 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTieBot: Learning to Knot a Tie from Visual Demonstration through a Real-to-Sim-to-Real Approach
Jul 03, 2024



The tie-knotting task is highly challenging due to the tie's high deformation and long-horizon manipulation actions. This work presents TieBot, a Real-to-Sim-to-Real learning from visual demonstration system for the robots to learn to knot a tie. We introduce the Hierarchical Feature Matching approach to estimate a sequence of tie's meshes from the demonstration video. With these estimated meshes used as subgoals, we first learn a teacher policy using privileged information. Then, we learn a student policy with point cloud observation by imitating teacher policy. Lastly, our pipeline learns a residual policy when the learned policy is applied to real-world execution, mitigating the Sim2Real gap. We demonstrate the effectiveness of TieBot in simulation and the real world. In the real-world experiment, a dual-arm robot successfully knots a tie, achieving 50% success rate among 10 trials. Videos can be found on our $\href{https://tiebots.github.io/}{\text{website}}$.
Learning Reward for Robot Skills Using Large Language Models via Self-Alignment
May 16, 2024



Learning reward functions remains the bottleneck to equip a robot with a broad repertoire of skills. Large Language Models (LLM) contain valuable task-related knowledge that can potentially aid in the learning of reward functions. However, the proposed reward function can be imprecise, thus ineffective which requires to be further grounded with environment information. We proposed a method to learn rewards more efficiently in the absence of humans. Our approach consists of two components: We first use the LLM to propose features and parameterization of the reward, then update the parameters through an iterative self-alignment process. In particular, the process minimizes the ranking inconsistency between the LLM and the learnt reward functions based on the execution feedback. The method was validated on 9 tasks across 2 simulation environments. It demonstrates a consistent improvement over training efficacy and efficiency, meanwhile consuming significantly fewer GPT tokens compared to the alternative mutation-based method.
Learning Reward for Physical Skills using Large Language Model
Oct 21, 2023



Learning reward functions for physical skills are challenging due to the vast spectrum of skills, the high-dimensionality of state and action space, and nuanced sensory feedback. The complexity of these tasks makes acquiring expert demonstration data both costly and time-consuming. Large Language Models (LLMs) contain valuable task-related knowledge that can aid in learning these reward functions. However, the direct application of LLMs for proposing reward functions has its limitations such as numerical instability and inability to incorporate the environment feedback. We aim to extract task knowledge from LLMs using environment feedback to create efficient reward functions for physical skills. Our approach consists of two components. We first use the LLM to propose features and parameterization of the reward function. Next, we update the parameters of this proposed reward function through an iterative self-alignment process. In particular, this process minimizes the ranking inconsistency between the LLM and our learned reward functions based on the new observations. We validated our method by testing it on three simulated physical skill learning tasks, demonstrating effective support for our design choices.
ClothesNet: An Information-Rich 3D Garment Model Repository with Simulated Clothes Environment
Aug 19, 2023
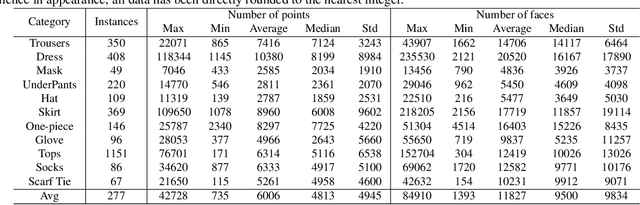


We present ClothesNet: a large-scale dataset of 3D clothes objects with information-rich annotations. Our dataset consists of around 4400 models covering 11 categories annotated with clothes features, boundary lines, and keypoints. ClothesNet can be used to facilitate a variety of computer vision and robot interaction tasks. Using our dataset, we establish benchmark tasks for clothes perception, including classification, boundary line segmentation, and keypoint detection, and develop simulated clothes environments for robotic interaction tasks, including rearranging, folding, hanging, and dressing. We also demonstrate the efficacy of our ClothesNet in real-world experiments. Supplemental materials and dataset are available on our project webpage.
Deep Double-Side Learning Ensemble Model for Few-Shot Parkinson Speech Recognition
Jun 20, 2020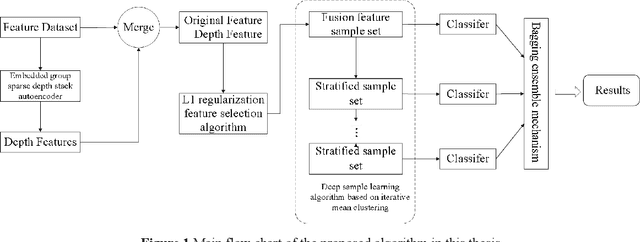

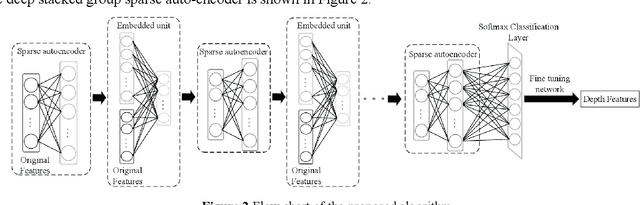

Diagnosis and therapeutic effect assessment of Parkinson disease based on voice data are very important,but its few-shot learning problem is challenging.Although deep learning is good at automatic feature extraction, it suffers from few-shot learning problem. Therefore, the general effective method is first conduct feature extraction based on prior knowledge, and then carry out feature reduction for subsequent classification. However, there are two major problems: 1) Structural information among speech features has not been mined and new features of higher quality have not been reconstructed. 2) Structural information between data samples has not been mined and new samples with higher quality have not been reconstructed. To solve these two problems, based on the existing Parkinson speech feature data set, a deep double-side learning ensemble model is designed in this paper that can reconstruct speech features and samples deeply and simultaneously. As to feature reconstruction, an embedded deep stacked group sparse auto-encoder is designed in this paper to conduct nonlinear feature transformation, so as to acquire new high-level deep features, and then the deep features are fused with original speech features by L1 regularization feature selection method. As to speech sample reconstruction, a deep sample learning algorithm is designed in this paper based on iterative mean clustering to conduct samples transformation, so as to obtain new high-level deep samples. Finally, the bagging ensemble learning mode is adopted to fuse the deep feature learning algorithm and the deep samples learning algorithm together, thereby constructing a deep double-side learning ensemble model. At the end of this paper, two representative speech datasets of Parkinson's disease were used for verification. The experimental results show that the proposed algorithm are effective.