 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDP^2-VL: Private Photo Dataset Protection by Data Poisoning for Vision-Language Models
Mar 25, 2026Recent advances in visual-language alignment have endowed vision-language models (VLMs) with fine-grained image understanding capabilities. However, this progress also introduces new privacy risks. This paper first proposes a novel privacy threat model named identity-affiliation learning: an attacker fine-tunes a VLM using only a few private photos of a target individual, thereby embedding associations between the target facial identity and their private property and social relationships into the model's internal representations. Once deployed via public APIs, this model enables unauthorized exposure of the target user's private information upon input of their photos. To benchmark VLMs' susceptibility to such identity-affiliation leakage, we introduce the first identity-affiliation dataset comprising seven typical scenarios appearing in private photos. Each scenario is instantiated with multiple identity-centered photo-description pairs. Experimental results demonstrate that mainstream VLMs like LLaVA, Qwen-VL, and MiniGPT-v2, can recognize facial identities and infer identity-affiliation relationships by fine-tuning on small-scale private photographic dataset, and even on synthetically generated datasets. To mitigate this privacy risk, we propose DP2-VL, the first Dataset Protection framework for private photos that leverages Data Poisoning. Though optimizing imperceptible perturbations by pushing the original representations toward an antithetical region, DP2-VL induces a dataset-level shift in the embedding space of VLMs'encoders. This shift separates protected images from clean inference images, causing fine-tuning on the protected set to overfit. Extensive experiments demonstrate that DP2-VL achieves strong generalization across models, robustness to diverse post-processing operations, and consistent effectiveness across varying protection ratios.
Modality-Invariant Bidirectional Temporal Representation Distillation Network for Missing Multimodal Sentiment Analysis
Jan 07, 2025
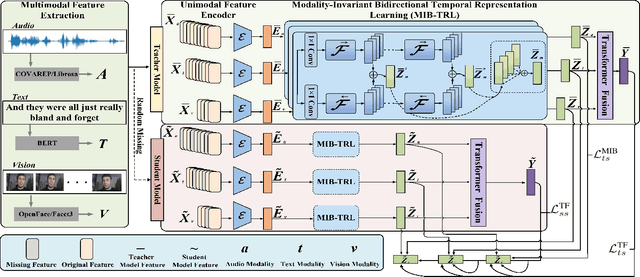
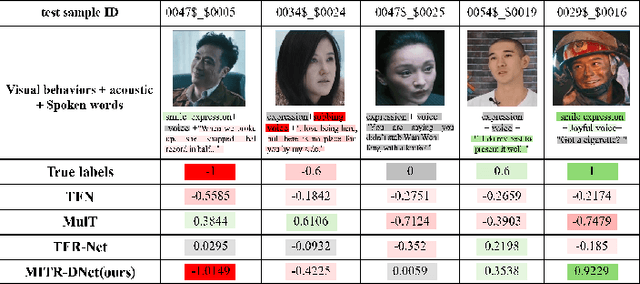
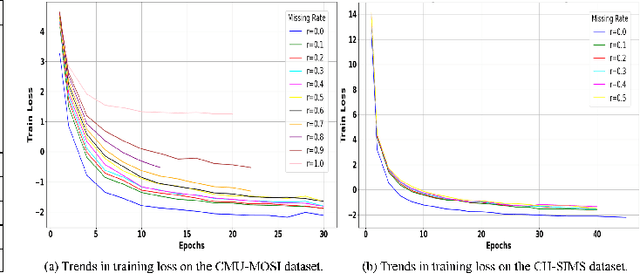
Multimodal Sentiment Analysis (MSA) integrates diverse modalities(text, audio, and video) to comprehensively analyze and understand individuals' emotional states. However, the real-world prevalence of incomplete data poses significant challenges to MSA, mainly due to the randomness of modality missing. Moreover, the heterogeneity issue in multimodal data has yet to be effectively addressed. To tackle these challenges, we introduce the Modality-Invariant Bidirectional Temporal Representation Distillation Network (MITR-DNet) for Missing Multimodal Sentiment Analysis. MITR-DNet employs a distillation approach, wherein a complete modality teacher model guides a missing modality student model, ensuring robustness in the presence of modality missing. Simultaneously, we developed the Modality-Invariant Bidirectional Temporal Representation Learning Module (MIB-TRL) to mitigate heterogeneity.
PCQ: Emotion Recognition in Speech via Progressive Channel Querying
Jul 17, 2024In human-computer interaction (HCI), Speech Emotion Recognition (SER) is a key technology for understanding human intentions and emotions. Traditional SER methods struggle to effectively capture the long-term temporal correla-tions and dynamic variations in complex emotional expressions. To overcome these limitations, we introduce the PCQ method, a pioneering approach for SER via \textbf{P}rogressive \textbf{C}hannel \textbf{Q}uerying. This method can drill down layer by layer in the channel dimension through the channel query technique to achieve dynamic modeling of long-term contextual information of emotions. This mul-ti-level analysis gives the PCQ method an edge in capturing the nuances of hu-man emotions. Experimental results show that our model improves the weighted average (WA) accuracy by 3.98\% and 3.45\% and the unweighted av-erage (UA) accuracy by 5.67\% and 5.83\% on the IEMOCAP and EMODB emotion recognition datasets, respectively, significantly exceeding the baseline levels.
Towards End-to-end 4-Bit Inference on Generative Large Language Models
Oct 13, 2023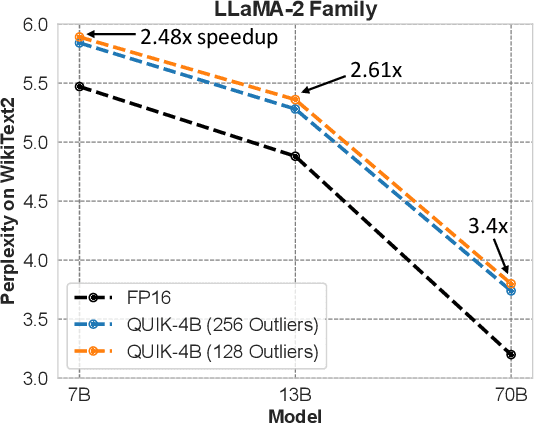
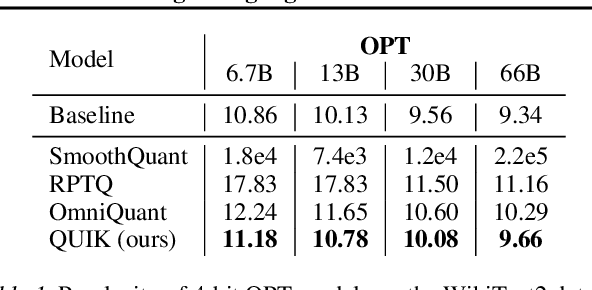
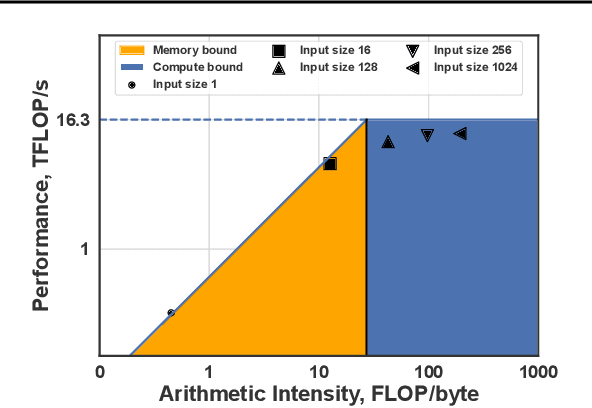
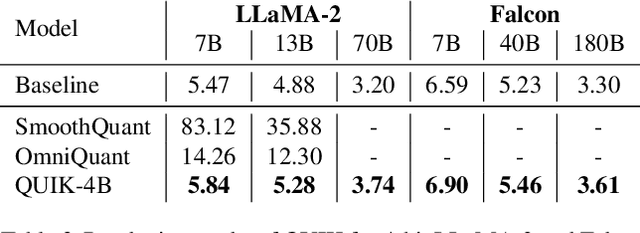
We show that the majority of the inference computations for large generative models such as LLaMA and OPT can be performed with both weights and activations being cast to 4 bits, in a way that leads to practical speedups while at the same time maintaining good accuracy. We achieve this via a hybrid quantization strategy called QUIK, which compresses most of the weights and activations to 4-bit, while keeping some outlier weights and activations in higher-precision. Crucially, our scheme is designed with computational efficiency in mind: we provide GPU kernels with highly-efficient layer-wise runtimes, which lead to practical end-to-end throughput improvements of up to 3.1x relative to FP16 execution. Code and models are provided at https://github.com/IST-DASLab/QUIK.