid achieves the state-of-the-art performance on the semantic consistency and position accuracy of keypoints. Moreover, we demonstrate the robustness of Key-Grid to noise and downsampling. In addition, we achieve SE-(3) invariance of keypoints though generalizing Key-Grid to a SE(3)-invariant backbone.
FAST-LIVO2: Fast, Direct LiDAR-Inertial-Visual Odometry
Aug 26, 2024

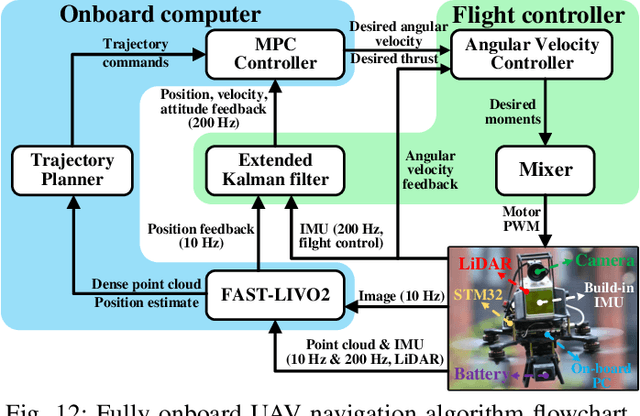

This paper proposes FAST-LIVO2: a fast, direct LiDAR-inertial-visual odometry framework to achieve accurate and robust state estimation in SLAM tasks and provide great potential in real-time, onboard robotic applications. FAST-LIVO2 fuses the IMU, LiDAR and image measurements efficiently through an ESIKF. To address the dimension mismatch between the heterogeneous LiDAR and image measurements, we use a sequential update strategy in the Kalman filter. To enhance the efficiency, we use direct methods for both the visual and LiDAR fusion, where the LiDAR module registers raw points without extracting edge or plane features and the visual module minimizes direct photometric errors without extracting ORB or FAST corner features. The fusion of both visual and LiDAR measurements is based on a single unified voxel map where the LiDAR module constructs the geometric structure for registering new LiDAR scans and the visual module attaches image patches to the LiDAR points. To enhance the accuracy of image alignment, we use plane priors from the LiDAR points in the voxel map (and even refine the plane prior) and update the reference patch dynamically after new images are aligned. Furthermore, to enhance the robustness of image alignment, FAST-LIVO2 employs an on-demanding raycast operation and estimates the image exposure time in real time. Lastly, we detail three applications of FAST-LIVO2: UAV onboard navigation demonstrating the system's computation efficiency for real-time onboard navigation, airborne mapping showcasing the system's mapping accuracy, and 3D model rendering (mesh-based and NeRF-based) underscoring the suitability of our reconstructed dense map for subsequent rendering tasks. We open source our code, dataset and application on GitHub to benefit the robotics community.
ClothesNet: An Information-Rich 3D Garment Model Repository with Simulated Clothes Environment
Aug 19, 2023
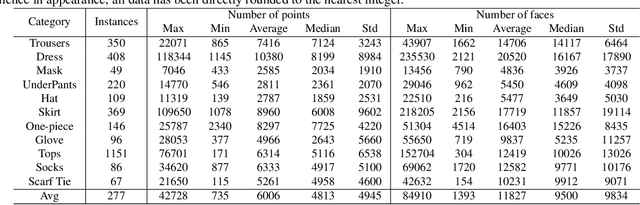


We present ClothesNet: a large-scale dataset of 3D clothes objects with information-rich annotations. Our dataset consists of around 4400 models covering 11 categories annotated with clothes features, boundary lines, and keypoints. ClothesNet can be used to facilitate a variety of computer vision and robot interaction tasks. Using our dataset, we establish benchmark tasks for clothes perception, including classification, boundary line segmentation, and keypoint detection, and develop simulated clothes environments for robotic interaction tasks, including rearranging, folding, hanging, and dressing. We also demonstrate the efficacy of our ClothesNet in real-world experiments. Supplemental materials and dataset are available on our project webpage.