 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeML-SAN: Multi-Level Speaker-Adaptive Network for Emotion Recognition in Conversations
Apr 28, 2026To establish empathy with machines, it is essential to fully understand human emotional changes. However, research in multimodal emotion recognition often overlooks one problem: individual expressive traits vary significantly, which means that different people may express emotions differently. In our daily lives, we can see this. When communicating with different people, some express "happiness" through their facial expressions and words, while others may hide their happiness or express it through their actions. Both are expressions of 'happiness,' but such differences in emotional expression are still too difficult for machines to distinguish. Current emotion recognition remains at a 'static' level, using a single recognition model to identify all emotional styles. This "simplification" often affects the recognition results, especially in multi-turn dialogues. To address this problem, this paper introduces a novel Multi-Level Speaker Adaptive Network (ML-SAN), which, specifically, effectively addresses the challenge of speaker identity information confusion. ML-SAN does not simply assign a speaker's ID after recognition; instead, it employs a three-stage adaptive process: First, Input-level Calibration uses Feature-Level Linear Modulation (FiLM) to adjust the raw audio and visual features into a neutral space unrelated to the speaker. Then, Interaction-level Gating re-adjusts the trust level for each modality (e.g., voice or facial features) based on the speaker's identity information. Finally, Output-level Regularization maintains the consistency of speaker features in the latent space. Tests on the MELD and IEMOCAP datasets show that our model (ML-SAN) achieves better results, performs exceptionally well in handling challenging tail sentiment categories, and better addresses the diversity of speakers in real-world scenarios.
EAD-Net: Emotion-Aware Talking Head Generation with Spatial Refinement and Temporal Coherence
Apr 25, 2026Emotionally talking head video generation aims to generate expressive portrait videos with accurate lip synchronization and emotional facial expressions. Current methods rely on simple emotional labels, leading to insufficient semantic information. While introducing high-level semantics enhances expressiveness, it easily causes lip-sync degradation. Furthermore, mainstream generation methods struggle to balance computational efficiency and global motion awareness in long videos and suffer from poor temporal coherence. Therefore, we propose an \textbf{E}motion-\textbf{A}ware \textbf{D}iffusion model-based \textbf{Net}work, called \textbf{EAD-Net}. We introduce SyncNet supervision and Temporal Representation Alignment (TREPA) to mitigate lip-sync degradation caused by multi-modal fusion. To model complex spatio-temporal dependencies in long video sequences, we propose a Spatio-Temporal Directional Attention (STDA) mechanism that captures global motion patterns through strip attention. Additionally, we design a Temporal Frame graph Reasoning Module (TFRM) to explicitly model temporal coherence between video frames through graph structure learning. To enhance emotional semantic control, a large language model is employed to extract textual descriptions from real videos, serving as high-level semantic guidance. Experiments on the HDTF and MEAD datasets demonstrate that our method outperforms existing methods in terms of lip-sync accuracy, temporal consistency, and emotional accuracy.
Semantic-Emotional Resonance Embedding: A Semi-Supervised Paradigm for Cross-Lingual Speech Emotion Recognition
Apr 08, 2026Cross-lingual Speech Emotion Recognition (CLSER) aims to identify emotional states in unseen languages. However, existing methods heavily rely on the semantic synchrony of complete labels and static feature stability, hindering low-resource languages from reaching high-resource performance. To address this, we propose a semi-supervised framework based on Semantic-Emotional Resonance Embedding (SERE), a cross-lingual dynamic feature paradigm that requires neither target language labels nor translation alignment. Specifically, SERE constructs an emotion-semantic structure using a small number of labeled samples. It learns human emotional experiences through an Instantaneous Resonance Field (IRF), enabling unlabeled samples to self-organize into this structure. This achieves semi-supervised semantic guidance and structural discovery. Additionally, we design a Triple-Resonance Interaction Chain (TRIC) loss to enable the model to reinforce the interaction and embedding capabilities between labeled and unlabeled samples during emotional highlights. Extensive experiments across multiple languages demonstrate the effectiveness of our method, requiring only 5-shot labeling in the source language.
Generalizable Audio-Visual Navigation via Binaural Difference Attention and Action Transition Prediction
Apr 06, 2026In Audio-Visual Navigation (AVN), agents must locate sound sources in unseen 3D environments using visual and auditory cues. However, existing methods often struggle with generalization in unseen scenarios, as they tend to overfit to semantic sound features and specific training environments. To address these challenges, we propose the \textbf{Binaural Difference Attention with Action Transition Prediction (BDATP)} framework, which jointly optimizes perception and policy. Specifically, the \textbf{Binaural Difference Attention (BDA)} module explicitly models interaural differences to enhance spatial orientation, reducing reliance on semantic categories. Simultaneously, the \textbf{Action Transition Prediction (ATP)} task introduces an auxiliary action prediction objective as a regularization term, mitigating environment-specific overfitting. Extensive experiments on the Replica and Matterport3D datasets demonstrate that BDATP can be seamlessly integrated into various mainstream baselines, yielding consistent and significant performance gains. Notably, our framework achieves state-of-the-art Success Rates across most settings, with a remarkable absolute improvement of up to 21.6 percentage points in Replica dataset for unheard sounds. These results underscore BDATP's superior generalization capability and its robustness across diverse navigation architectures.
Reliability-Aware Geometric Fusion for Robust Audio-Visual Navigation
Apr 02, 2026Audio-Visual Navigation (AVN) requires an embodied agent to navigate toward a sound source by utilizing both vision and binaural audio. A core challenge arises in complex acoustic environments, where binaural cues become intermittently unreliable, particularly when generalizing to previously unheard sound categories. To address this, we propose RAVN (Reliability-Aware Audio-Visual Navigation), a framework that conditions cross-modal fusion on audio-derived reliability cues, dynamically calibrating the integration of audio and visual inputs. RAVN introduces an Acoustic Geometry Reasoner (AGR) that is trained with geometric proxy supervision. Using a heteroscedastic Gaussian NLL objective, AGR learns observation-dependent dispersion as a practical reliability cue, eliminating the need for geometric labels during inference. Additionally, we introduce Reliability-Aware Geometric Modulation (RAGM), which converts the learned cue into a soft gate to modulate visual features, thereby mitigating cross-modal conflicts. We evaluate RAVN on SoundSpaces using both Replica and Matterport3D environments, and the results show consistent improvements in navigation performance, with notable robustness in the challenging unheard sound setting.
Spatial-Aware Conditioned Fusion for Audio-Visual Navigation
Apr 02, 2026Audio-visual navigation tasks require agents to locate and navigate toward continuously vocalizing targets using only visual observations and acoustic cues. However, existing methods mainly rely on simple feature concatenation or late fusion, and lack an explicit discrete representation of the target's relative position, which limits learning efficiency and generalization. We propose Spatial-Aware Conditioned Fusion (SACF). SACF first discretizes the target's relative direction and distance from audio-visual cues, predicts their distributions, and encodes them as a compact descriptor for policy conditioning and state modeling. Then, SACF uses audio embeddings and spatial descriptors to generate channel-wise scaling and bias to modulate visual features via conditional linear transformation, producing target-oriented fused representations. SACF improves navigation efficiency with lower computational overhead and generalizes well to unheard target sounds.
Audio Spatially-Guided Fusion for Audio-Visual Navigation
Apr 02, 2026Audio-visual Navigation refers to an agent utilizing visual and auditory information in complex 3D environments to accomplish target localization and path planning, thereby achieving autonomous navigation. The core challenge of this task lies in the following: how the agent can break free from the dependence on training data and achieve autonomous navigation with good generalization performance when facing changes in environments and sound sources. To address this challenge, we propose an Audio Spatially-Guided Fusion for Audio-Visual Navigation method. First, we design an audio spatial feature encoder, which adaptively extracts target-related spatial state information through an audio intensity attention mechanism; based on this, we introduce an Audio Spatial State Guided Fusion (ASGF) to achieve dynamic alignment and adaptive fusion of multimodal features, effectively alleviating noise interference caused by perceptual uncertainty. Experimental results on the Replica and Matterport3D datasets indicate that our method is particularly effective on unheard tasks, demonstrating improved generalization under unknown sound source distributions.
Beyond Textual Knowledge-Leveraging Multimodal Knowledge Bases for Enhancing Vision-and-Language Navigation
Mar 27, 2026Vision-and-Language Navigation (VLN) requires an agent to navigate through complex unseen environments based on natural language instructions. However, existing methods often struggle to effectively capture key semantic cues and accurately align them with visual observations. To address this limitation, we propose Beyond Textual Knowledge (BTK), a VLN framework that synergistically integrates environment-specific textual knowledge with generative image knowledge bases. BTK employs Qwen3-4B to extract goal-related phrases and utilizes Flux-Schnell to construct two large-scale image knowledge bases: R2R-GP and REVERIE-GP. Additionally, we leverage BLIP-2 to construct a large-scale textual knowledge base derived from panoramic views, providing environment-specific semantic cues. These multimodal knowledge bases are effectively integrated via the Goal-Aware Augmentor and Knowledge Augmentor, significantly enhancing semantic grounding and cross-modal alignment. Extensive experiments on the R2R dataset with 7,189 trajectories and the REVERIE dataset with 21,702 instructions demonstrate that BTK significantly outperforms existing baselines. On the test unseen splits of R2R and REVERIE, SR increased by 5% and 2.07% respectively, and SPL increased by 4% and 3.69% respectively. The source code is available at https://github.com/yds3/IPM-BTK/.
Residual Cross-Modal Fusion Networks for Audio-Visual Navigation
Jan 11, 2026Audio-visual embodied navigation aims to enable an agent to autonomously localize and reach a sound source in unseen 3D environments by leveraging auditory cues. The key challenge of this task lies in effectively modeling the interaction between heterogeneous features during multimodal fusion, so as to avoid single-modality dominance or information degradation, particularly in cross-domain scenarios. To address this, we propose a Cross-Modal Residual Fusion Network, which introduces bidirectional residual interactions between audio and visual streams to achieve complementary modeling and fine-grained alignment, while maintaining the independence of their representations. Unlike conventional methods that rely on simple concatenation or attention gating, CRFN explicitly models cross-modal interactions via residual connections and incorporates stabilization techniques to improve convergence and robustness. Experiments on the Replica and Matterport3D datasets demonstrate that CRFN significantly outperforms state-of-the-art fusion baselines and achieves stronger cross-domain generalization. Notably, our experiments also reveal that agents exhibit differentiated modality dependence across different datasets. The discovery of this phenomenon provides a new perspective for understanding the cross-modal collaboration mechanism of embodied agents.
DOPE: Dual Object Perception-Enhancement Network for Vision-and-Language Navigation
Apr 30, 2025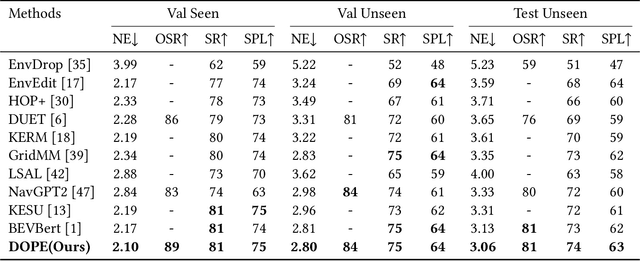
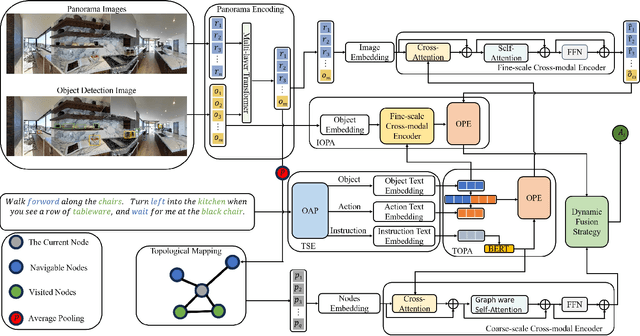
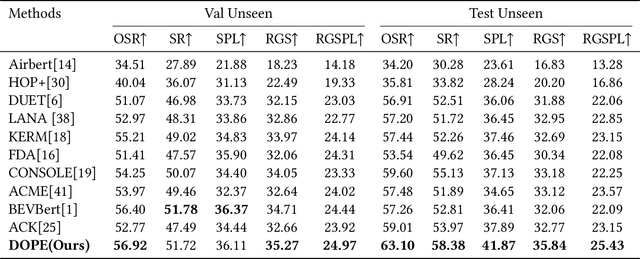
Vision-and-Language Navigation (VLN) is a challenging task where an agent must understand language instructions and navigate unfamiliar environments using visual cues. The agent must accurately locate the target based on visual information from the environment and complete tasks through interaction with the surroundings. Despite significant advancements in this field, two major limitations persist: (1) Many existing methods input complete language instructions directly into multi-layer Transformer networks without fully exploiting the detailed information within the instructions, thereby limiting the agent's language understanding capabilities during task execution; (2) Current approaches often overlook the modeling of object relationships across different modalities, failing to effectively utilize latent clues between objects, which affects the accuracy and robustness of navigation decisions. We propose a Dual Object Perception-Enhancement Network (DOPE) to address these issues to improve navigation performance. First, we design a Text Semantic Extraction (TSE) to extract relatively essential phrases from the text and input them into the Text Object Perception-Augmentation (TOPA) to fully leverage details such as objects and actions within the instructions. Second, we introduce an Image Object Perception-Augmentation (IOPA), which performs additional modeling of object information across different modalities, enabling the model to more effectively utilize latent clues between objects in images and text, enhancing decision-making accuracy. Extensive experiments on the R2R and REVERIE datasets validate the efficacy of the proposed approach.