 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayer-wise Quantization for Quantized Optimistic Dual Averaging
May 20, 2025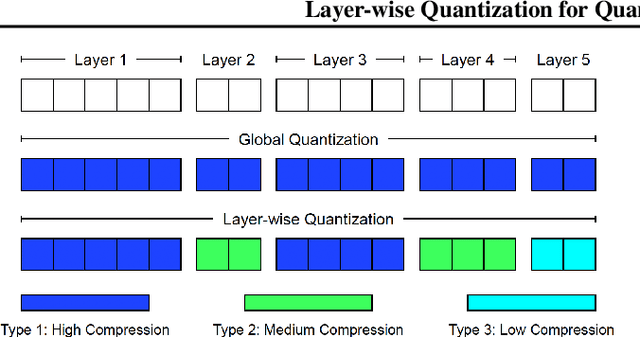
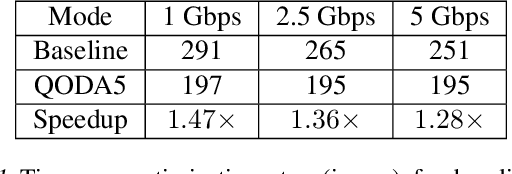
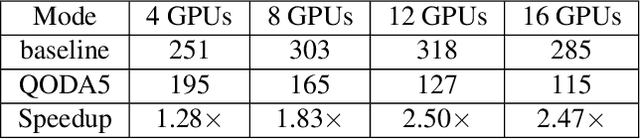
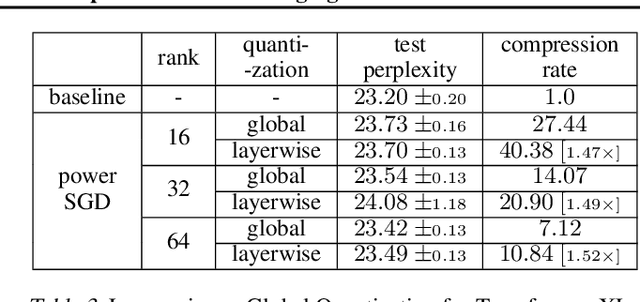
Modern deep neural networks exhibit heterogeneity across numerous layers of various types such as residuals, multi-head attention, etc., due to varying structures (dimensions, activation functions, etc.), distinct representation characteristics, which impact predictions. We develop a general layer-wise quantization framework with tight variance and code-length bounds, adapting to the heterogeneities over the course of training. We then apply a new layer-wise quantization technique within distributed variational inequalities (VIs), proposing a novel Quantized Optimistic Dual Averaging (QODA) algorithm with adaptive learning rates, which achieves competitive convergence rates for monotone VIs. We empirically show that QODA achieves up to a $150\%$ speedup over the baselines in end-to-end training time for training Wasserstein GAN on $12+$ GPUs.
Sparse Expansion and Neuronal Disentanglement
May 24, 2024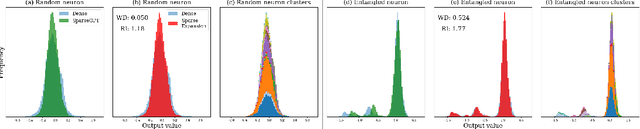
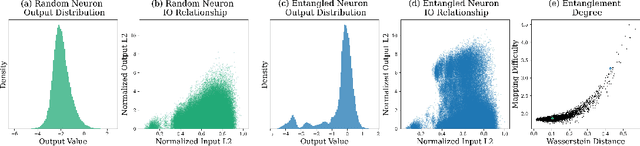
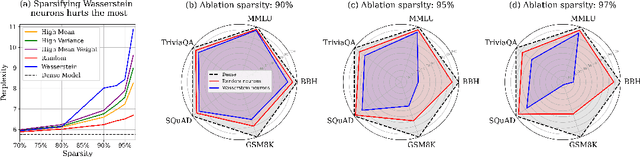
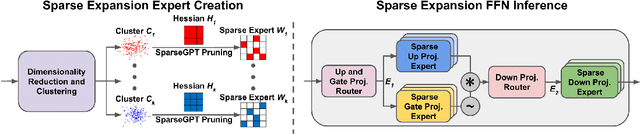
We show how to improve the inference efficiency of an LLM by expanding it into a mixture of sparse experts, where each expert is a copy of the original weights, one-shot pruned for a specific cluster of input values. We call this approach $\textit{Sparse Expansion}$. We show that, for models such as Llama 2 70B, as we increase the number of sparse experts, Sparse Expansion outperforms all other one-shot sparsification approaches for the same inference FLOP budget per token, and that this gap grows as sparsity increases, leading to inference speedups. But why? To answer this, we provide strong evidence that the mixture of sparse experts is effectively $\textit{disentangling}$ the input-output relationship of every individual neuron across clusters of inputs. Specifically, sparse experts approximate the dense neuron output distribution with fewer weights by decomposing the distribution into a collection of simpler ones, each with a separate sparse dot product covering it. Interestingly, we show that the Wasserstein distance between a neuron's output distribution and a Gaussian distribution is an indicator of its entanglement level and contribution to the accuracy of the model. Every layer of an LLM has a fraction of highly entangled Wasserstein neurons, and model performance suffers more when these are sparsified as opposed to others.
Grounding Toxicity in Real-World Events across Languages
May 22, 2024Social media conversations frequently suffer from toxicity, creating significant issues for users, moderators, and entire communities. Events in the real world, like elections or conflicts, can initiate and escalate toxic behavior online. Our study investigates how real-world events influence the origin and spread of toxicity in online discussions across various languages and regions. We gathered Reddit data comprising 4.5 million comments from 31 thousand posts in six different languages (Dutch, English, German, Arabic, Turkish and Spanish). We target fifteen major social and political world events that occurred between 2020 and 2023. We observe significant variations in toxicity, negative sentiment, and emotion expressions across different events and language communities, showing that toxicity is a complex phenomenon in which many different factors interact and still need to be investigated. We will release the data for further research along with our code.
The Constant in HATE: Analyzing Toxicity in Reddit across Topics and Languages
Apr 29, 2024



Toxic language remains an ongoing challenge on social media platforms, presenting significant issues for users and communities. This paper provides a cross-topic and cross-lingual analysis of toxicity in Reddit conversations. We collect 1.5 million comment threads from 481 communities in six languages: English, German, Spanish, Turkish,Arabic, and Dutch, covering 80 topics such as Culture, Politics, and News. We thoroughly analyze how toxicity spikes within different communities in relation to specific topics. We observe consistent patterns of increased toxicity across languages for certain topics, while also noting significant variations within specific language communities.
Unknown Script: Impact of Script on Cross-Lingual Transfer
Apr 29, 2024

Cross-lingual transfer has become an effective way of transferring knowledge between languages. In this paper, we explore an often-overlooked aspect in this domain: the influence of the source language of the base language model on transfer performance. We conduct a series of experiments to determine the effect of the script and tokenizer used in the pre-trained model on the performance of the downstream task. Our findings reveal the importance of the tokenizer as a stronger factor than the sharing of the script, the language typology match, and the model size.
Truth-value judgment in language models: belief directions are context sensitive
Apr 29, 2024



Recent work has demonstrated that the latent spaces of large language models (LLMs) contain directions predictive of the truth of sentences. Multiple methods recover such directions and build probes that are described as getting at a model's "knowledge" or "beliefs". We investigate this phenomenon, looking closely at the impact of context on the probes. Our experiments establish where in the LLM the probe's predictions can be described as being conditional on the preceding (related) sentences. Specifically, we quantify the responsiveness of the probes to the presence of (negated) supporting and contradicting sentences, and score the probes on their consistency. We also perform a causal intervention experiment, investigating whether moving the representation of a premise along these belief directions influences the position of the hypothesis along that same direction. We find that the probes we test are generally context sensitive, but that contexts which should not affect the truth often still impact the probe outputs. Our experiments show that the type of errors depend on the layer, the (type of) model, and the kind of data. Finally, our results suggest that belief directions are (one of the) causal mediators in the inference process that incorporates in-context information.
Reasoning about Ambiguous Definite Descriptions
Oct 23, 2023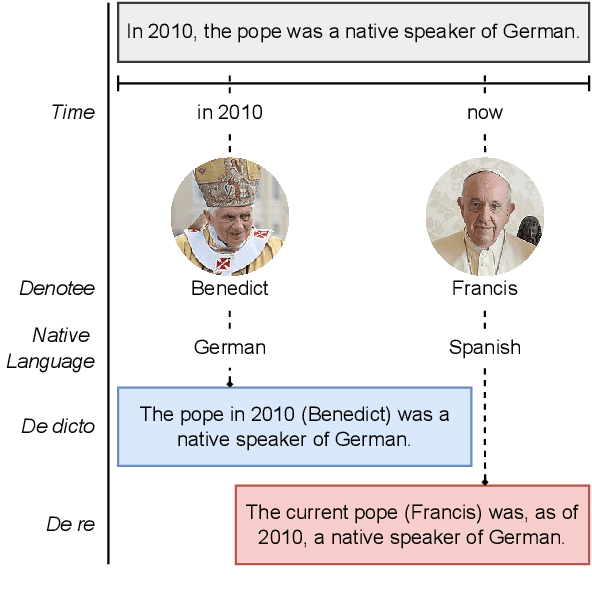


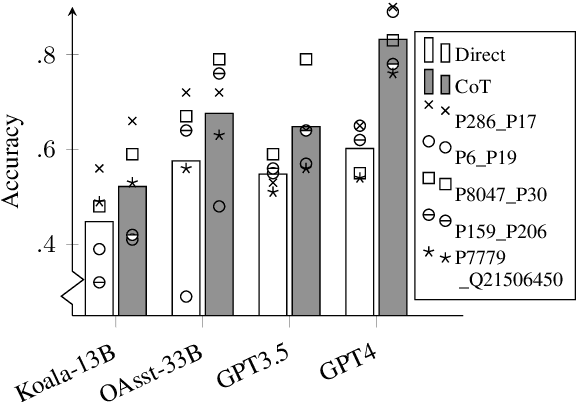
Natural language reasoning plays an increasingly important role in improving language models' ability to solve complex language understanding tasks. An interesting use case for reasoning is the resolution of context-dependent ambiguity. But no resources exist to evaluate how well Large Language Models can use explicit reasoning to resolve ambiguity in language. We propose to use ambiguous definite descriptions for this purpose and create and publish the first benchmark dataset consisting of such phrases. Our method includes all information required to resolve the ambiguity in the prompt, which means a model does not require anything but reasoning to do well. We find this to be a challenging task for recent LLMs. Code and data available at: https://github.com/sfschouten/exploiting-ambiguity
Towards End-to-end 4-Bit Inference on Generative Large Language Models
Oct 13, 2023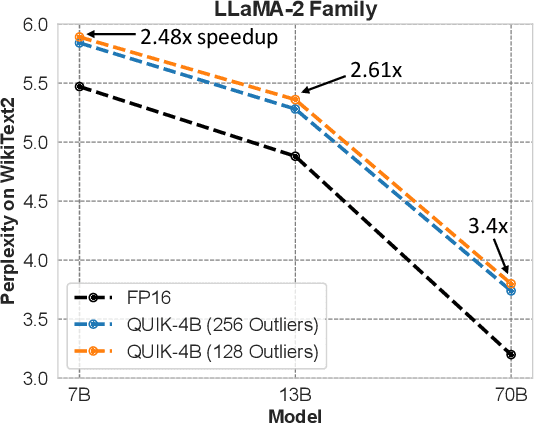
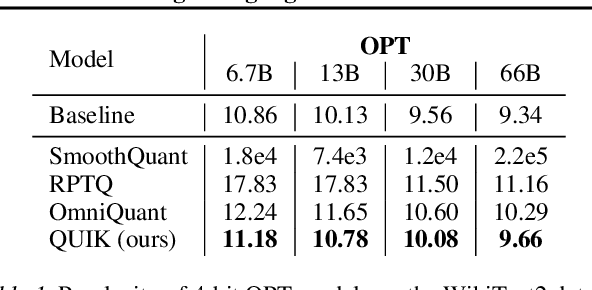
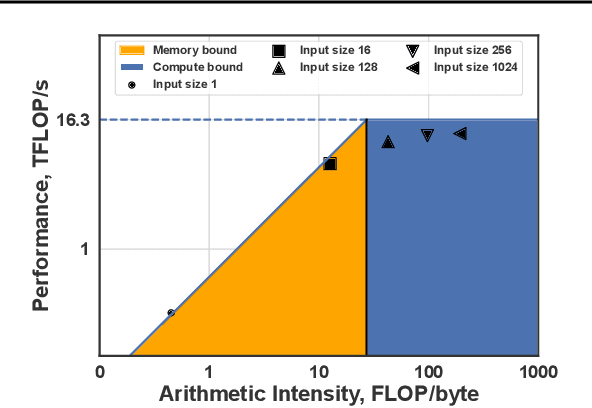
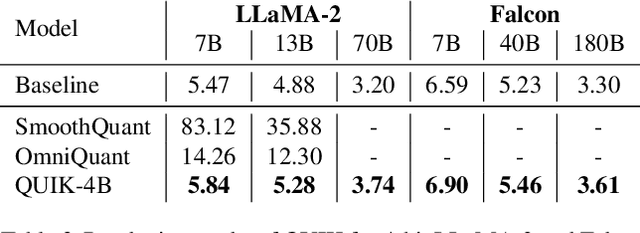
We show that the majority of the inference computations for large generative models such as LLaMA and OPT can be performed with both weights and activations being cast to 4 bits, in a way that leads to practical speedups while at the same time maintaining good accuracy. We achieve this via a hybrid quantization strategy called QUIK, which compresses most of the weights and activations to 4-bit, while keeping some outlier weights and activations in higher-precision. Crucially, our scheme is designed with computational efficiency in mind: we provide GPU kernels with highly-efficient layer-wise runtimes, which lead to practical end-to-end throughput improvements of up to 3.1x relative to FP16 execution. Code and models are provided at https://github.com/IST-DASLab/QUIK.
Cross-Domain Toxic Spans Detection
Jun 16, 2023Given the dynamic nature of toxic language use, automated methods for detecting toxic spans are likely to encounter distributional shift. To explore this phenomenon, we evaluate three approaches for detecting toxic spans under cross-domain conditions: lexicon-based, rationale extraction, and fine-tuned language models. Our findings indicate that a simple method using off-the-shelf lexicons performs best in the cross-domain setup. The cross-domain error analysis suggests that (1) rationale extraction methods are prone to false negatives, while (2) language models, despite performing best for the in-domain case, recall fewer explicitly toxic words than lexicons and are prone to certain types of false positives. Our code is publicly available at: https://github.com/sfschouten/toxic-cross-domain.
Quantized Distributed Training of Large Models with Convergence Guarantees
Feb 05, 2023



Communication-reduction techniques are a popular way to improve scalability in data-parallel training of deep neural networks (DNNs). The recent emergence of large language models such as GPT has created the need for new approaches to exploit data-parallelism. Among these, fully-sharded data parallel (FSDP) training is highly popular, yet it still encounters scalability bottlenecks. One reason is that applying compression techniques to FSDP is challenging: as the vast majority of the communication involves the model's weights, direct compression alters convergence and leads to accuracy loss. We present QSDP, a variant of FSDP which supports both gradient and weight quantization with theoretical guarantees, is simple to implement and has essentially no overheads. To derive QSDP we prove that a natural modification of SGD achieves convergence even when we only maintain quantized weights, and thus the domain over which we train consists of quantized points and is, therefore, highly non-convex. We validate this approach by training GPT-family models with up to 1.3 billion parameters on a multi-node cluster. Experiments show that QSDP preserves model accuracy, while completely removing the communication bottlenecks of FSDP, providing end-to-end speedups of up to 2.2x.