 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubject Enveloped Deep Sample Fuzzy Ensemble Learning Algorithm of Parkinson's Speech Data
Paper and Code
Nov 17, 2021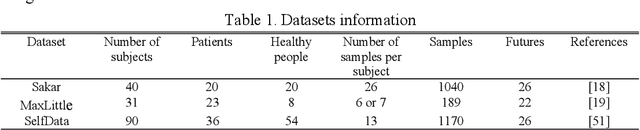
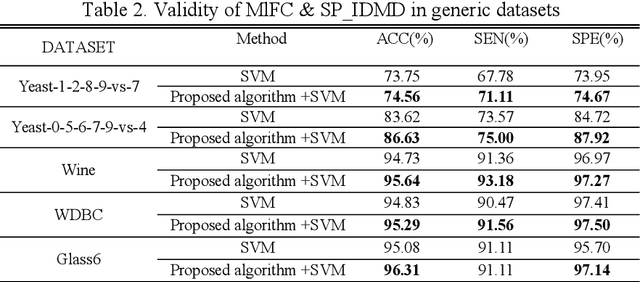

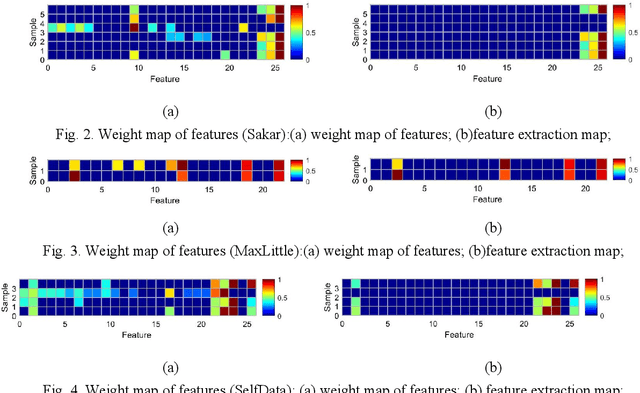
Parkinson disease (PD)'s speech recognition is an effective way for its diagnosis, which has become a hot and difficult research area in recent years. As we know, there are large corpuses (segments) within one subject. However, too large segments will increase the complexity of the classification model. Besides, the clinicians interested in finding diagnostic speech markers that reflect the pathology of the whole subject. Since the optimal relevant features of each speech sample segment are different, it is difficult to find the uniform diagnostic speech markers. Therefore, it is necessary to reconstruct the existing large segments within one subject into few segments even one segment within one subject, which can facilitate the extraction of relevant speech features to characterize diagnostic markers for the whole subject. To address this problem, an enveloped deep speech sample learning algorithm for Parkinson's subjects based on multilayer fuzzy c-mean (MlFCM) clustering and interlayer consistency preservation is proposed in this paper. The algorithm can be used to achieve intra-subject sample reconstruction for Parkinson's disease (PD) to obtain a small number of high-quality prototype sample segments. At the end of the paper, several representative PD speech datasets are selected and compared with the state-of-the-art related methods, respectively. The experimental results show that the proposed algorithm is effective signifcantly.