 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMSAVBench: Towards Comprehensive and Reliable Evaluation of Multi-Shot Audio-Video Generation
May 19, 2026Video generation is rapidly evolving from single-shot synthesis to complex multi-shot audio-video (MSAV) narratives to meet real-world demands. However, evaluating such frontier models remains a fundamental challenge. Existing benchmarks are limited in scope and data diversity, and rely on rigid evaluation pipelines, preventing systematic and reliable assessment of modern MSAV models. To bridge these gaps, we introduce MSAVBench, the first comprehensive benchmark and adaptive hybrid evaluation framework for multi-shot audio-video generation. Our benchmark spans four key dimensions, video, audio, shot, and reference, covering diverse task settings, varying shot counts of up to 15, and challenging non-realistic scenarios. Our evaluation framework improves robustness through an adaptive self-correction mechanism for shot segmentation, instance-wise rubrics for subjective metrics, and tool-grounded evidence extraction for complex judgments. Furthermore, MSAVBench achieves high alignment with human judgments, reaching a Spearman rank correlation of 91.5%. Our systematic evaluation of 19 state-of-the-art closed- and open-source models shows that current systems still struggle with director-level control and fine-grained audio-visual synchronization, while modular or agentic generation pipelines offer a promising path toward narrowing the gap between open- and closed-source models. We will release the benchmark data and evaluation code to facilitate future research.
Skill-Evolving Grounded Reasoning for Free-Text Promptable 3D Medical Image Segmentation
Mar 09, 2026Free-text promptable 3D medical image segmentation offers an intuitive and clinically flexible interaction paradigm. However, current methods are highly sensitive to linguistic variability: minor changes in phrasing can cause substantial performance degradation despite identical clinical intent. Existing approaches attempt to improve robustness through stronger vision-language fusion or larger vocabularies, yet they lack mechanisms to consistently align ambiguous free-form expressions with anatomically grounded representations. We propose Skill-Evolving grounded Reasoning (SEER), a novel framework for free-text promptable 3D medical image segmentation that explicitly bridges linguistic variability and anatomical precision through a reasoning-driven design. First, we curate the SEER-Trace dataset, which pairs raw clinical requests with image-grounded, skill-tagged reasoning traces, establishing a reproducible benchmark. Second, SEER constructs an evidence-aligned target representation via a vision-language reasoning chain that verifies clinical intent against image-derived anatomical evidence, thereby enforcing semantic consistency before voxel-level decoding. Third, we introduce SEER-Loop, a dynamic skill-evolving strategy that distills high-reward reasoning trajectories into reusable skill artifacts and progressively integrates them into subsequent inference, enabling structured self-refinement and improved robustness to diverse linguistic expressions. Extensive experiments demonstrate superior performance of SEER over state-of-the-art baselines. Under linguistic perturbations, SEER reduces performance variance by 81.94% and improves worst-case Dice by 18.60%.
Drug classification based on X-ray spectroscopy combined with machine learning
May 04, 2025The proliferation of new types of drugs necessitates the urgent development of faster and more accurate detection methods. Traditional detection methods have high requirements for instruments and environments, making the operation complex. X-ray absorption spectroscopy, a non-destructive detection technique, offers advantages such as ease of operation, penetrative observation, and strong substance differentiation capabilities, making it well-suited for application in the field of drug detection and identification. In this study, we constructed a classification model using Convolutional Neural Networks (CNN), Support Vector Machines (SVM), and Particle Swarm Optimization (PSO) to classify and identify drugs based on their X-ray spectral profiles. In the experiments, we selected 14 chemical reagents with chemical formulas similar to drugs as samples. We utilized CNN to extract features from the spectral data of these 14 chemical reagents and used the extracted features to train an SVM model. We also utilized PSO to optimize two critical initial parameters of the SVM. The experimental results demonstrate that this model achieved higher classification accuracy compared to two other common methods, with a prediction accuracy of 99.14%. Additionally, the model exhibited fast execution speed, mitigating the drawback of a drastic increase in running time and efficiency reduction that may result from the direct fusion of PSO and SVM. Therefore, the combined approach of X-ray absorption spectroscopy with CNN, PSO, and SVM provides a rapid, highly accurate, and reliable classification and identification method for the field of drug detection, holding promising prospects for widespread application.
AMNet: An Acoustic Model Network for Enhanced Mandarin Speech Synthesis
Apr 12, 2025



This paper presents AMNet, an Acoustic Model Network designed to improve the performance of Mandarin speech synthesis by incorporating phrase structure annotation and local convolution modules. AMNet builds upon the FastSpeech 2 architecture while addressing the challenge of local context modeling, which is crucial for capturing intricate speech features such as pauses, stress, and intonation. By embedding a phrase structure parser into the model and introducing a local convolution module, AMNet enhances the model's sensitivity to local information. Additionally, AMNet decouples tonal characteristics from phonemes, providing explicit guidance for tone modeling, which improves tone accuracy and pronunciation. Experimental results demonstrate that AMNet outperforms baseline models in subjective and objective evaluations. The proposed model achieves superior Mean Opinion Scores (MOS), lower Mel Cepstral Distortion (MCD), and improved fundamental frequency fitting $F0 (R^2)$, confirming its ability to generate high-quality, natural, and expressive Mandarin speech.
BadRefSR: Backdoor Attacks Against Reference-based Image Super Resolution
Feb 28, 2025Reference-based image super-resolution (RefSR) represents a promising advancement in super-resolution (SR). In contrast to single-image super-resolution (SISR), RefSR leverages an additional reference image to help recover high-frequency details, yet its vulnerability to backdoor attacks has not been explored. To fill this research gap, we propose a novel attack framework called BadRefSR, which embeds backdoors in the RefSR model by adding triggers to the reference images and training with a mixed loss function. Extensive experiments across various backdoor attack settings demonstrate the effectiveness of BadRefSR. The compromised RefSR network performs normally on clean input images, while outputting attacker-specified target images on triggered input images. Our study aims to alert researchers to the potential backdoor risks in RefSR. Codes are available at https://github.com/xuefusiji/BadRefSR.
VNet: A GAN-based Multi-Tier Discriminator Network for Speech Synthesis Vocoders
Aug 13, 2024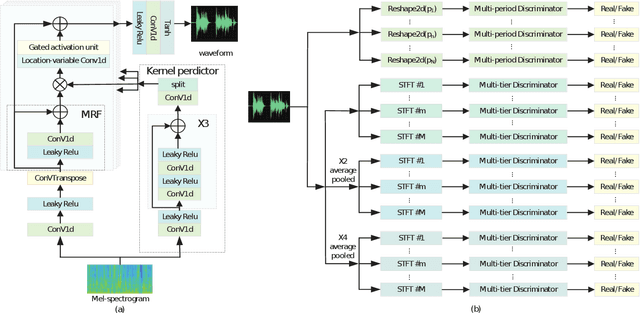
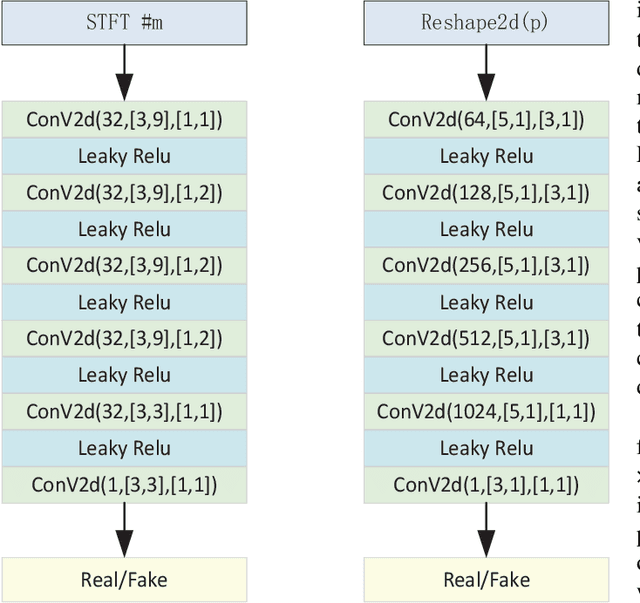
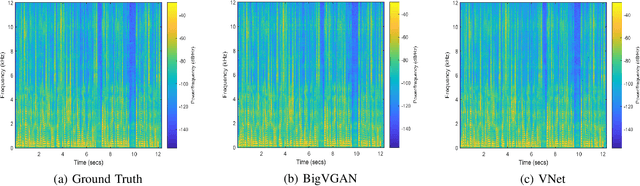

Since the introduction of Generative Adversarial Networks (GANs) in speech synthesis, remarkable achievements have been attained. In a thorough exploration of vocoders, it has been discovered that audio waveforms can be generated at speeds exceeding real-time while maintaining high fidelity, achieved through the utilization of GAN-based models. Typically, the inputs to the vocoder consist of band-limited spectral information, which inevitably sacrifices high-frequency details. To address this, we adopt the full-band Mel spectrogram information as input, aiming to provide the vocoder with the most comprehensive information possible. However, previous studies have revealed that the use of full-band spectral information as input can result in the issue of over-smoothing, compromising the naturalness of the synthesized speech. To tackle this challenge, we propose VNet, a GAN-based neural vocoder network that incorporates full-band spectral information and introduces a Multi-Tier Discriminator (MTD) comprising multiple sub-discriminators to generate high-resolution signals. Additionally, we introduce an asymptotically constrained method that modifies the adversarial loss of the generator and discriminator, enhancing the stability of the training process. Through rigorous experiments, we demonstrate that the VNet model is capable of generating high-fidelity speech and significantly improving the performance of the vocoder.
The Ninth NTIRE 2024 Efficient Super-Resolution Challenge Report
Apr 16, 2024



This paper provides a comprehensive review of the NTIRE 2024 challenge, focusing on efficient single-image super-resolution (ESR) solutions and their outcomes. The task of this challenge is to super-resolve an input image with a magnification factor of x4 based on pairs of low and corresponding high-resolution images. The primary objective is to develop networks that optimize various aspects such as runtime, parameters, and FLOPs, while still maintaining a peak signal-to-noise ratio (PSNR) of approximately 26.90 dB on the DIV2K_LSDIR_valid dataset and 26.99 dB on the DIV2K_LSDIR_test dataset. In addition, this challenge has 4 tracks including the main track (overall performance), sub-track 1 (runtime), sub-track 2 (FLOPs), and sub-track 3 (parameters). In the main track, all three metrics (ie runtime, FLOPs, and parameter count) were considered. The ranking of the main track is calculated based on a weighted sum-up of the scores of all other sub-tracks. In sub-track 1, the practical runtime performance of the submissions was evaluated, and the corresponding score was used to determine the ranking. In sub-track 2, the number of FLOPs was considered. The score calculated based on the corresponding FLOPs was used to determine the ranking. In sub-track 3, the number of parameters was considered. The score calculated based on the corresponding parameters was used to determine the ranking. RLFN is set as the baseline for efficiency measurement. The challenge had 262 registered participants, and 34 teams made valid submissions. They gauge the state-of-the-art in efficient single-image super-resolution. To facilitate the reproducibility of the challenge and enable other researchers to build upon these findings, the code and the pre-trained model of validated solutions are made publicly available at https://github.com/Amazingren/NTIRE2024_ESR/.
Synergizing Human-AI Agency: A Guide of 23 Heuristics for Service Co-Creation with LLM-Based Agents
Oct 23, 2023



This empirical study serves as a primer for interested service providers to determine if and how Large Language Models (LLMs) technology will be integrated for their practitioners and the broader community. We investigate the mutual learning journey of non-AI experts and AI through CoAGent, a service co-creation tool with LLM-based agents. Engaging in a three-stage participatory design processes, we work with with 23 domain experts from public libraries across the U.S., uncovering their fundamental challenges of integrating AI into human workflows. Our findings provide 23 actionable "heuristics for service co-creation with AI", highlighting the nuanced shared responsibilities between humans and AI. We further exemplar 9 foundational agency aspects for AI, emphasizing essentials like ownership, fair treatment, and freedom of expression. Our innovative approach enriches the participatory design model by incorporating AI as crucial stakeholders and utilizing AI-AI interaction to identify blind spots. Collectively, these insights pave the way for synergistic and ethical human-AI co-creation in service contexts, preparing for workforce ecosystems where AI coexists.
Health Monitoring of Movement Disorder Subject based on Diamond Stacked Sparse Autoencoder Ensemble Model
Mar 15, 2023



The health monitoring of chronic diseases is very important for people with movement disorders because of their limited mobility and long duration of chronic diseases. Machine learning-based processing of data collected from the human with movement disorders using wearable sensors is an effective method currently available for health monitoring. However, wearable sensor systems are difficult to obtain high-quality and large amounts of data, which cannot meet the requirement for diagnostic accuracy. Moreover, existing machine learning methods do not handle this problem well. Feature learning is key to machine learning. To solve this problem, a health monitoring of movement disorder subject based on diamond stacked sparse autoencoder ensemble model (DsaeEM) is proposed in this paper. This algorithm has two major components. First, feature expansion is designed using feature-embedded stacked sparse autoencoder (FSSAE). Second, a feature reduction mechanism is designed to remove the redundancy among the expanded features. This mechanism includes L1 regularized feature-reduction algorithm and the improved manifold dimensionality reduction algorithm. This paper refers to the combined feature expansion and feature reduction mechanism as the diamond-like feature learning mechanism. The method is experimentally verified with several state of art algorithms and on two datasets. The results show that the proposed algorithm has higher accuracy apparently. In conclusion, this study developed an effective and feasible feature-learning algorithm for the recognition of chronic diseases.
Overlapping oriented imbalanced ensemble learning method based on projective clustering and stagewise hybrid sampling
Nov 30, 2022



The challenge of imbalanced learning lies not only in class imbalance problem, but also in the class overlapping problem which is complex. However, most of the existing algorithms mainly focus on the former. The limitation prevents the existing methods from breaking through. To address this limitation, this paper proposes an ensemble learning algorithm based on dual clustering and stage-wise hybrid sampling (DCSHS). The DCSHS has three parts. Firstly, we design a projection clustering combination framework (PCC) guided by Davies-Bouldin clustering effectiveness index (DBI), which is used to obtain high-quality clusters and combine them to obtain a set of cross-complete subsets (CCS) with balanced class and low overlapping. Secondly, according to the characteristics of subset classes, a stage-wise hybrid sampling algorithm is designed to realize the de-overlapping and balancing of subsets. Finally, a projective clustering transfer mapping mechanism (CTM) is constructed for all processed subsets by means of transfer learning, thereby reducing class overlapping and explore structure information of samples. The major advantage of our algorithm is that it can exploit the intersectionality of the CCS to realize the soft elimination of overlapping majority samples, and learn as much information of overlapping samples as possible, thereby enhancing the class overlapping while class balancing. In the experimental section, more than 30 public datasets and over ten representative algorithms are chosen for verification. The experimental results show that the DCSHS is significantly best in terms of various evaluation criteria.