 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePD-SOVNet: A Physics-Driven Second-Order Vibration Operator Network for Estimating Wheel Polygonal Roughness from Axle-Box Vibrations
Apr 08, 2026Quantitative estimation of wheel polygonal roughness from axle-box vibration signals is a challenging yet practically relevant problem for rail-vehicle condition monitoring. Existing studies have largely focused on detection, identification, or severity classification, while continuous regression of multi-order roughness spectra remains less explored, especially under real operational data and unseen-wheel conditions. To address this problem, this paper presents PD-SOVNet, a physics-guided gray-box framework that combines shared second-order vibration kernels, a $4\times4$ MIMO coupling module, an adaptive physical correction branch, and a Mamba-based temporal branch for estimating the 1st--40th-order wheel roughness spectrum from axle-box vibrations. The proposed design embeds modal-response priors into the model while retaining data-driven flexibility for sample-dependent correction and residual temporal dynamics. Experiments on three real-world datasets, including operational data and real fault data, show that the proposed method provides competitive prediction accuracy and relatively stable cross-wheel performance under the current data protocol, with its most noticeable advantage observed on the more challenging Dataset III. Noise injection experiments further indicate that the Mamba temporal branch helps mitigate performance degradation under perturbed inputs. These results suggest that structured physical priors can be beneficial for stabilizing roughness regression in practical rail-vehicle monitoring scenarios, although further validation under broader operating conditions and stricter comparison protocols is still needed.
A new Stack Autoencoder: Neighbouring Sample Envelope Embedded Stack Autoencoder Ensemble Model
Oct 25, 2022
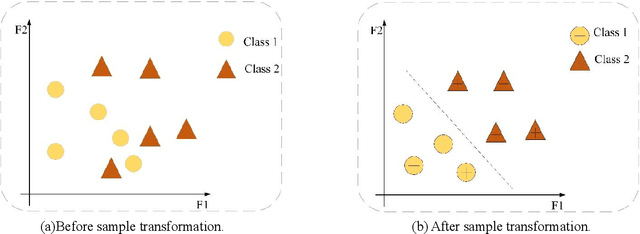

Stack autoencoder (SAE), as a representative deep network, has unique and excellent performance in feature learning, and has received extensive attention from researchers. However, existing deep SAEs focus on original samples without considering the hierarchical structural information between samples. To address this limitation, this paper proposes a new SAE model-neighbouring envelope embedded stack autoencoder ensemble (NE_ESAE). Firstly, the neighbouring sample envelope learning mechanism (NSELM) is proposed for preprocessing of input of SAE. NSELM constructs sample pairs by combining neighbouring samples. Besides, the NSELM constructs a multilayer sample spaces by multilayer iterative mean clustering, which considers the similar samples and generates layers of envelope samples with hierarchical structural information. Second, an embedded stack autoencoder (ESAE) is proposed and trained in each layer of sample space to consider the original samples during training and in the network structure, thereby better finding the relationship between original feature samples and deep feature samples. Third, feature reduction and base classifiers are conducted on the layers of envelope samples respectively, and output classification results of every layer of samples. Finally, the classification results of the layers of envelope sample space are fused through the ensemble mechanism. In the experimental section, the proposed algorithm is validated with over ten representative public datasets. The results show that our method significantly has better performance than existing traditional feature learning methods and the representative deep autoencoders.
Envelope imbalanced ensemble model with deep sample learning and local-global structure consistency
Jun 25, 2022

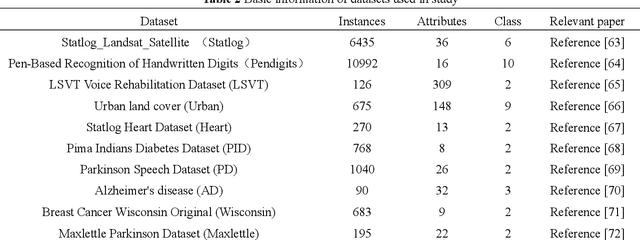
The class imbalance problem is important and challenging. Ensemble approaches are widely used to tackle this problem because of their effectiveness. However, existing ensemble methods are always applied into original samples, while not considering the structure information among original samples. The limitation will prevent the imbalanced learning from being better. Besides, research shows that the structure information among samples includes local and global structure information. Based on the analysis above, an imbalanced ensemble algorithm with the deep sample pre-envelope network (DSEN) and local-global structure consistency mechanism (LGSCM) is proposed here to solve the problem.This algorithm can guarantee high-quality deep envelope samples for considering the local manifold and global structures information, which is helpful for imbalance learning. First, the deep sample envelope pre-network (DSEN) is designed to mine structure information among samples.Then, the local manifold structure metric (LMSM) and global structure distribution metric (GSDM) are designed to construct LGSCM to enhance distribution consistency of interlayer samples. Next, the DSEN and LGSCM are put together to form the final deep sample envelope network (DSEN-LG). After that, base classifiers are applied on the layers of deep samples respectively.Finally, the predictive results from base classifiers are fused through bagging ensemble learning mechanism. To demonstrate the effectiveness of the proposed method, forty-four public datasets and more than ten representative relevant algorithms are chosen for verification. The experimental results show that the algorithm is significantly better than other imbalanced ensemble algorithms.
Subject Enveloped Deep Sample Fuzzy Ensemble Learning Algorithm of Parkinson's Speech Data
Nov 17, 2021
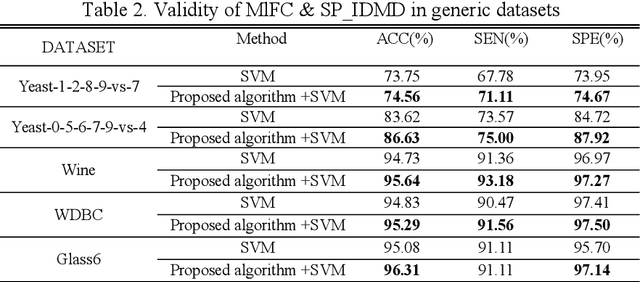

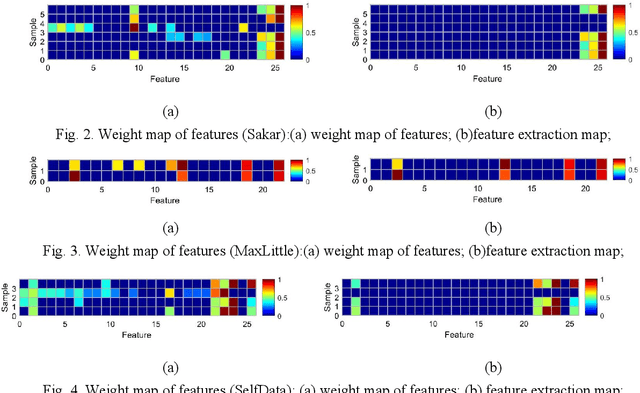
Parkinson disease (PD)'s speech recognition is an effective way for its diagnosis, which has become a hot and difficult research area in recent years. As we know, there are large corpuses (segments) within one subject. However, too large segments will increase the complexity of the classification model. Besides, the clinicians interested in finding diagnostic speech markers that reflect the pathology of the whole subject. Since the optimal relevant features of each speech sample segment are different, it is difficult to find the uniform diagnostic speech markers. Therefore, it is necessary to reconstruct the existing large segments within one subject into few segments even one segment within one subject, which can facilitate the extraction of relevant speech features to characterize diagnostic markers for the whole subject. To address this problem, an enveloped deep speech sample learning algorithm for Parkinson's subjects based on multilayer fuzzy c-mean (MlFCM) clustering and interlayer consistency preservation is proposed in this paper. The algorithm can be used to achieve intra-subject sample reconstruction for Parkinson's disease (PD) to obtain a small number of high-quality prototype sample segments. At the end of the paper, several representative PD speech datasets are selected and compared with the state-of-the-art related methods, respectively. The experimental results show that the proposed algorithm is effective signifcantly.
Envelope Imbalance Learning Algorithm based on Multilayer Fuzzy C-means Clustering and Minimum Interlayer discrepancy
Nov 02, 2021

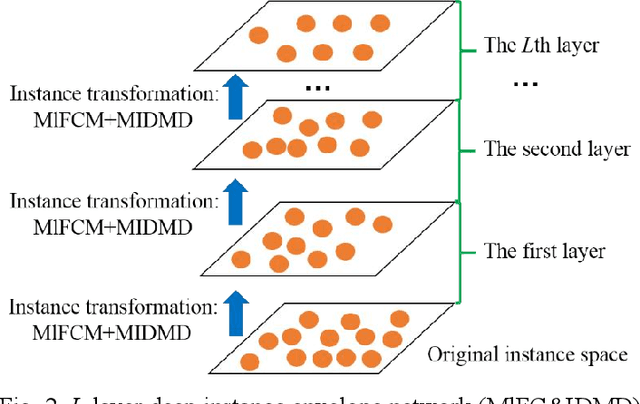
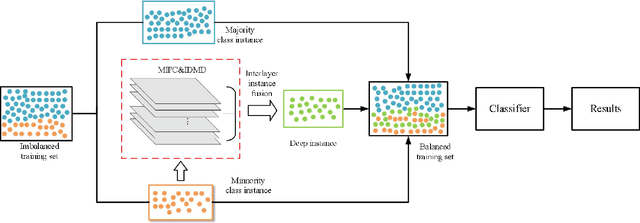
Imbalanced learning is important and challenging since the problem of the classification of imbalanced datasets is prevalent in machine learning and data mining fields. Sampling approaches are proposed to address this issue, and cluster-based oversampling methods have shown great potential as they aim to simultaneously tackle between-class and within-class imbalance issues. However, all existing clustering methods are based on a one-time approach. Due to the lack of a priori knowledge, improper setting of the number of clusters often exists, which leads to poor clustering performance. Besides, the existing methods are likely to generate noisy instances. To solve these problems, this paper proposes a deep instance envelope network-based imbalanced learning algorithm with the multilayer fuzzy c-means (MlFCM) and a minimum interlayer discrepancy mechanism based on the maximum mean discrepancy (MIDMD). This algorithm can guarantee high quality balanced instances using a deep instance envelope network in the absence of prior knowledge. In the experimental section, thirty-three popular public datasets are used for verification, and over ten representative algorithms are used for comparison. The experimental results show that the proposed approach significantly outperforms other popular methods.
Classification Algorithm of Speech Data of Parkinsons Disease Based on Convolution Sparse Kernel Transfer Learning with Optimal Kernel and Parallel Sample Feature Selection
Feb 10, 2020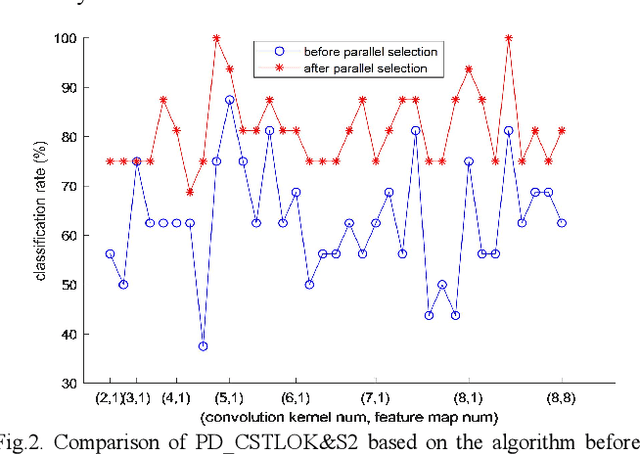
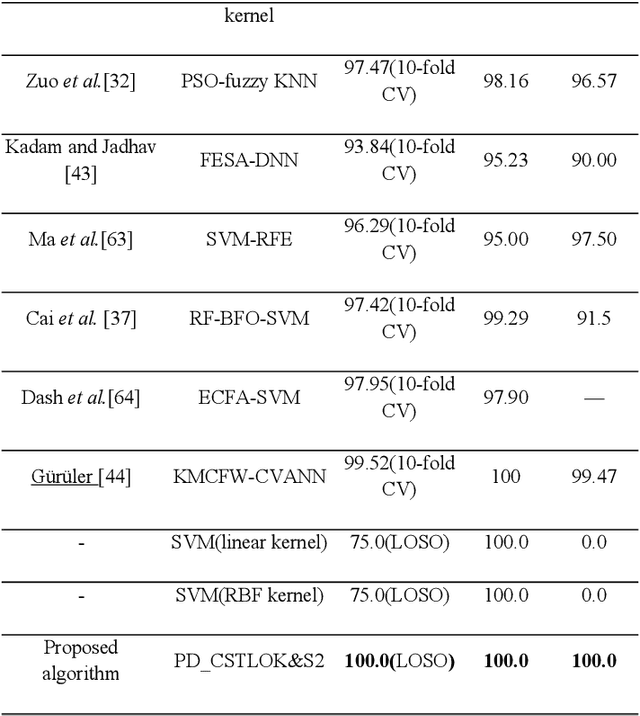
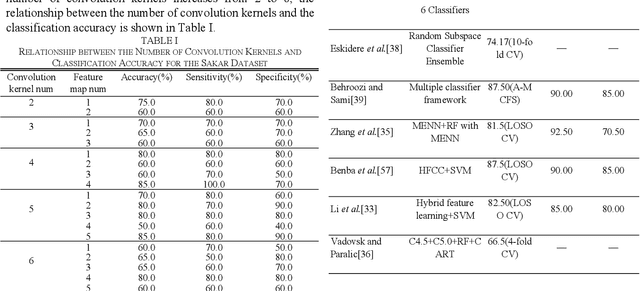

Labeled speech data from patients with Parkinsons disease (PD) are scarce, and the statistical distributions of training and test data differ significantly in the existing datasets. To solve these problems, dimensional reduction and sample augmentation must be considered. In this paper, a novel PD classification algorithm based on sparse kernel transfer learning combined with a parallel optimization of samples and features is proposed. Sparse transfer learning is used to extract effective structural information of PD speech features from public datasets as source domain data, and the fast ADDM iteration is improved to enhance the information extraction performance. To implement the parallel optimization, the potential relationships between samples and features are considered to obtain high-quality combined features. First, features are extracted from a specific public speech dataset to construct a feature dataset as the source domain. Then, the PD target domain, including the training and test datasets, is encoded by convolution sparse coding, which can extract more in-depth information. Next, parallel optimization is implemented. To further improve the classification performance, a convolution kernel optimization mechanism is designed. Using two representative public datasets and one self-constructed dataset, the experiments compare over thirty relevant algorithms. The results show that when taking the Sakar dataset, MaxLittle dataset and DNSH dataset as target domains, the proposed algorithm achieves obvious improvements in classification accuracy. The study also found large improvements in the algorithms in this paper compared with nontransfer learning approaches, demonstrating that transfer learning is both more effective and has a more acceptable time cost.