 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAMNet: An Acoustic Model Network for Enhanced Mandarin Speech Synthesis
Apr 12, 2025This paper presents AMNet, an Acoustic Model Network designed to improve the performance of Mandarin speech synthesis by incorporating phrase structure annotation and local convolution modules. AMNet builds upon the FastSpeech 2 architecture while addressing the challenge of local context modeling, which is crucial for capturing intricate speech features such as pauses, stress, and intonation. By embedding a phrase structure parser into the model and introducing a local convolution module, AMNet enhances the model's sensitivity to local information. Additionally, AMNet decouples tonal characteristics from phonemes, providing explicit guidance for tone modeling, which improves tone accuracy and pronunciation. Experimental results demonstrate that AMNet outperforms baseline models in subjective and objective evaluations. The proposed model achieves superior Mean Opinion Scores (MOS), lower Mel Cepstral Distortion (MCD), and improved fundamental frequency fitting $F0 (R^2)$, confirming its ability to generate high-quality, natural, and expressive Mandarin speech.
VNet: A GAN-based Multi-Tier Discriminator Network for Speech Synthesis Vocoders
Aug 13, 2024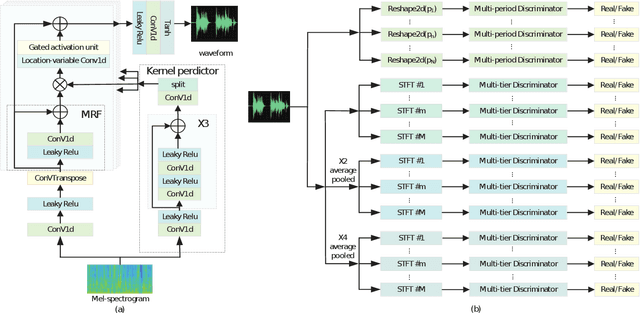
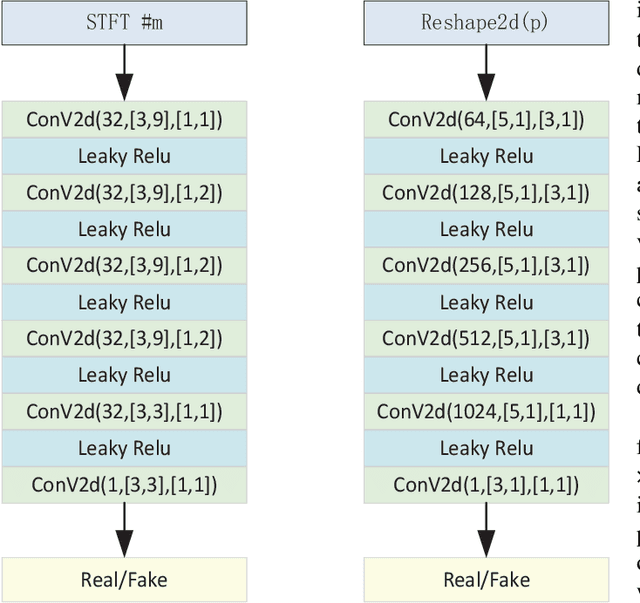
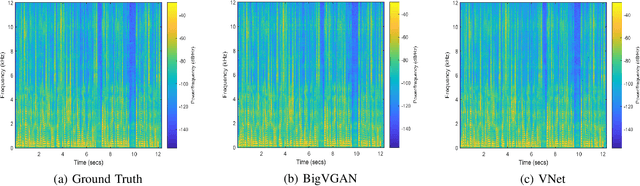

Since the introduction of Generative Adversarial Networks (GANs) in speech synthesis, remarkable achievements have been attained. In a thorough exploration of vocoders, it has been discovered that audio waveforms can be generated at speeds exceeding real-time while maintaining high fidelity, achieved through the utilization of GAN-based models. Typically, the inputs to the vocoder consist of band-limited spectral information, which inevitably sacrifices high-frequency details. To address this, we adopt the full-band Mel spectrogram information as input, aiming to provide the vocoder with the most comprehensive information possible. However, previous studies have revealed that the use of full-band spectral information as input can result in the issue of over-smoothing, compromising the naturalness of the synthesized speech. To tackle this challenge, we propose VNet, a GAN-based neural vocoder network that incorporates full-band spectral information and introduces a Multi-Tier Discriminator (MTD) comprising multiple sub-discriminators to generate high-resolution signals. Additionally, we introduce an asymptotically constrained method that modifies the adversarial loss of the generator and discriminator, enhancing the stability of the training process. Through rigorous experiments, we demonstrate that the VNet model is capable of generating high-fidelity speech and significantly improving the performance of the vocoder.