 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Double-Side Learning Ensemble Model for Few-Shot Parkinson Speech Recognition
Jun 20, 2020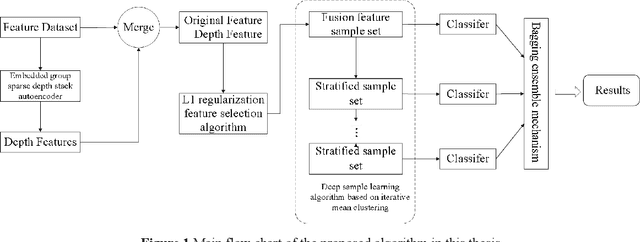

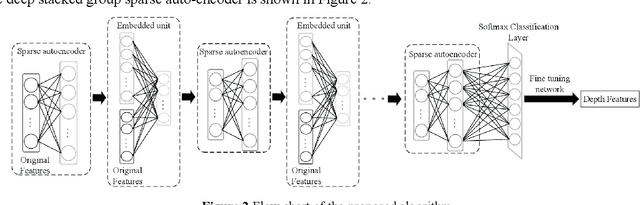

Diagnosis and therapeutic effect assessment of Parkinson disease based on voice data are very important,but its few-shot learning problem is challenging.Although deep learning is good at automatic feature extraction, it suffers from few-shot learning problem. Therefore, the general effective method is first conduct feature extraction based on prior knowledge, and then carry out feature reduction for subsequent classification. However, there are two major problems: 1) Structural information among speech features has not been mined and new features of higher quality have not been reconstructed. 2) Structural information between data samples has not been mined and new samples with higher quality have not been reconstructed. To solve these two problems, based on the existing Parkinson speech feature data set, a deep double-side learning ensemble model is designed in this paper that can reconstruct speech features and samples deeply and simultaneously. As to feature reconstruction, an embedded deep stacked group sparse auto-encoder is designed in this paper to conduct nonlinear feature transformation, so as to acquire new high-level deep features, and then the deep features are fused with original speech features by L1 regularization feature selection method. As to speech sample reconstruction, a deep sample learning algorithm is designed in this paper based on iterative mean clustering to conduct samples transformation, so as to obtain new high-level deep samples. Finally, the bagging ensemble learning mode is adopted to fuse the deep feature learning algorithm and the deep samples learning algorithm together, thereby constructing a deep double-side learning ensemble model. At the end of this paper, two representative speech datasets of Parkinson's disease were used for verification. The experimental results show that the proposed algorithm are effective.
Hybrid Embedded Deep Stacked Sparse Autoencoder with w_LPPD SVM Ensemble
Feb 17, 2020Deep learning is a kind of feature learning method with strong nonliear feature transformation and becomes more and more important in many fields of artificial intelligence. Deep autoencoder is one representative method of the deep learning methods, and can effectively extract abstract the information of datasets. However, it does not consider the complementarity between the deep features and original features during deep feature transformation. Besides, it suffers from small sample problem. In order to solve these problems, a novel deep autoencoder - hybrid feature embedded stacked sparse autoencoder(HESSAE) has been proposed in this paper. HFESAE is capable to learn discriminant deep features with the help of embedding original features to filter weak hidden-layer outputs during training. For the issue that class representation ability of abstract information is limited by small sample problem, a feature fusion strategy has been designed aiming to combining abstract information learned by HFESAE with original feature and obtain hybrid features for feature reduction. The strategy is hybrid feature selection strategy based on L1 regularization followed by an support vector machine(SVM) ensemble model, in which weighted local discriminant preservation projection (w_LPPD), is designed and employed on each base classifier. At the end of this paper, several representative public datasets are used to verify the effectiveness of the proposed algorithm. The experimental results demonstrated that, the proposed feature learning method yields superior performance compared to other existing and state of art feature learning algorithms including some representative deep autoencoder methods.
Classification Algorithm of Speech Data of Parkinsons Disease Based on Convolution Sparse Kernel Transfer Learning with Optimal Kernel and Parallel Sample Feature Selection
Feb 10, 2020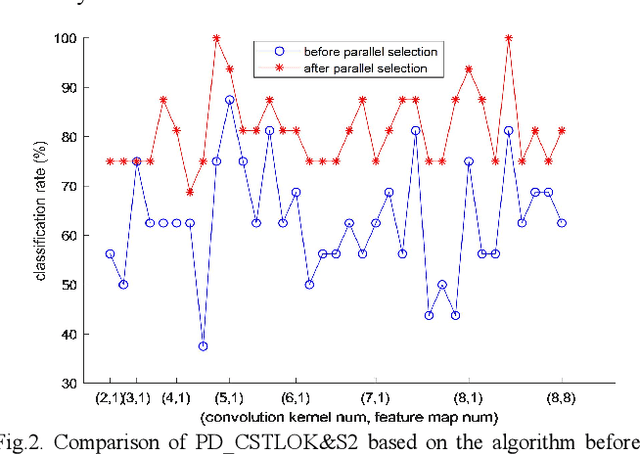
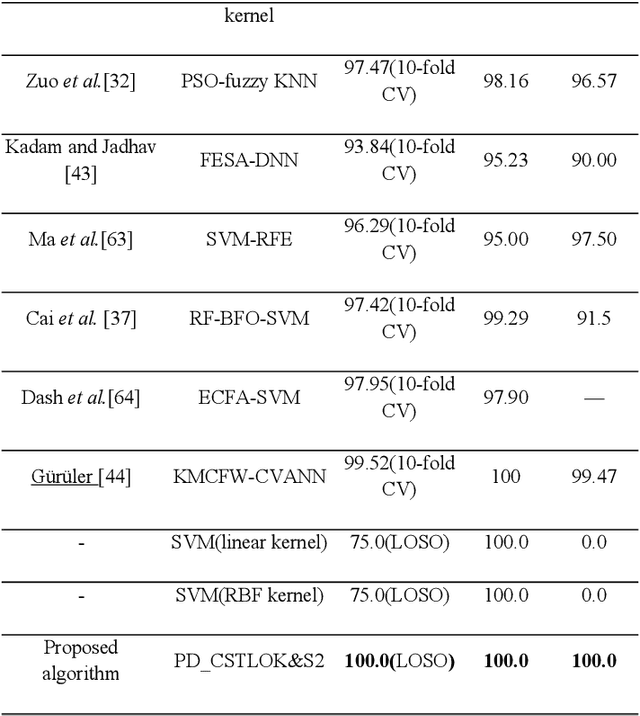
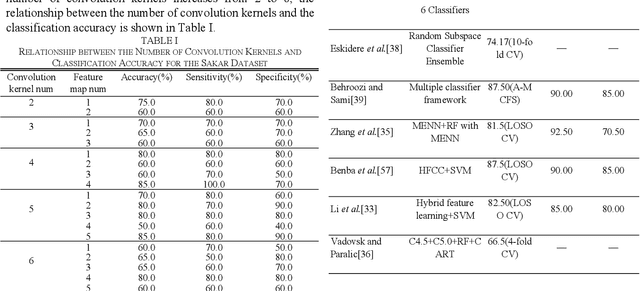

Labeled speech data from patients with Parkinsons disease (PD) are scarce, and the statistical distributions of training and test data differ significantly in the existing datasets. To solve these problems, dimensional reduction and sample augmentation must be considered. In this paper, a novel PD classification algorithm based on sparse kernel transfer learning combined with a parallel optimization of samples and features is proposed. Sparse transfer learning is used to extract effective structural information of PD speech features from public datasets as source domain data, and the fast ADDM iteration is improved to enhance the information extraction performance. To implement the parallel optimization, the potential relationships between samples and features are considered to obtain high-quality combined features. First, features are extracted from a specific public speech dataset to construct a feature dataset as the source domain. Then, the PD target domain, including the training and test datasets, is encoded by convolution sparse coding, which can extract more in-depth information. Next, parallel optimization is implemented. To further improve the classification performance, a convolution kernel optimization mechanism is designed. Using two representative public datasets and one self-constructed dataset, the experiments compare over thirty relevant algorithms. The results show that when taking the Sakar dataset, MaxLittle dataset and DNSH dataset as target domains, the proposed algorithm achieves obvious improvements in classification accuracy. The study also found large improvements in the algorithms in this paper compared with nontransfer learning approaches, demonstrating that transfer learning is both more effective and has a more acceptable time cost.