 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynaFix: Iterative Automated Program Repair Driven by Execution-Level Dynamic Information
Dec 31, 2025Automated Program Repair (APR) aims to automatically generate correct patches for buggy programs. Recent approaches leveraging large language models (LLMs) have shown promise but face limitations. Most rely solely on static analysis, ignoring runtime behaviors. Some attempt to incorporate dynamic signals, but these are often restricted to training or fine-tuning, or injected only once into the repair prompt, without iterative use. This fails to fully capture program execution. Current iterative repair frameworks typically rely on coarse-grained feedback, such as pass/fail results or exception types, and do not leverage fine-grained execution-level information effectively. As a result, models struggle to simulate human stepwise debugging, limiting their effectiveness in multi-step reasoning and complex bug repair. To address these challenges, we propose DynaFix, an execution-level dynamic information-driven APR method that iteratively leverages runtime information to refine the repair process. In each repair round, DynaFix captures execution-level dynamic information such as variable states, control-flow paths, and call stacks, transforming them into structured prompts to guide LLMs in generating candidate patches. If a patch fails validation, DynaFix re-executes the modified program to collect new execution information for the next attempt. This iterative loop incrementally improves patches based on updated feedback, similar to the stepwise debugging practices of human developers. We evaluate DynaFix on the Defects4J v1.2 and v2.0 benchmarks. DynaFix repairs 186 single-function bugs, a 10% improvement over state-of-the-art baselines, including 38 bugs previously unrepaired. It achieves correct patches within at most 35 attempts, reducing the patch search space by 70% compared with existing methods, thereby demonstrating both effectiveness and efficiency in repairing complex bugs.
Taking a Deep Breath: Enhancing Language Modeling of Large Language Models with Sentinel Tokens
Jun 16, 2024



Large language models (LLMs) have shown promising efficacy across various tasks, becoming powerful tools in numerous aspects of human life. However, Transformer-based LLMs suffer a performance degradation when modeling long-term contexts due to they discard some information to reduce computational overhead. In this work, we propose a simple yet effective method to enable LLMs to take a deep breath, encouraging them to summarize information contained within discrete text chunks. Specifically, we segment the text into multiple chunks and insert special token <SR> at the end of each chunk. We then modify the attention mask to integrate the chunk's information into the corresponding <SR> token. This facilitates LLMs to interpret information not only from historical individual tokens but also from the <SR> token, aggregating the chunk's semantic information. Experiments on language modeling and out-of-domain downstream tasks validate the superiority of our approach.
Qsnail: A Questionnaire Dataset for Sequential Question Generation
Feb 22, 2024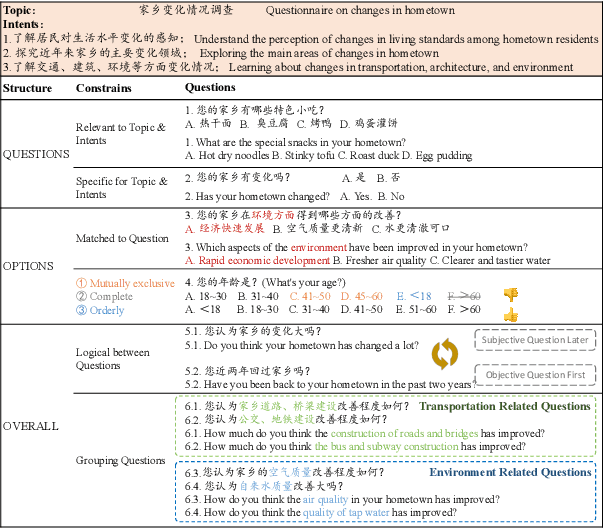

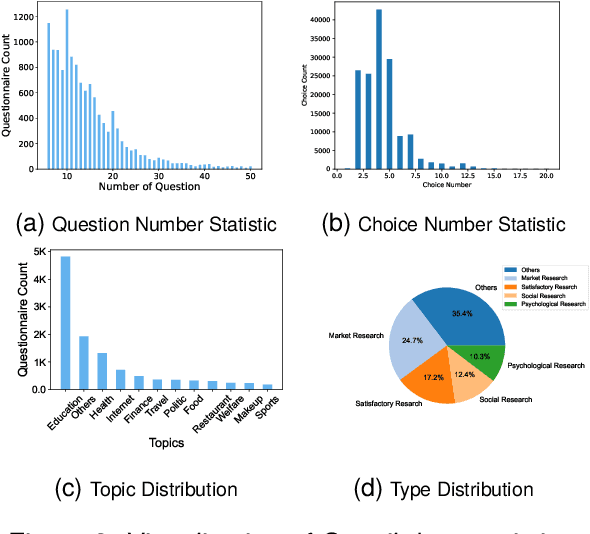
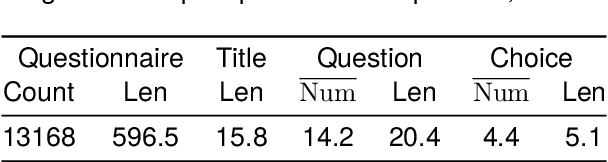
The questionnaire is a professional research methodology used for both qualitative and quantitative analysis of human opinions, preferences, attitudes, and behaviors. However, designing and evaluating questionnaires demands significant effort due to their intricate and complex structure. Questionnaires entail a series of questions that must conform to intricate constraints involving the questions, options, and overall structure. Specifically, the questions should be relevant and specific to the given research topic and intent. The options should be tailored to the questions, ensuring they are mutually exclusive, completed, and ordered sensibly. Moreover, the sequence of questions should follow a logical order, grouping similar topics together. As a result, automatically generating questionnaires presents a significant challenge and this area has received limited attention primarily due to the scarcity of high-quality datasets. To address these issues, we present Qsnail, the first dataset specifically constructed for the questionnaire generation task, which comprises 13,168 human-written questionnaires gathered from online platforms. We further conduct experiments on Qsnail, and the results reveal that retrieval models and traditional generative models do not fully align with the given research topic and intents. Large language models, while more closely related to the research topic and intents, exhibit significant limitations in terms of diversity and specificity. Despite enhancements through the chain-of-thought prompt and finetuning, questionnaires generated by language models still fall short of human-written questionnaires. Therefore, questionnaire generation is challenging and needs to be further explored. The dataset is available at: https://github.com/LeiyanGithub/qsnail.
Deep Double-Side Learning Ensemble Model for Few-Shot Parkinson Speech Recognition
Jun 20, 2020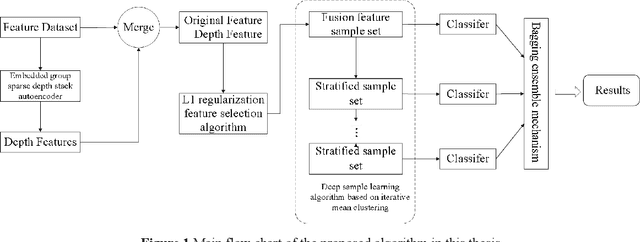

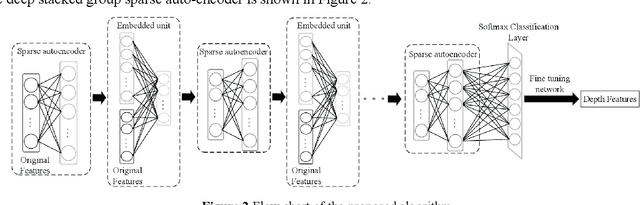

Diagnosis and therapeutic effect assessment of Parkinson disease based on voice data are very important,but its few-shot learning problem is challenging.Although deep learning is good at automatic feature extraction, it suffers from few-shot learning problem. Therefore, the general effective method is first conduct feature extraction based on prior knowledge, and then carry out feature reduction for subsequent classification. However, there are two major problems: 1) Structural information among speech features has not been mined and new features of higher quality have not been reconstructed. 2) Structural information between data samples has not been mined and new samples with higher quality have not been reconstructed. To solve these two problems, based on the existing Parkinson speech feature data set, a deep double-side learning ensemble model is designed in this paper that can reconstruct speech features and samples deeply and simultaneously. As to feature reconstruction, an embedded deep stacked group sparse auto-encoder is designed in this paper to conduct nonlinear feature transformation, so as to acquire new high-level deep features, and then the deep features are fused with original speech features by L1 regularization feature selection method. As to speech sample reconstruction, a deep sample learning algorithm is designed in this paper based on iterative mean clustering to conduct samples transformation, so as to obtain new high-level deep samples. Finally, the bagging ensemble learning mode is adopted to fuse the deep feature learning algorithm and the deep samples learning algorithm together, thereby constructing a deep double-side learning ensemble model. At the end of this paper, two representative speech datasets of Parkinson's disease were used for verification. The experimental results show that the proposed algorithm are effective.
Hybrid Embedded Deep Stacked Sparse Autoencoder with w_LPPD SVM Ensemble
Feb 17, 2020Deep learning is a kind of feature learning method with strong nonliear feature transformation and becomes more and more important in many fields of artificial intelligence. Deep autoencoder is one representative method of the deep learning methods, and can effectively extract abstract the information of datasets. However, it does not consider the complementarity between the deep features and original features during deep feature transformation. Besides, it suffers from small sample problem. In order to solve these problems, a novel deep autoencoder - hybrid feature embedded stacked sparse autoencoder(HESSAE) has been proposed in this paper. HFESAE is capable to learn discriminant deep features with the help of embedding original features to filter weak hidden-layer outputs during training. For the issue that class representation ability of abstract information is limited by small sample problem, a feature fusion strategy has been designed aiming to combining abstract information learned by HFESAE with original feature and obtain hybrid features for feature reduction. The strategy is hybrid feature selection strategy based on L1 regularization followed by an support vector machine(SVM) ensemble model, in which weighted local discriminant preservation projection (w_LPPD), is designed and employed on each base classifier. At the end of this paper, several representative public datasets are used to verify the effectiveness of the proposed algorithm. The experimental results demonstrated that, the proposed feature learning method yields superior performance compared to other existing and state of art feature learning algorithms including some representative deep autoencoder methods.