 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting integers from continuous parameters
Feb 11, 2026We study the problem of predicting numeric labels that are constrained to the integers or to a subrange of the integers. For example, the number of up-votes on social media posts, or the number of bicycles available at a public rental station. While it is possible to model these as continuous values, and to apply traditional regression, this approach changes the underlying distribution on the labels from discrete to continuous. Discrete distributions have certain benefits, which leads us to the question whether such integer labels can be modeled directly by a discrete distribution, whose parameters are predicted from the features of a given instance. Moreover, we focus on the use case of output distributions of neural networks, which adds the requirement that the parameters of the distribution be continuous so that backpropagation and gradient descent may be used to learn the weights of the network. We investigate several options for such distributions, some existing and some novel, and test them on a range of tasks, including tabular learning, sequential prediction and image generation. We find that overall the best performance comes from two distributions: Bitwise, which represents the target integer in bits and places a Bernoulli distribution on each, and a discrete analogue of the Laplace distribution, which uses a distribution with exponentially decaying tails around a continuous mean.
Autoregressive Models for Knowledge Graph Generation
Feb 06, 2026Knowledge Graph (KG) generation requires models to learn complex semantic dependencies between triples while maintaining domain validity constraints. Unlike link prediction, which scores triples independently, generative models must capture interdependencies across entire subgraphs to produce semantically coherent structures. We present ARK (Auto-Regressive Knowledge Graph Generation), a family of autoregressive models that generate KGs by treating graphs as sequences of (head, relation, tail) triples. ARK learns implicit semantic constraints directly from data, including type consistency, temporal validity, and relational patterns, without explicit rule supervision. On the IntelliGraphs benchmark, our models achieve 89.2% to 100.0% semantic validity across diverse datasets while generating novel graphs not seen during training. We also introduce SAIL, a variational extension of ARK that enables controlled generation through learned latent representations, supporting both unconditional sampling and conditional completion from partial graphs. Our analysis reveals that model capacity (hidden dimensionality >= 64) is more critical than architectural depth for KG generation, with recurrent architectures achieving comparable validity to transformer-based alternatives while offering substantial computational efficiency. These results demonstrate that autoregressive models provide an effective framework for KG generation, with practical applications in knowledge base completion and query answering.
Truth-value judgment in language models: belief directions are context sensitive
Apr 29, 2024



Recent work has demonstrated that the latent spaces of large language models (LLMs) contain directions predictive of the truth of sentences. Multiple methods recover such directions and build probes that are described as getting at a model's "knowledge" or "beliefs". We investigate this phenomenon, looking closely at the impact of context on the probes. Our experiments establish where in the LLM the probe's predictions can be described as being conditional on the preceding (related) sentences. Specifically, we quantify the responsiveness of the probes to the presence of (negated) supporting and contradicting sentences, and score the probes on their consistency. We also perform a causal intervention experiment, investigating whether moving the representation of a premise along these belief directions influences the position of the hypothesis along that same direction. We find that the probes we test are generally context sensitive, but that contexts which should not affect the truth often still impact the probe outputs. Our experiments show that the type of errors depend on the layer, the (type of) model, and the kind of data. Finally, our results suggest that belief directions are (one of the) causal mediators in the inference process that incorporates in-context information.
Reasoning about Ambiguous Definite Descriptions
Oct 23, 2023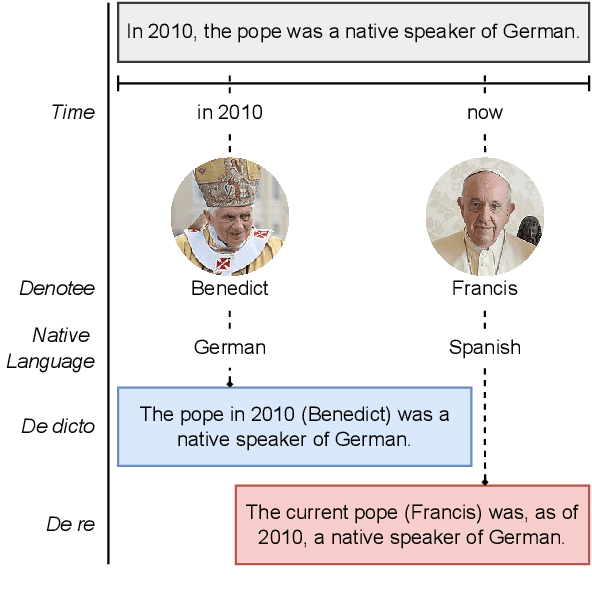


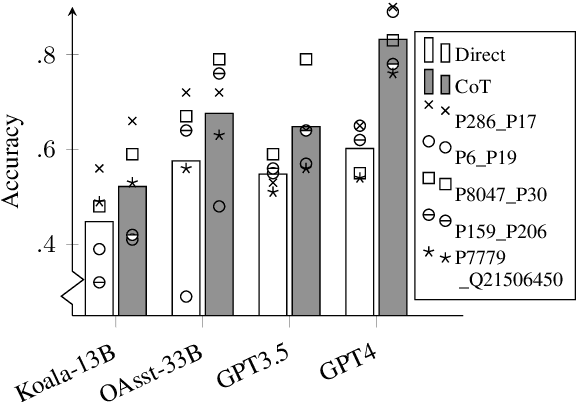
Natural language reasoning plays an increasingly important role in improving language models' ability to solve complex language understanding tasks. An interesting use case for reasoning is the resolution of context-dependent ambiguity. But no resources exist to evaluate how well Large Language Models can use explicit reasoning to resolve ambiguity in language. We propose to use ambiguous definite descriptions for this purpose and create and publish the first benchmark dataset consisting of such phrases. Our method includes all information required to resolve the ambiguity in the prompt, which means a model does not require anything but reasoning to do well. We find this to be a challenging task for recent LLMs. Code and data available at: https://github.com/sfschouten/exploiting-ambiguity
GRAPES: Learning to Sample Graphs for Scalable Graph Neural Networks
Oct 05, 2023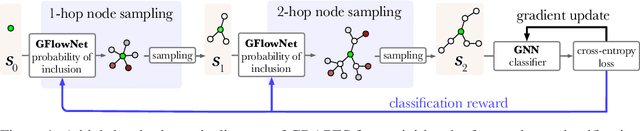
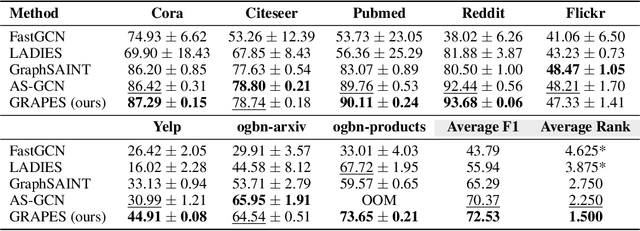
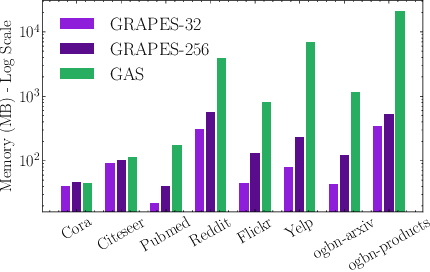
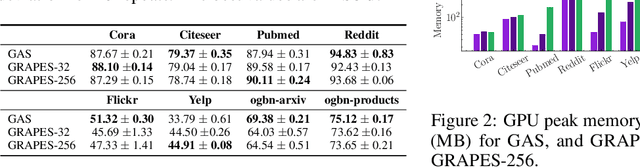
Graph neural networks (GNNs) learn the representation of nodes in a graph by aggregating the neighborhood information in various ways. As these networks grow in depth, their receptive field grows exponentially due to the increase in neighborhood sizes, resulting in high memory costs. Graph sampling solves memory issues in GNNs by sampling a small ratio of the nodes in the graph. This way, GNNs can scale to much larger graphs. Most sampling methods focus on fixed sampling heuristics, which may not generalize to different structures or tasks. We introduce GRAPES, an adaptive graph sampling method that learns to identify sets of influential nodes for training a GNN classifier. GRAPES uses a GFlowNet to learn node sampling probabilities given the classification objectives. We evaluate GRAPES across several small- and large-scale graph benchmarks and demonstrate its effectiveness in accuracy and scalability. In contrast to existing sampling methods, GRAPES maintains high accuracy even with small sample sizes and, therefore, can scale to very large graphs. Our code is publicly available at https://github.com/dfdazac/grapes.
IntelliGraphs: Datasets for Benchmarking Knowledge Graph Generation
Jul 19, 2023
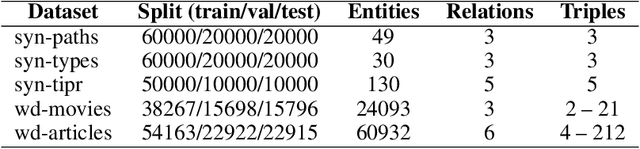
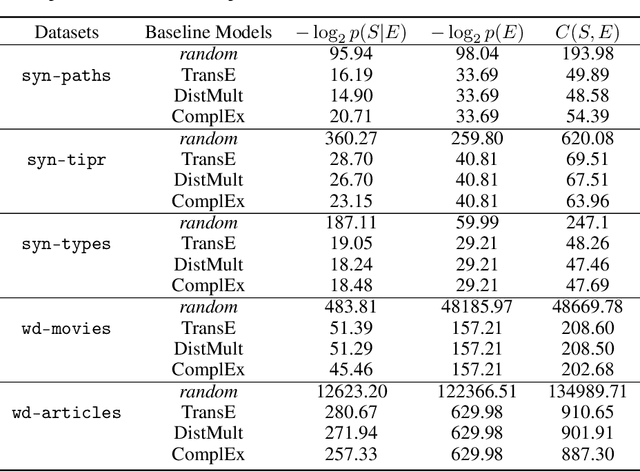
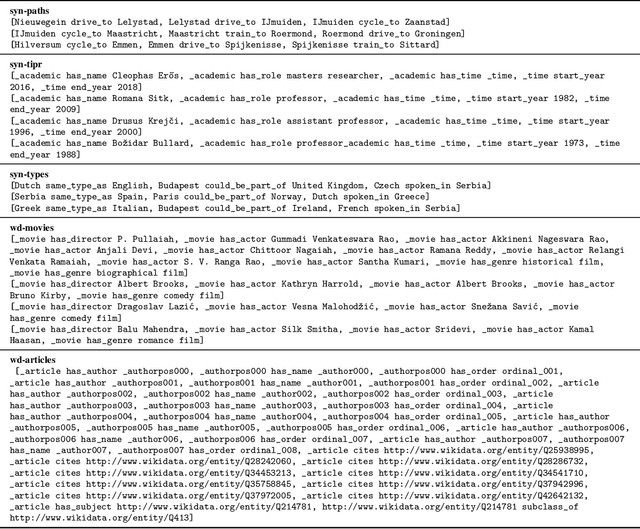
Knowledge Graph Embedding (KGE) models are used to learn continuous representations of entities and relations. A key task in the literature is predicting missing links between entities. However, Knowledge Graphs are not just sets of links but also have semantics underlying their structure. Semantics is crucial in several downstream tasks, such as query answering or reasoning. We introduce the subgraph inference task, where a model has to generate likely and semantically valid subgraphs. We propose IntelliGraphs, a set of five new Knowledge Graph datasets. The IntelliGraphs datasets contain subgraphs with semantics expressed in logical rules for evaluating subgraph inference. We also present the dataset generator that produced the synthetic datasets. We designed four novel baseline models, which include three models based on traditional KGEs. We evaluate their expressiveness and show that these models cannot capture the semantics. We believe this benchmark will encourage the development of machine learning models that emphasize semantic understanding.
Relational Graph Convolutional Networks: A Closer Look
Jul 21, 2021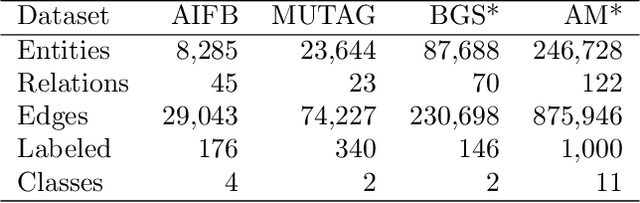
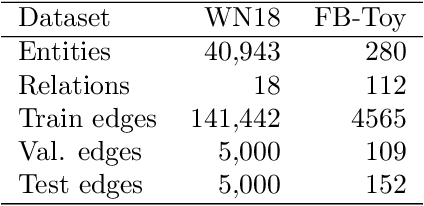
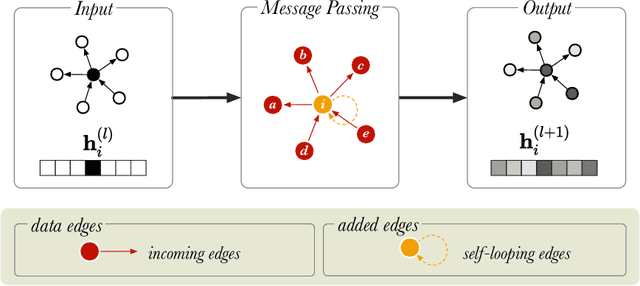
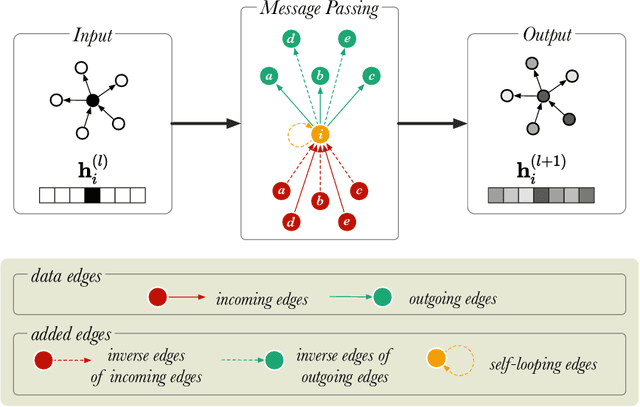
In this paper, we describe a reproduction of the Relational Graph Convolutional Network (RGCN). Using our reproduction, we explain the intuition behind the model. Our reproduction results empirically validate the correctness of our implementations using benchmark Knowledge Graph datasets on node classification and link prediction tasks. Our explanation provides a friendly understanding of the different components of the RGCN for both users and researchers extending the RGCN approach. Furthermore, we introduce two new configurations of the RGCN that are more parameter efficient. The code and datasets are available at https://github.com/thiviyanT/torch-rgcn.
Finding Motifs in Knowledge Graphs using Compression
Apr 16, 2021
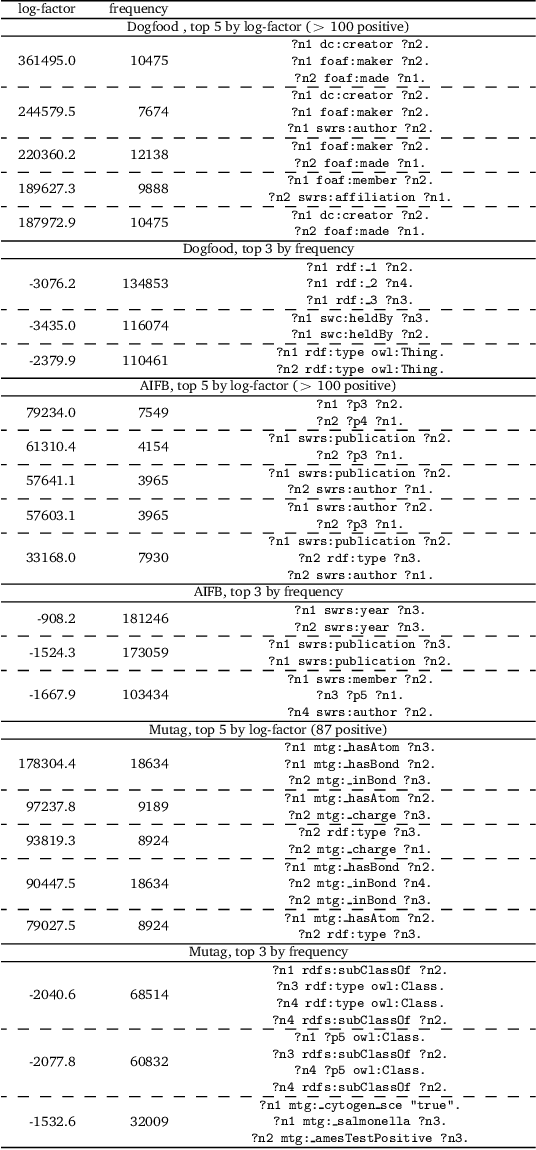
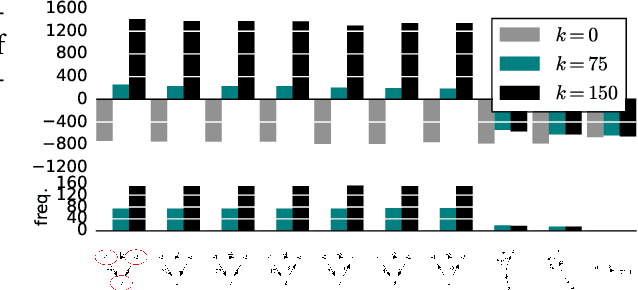

We introduce a method to find network motifs in knowledge graphs. Network motifs are useful patterns or meaningful subunits of the graph that recur frequently. We extend the common definition of a network motif to coincide with a basic graph pattern. We introduce an approach, inspired by recent work for simple graphs, to induce these from a given knowledge graph, and show that the motifs found reflect the basic structure of the graph. Specifically, we show that in random graphs, no motifs are found, and that when we insert a motif artificially, it can be detected. Finally, we show the results of motif induction on three real-world knowledge graphs.
Uncertainty Intervals for Graph-based Spatio-Temporal Traffic Prediction
Dec 09, 2020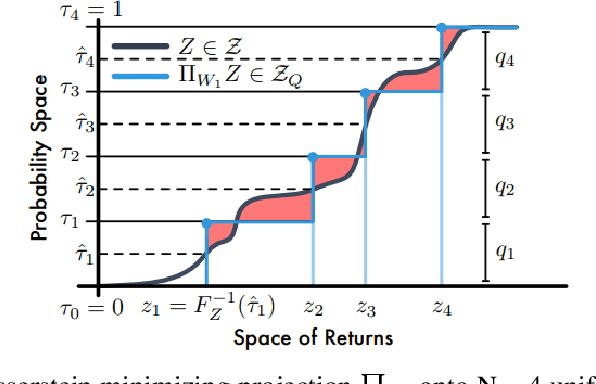

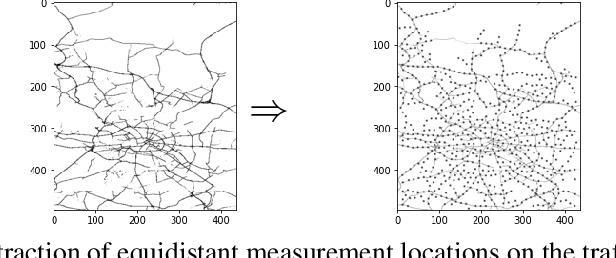
Many traffic prediction applications rely on uncertainty estimates instead of the mean prediction. Statistical traffic prediction literature has a complete subfield devoted to uncertainty modelling, but recent deep learning traffic prediction models either lack this feature or make specific assumptions that restrict its practicality. We propose Quantile Graph Wavenet, a Spatio-Temporal neural network that is trained to estimate a density given the measurements of previous timesteps, conditioned on a quantile. Our method of density estimation is fully parameterised by our neural network and does not use a likelihood approximation internally. The quantile loss function is asymmetric and this makes it possible to model skewed densities. This approach produces uncertainty estimates without the need to sample during inference, such as in Monte Carlo Dropout, which makes our method also efficient.
A Hybrid 3DCNN and 3DC-LSTM based model for 4D Spatio-temporal fMRI data: An ABIDE Autism Classification study
Feb 14, 2020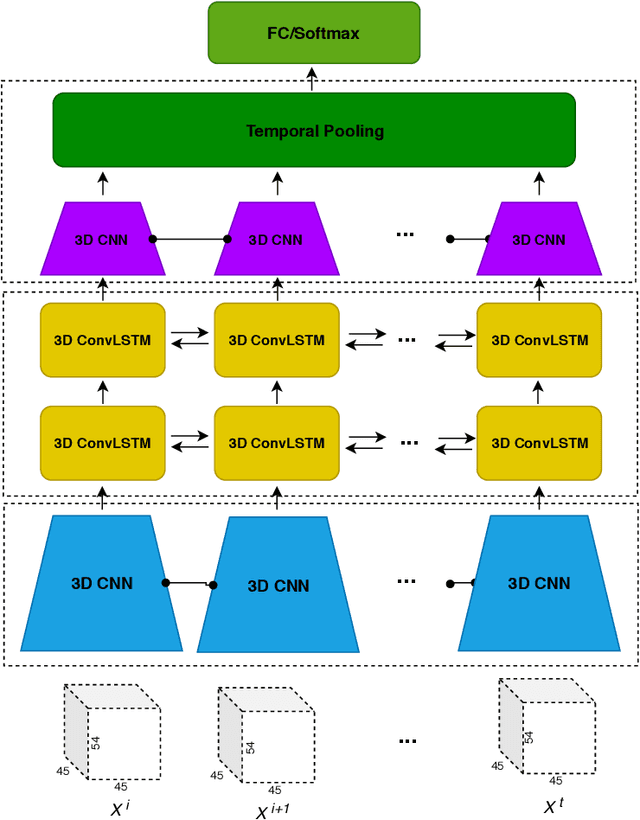
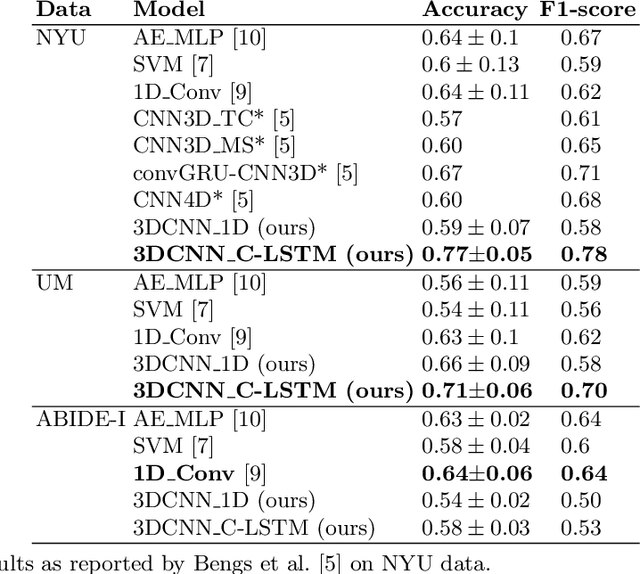
Functional Magnetic Resonance Imaging (fMRI) captures the temporal dynamics of neural activity as a function of spatial location in the brain. Thus, fMRI scans are represented as 4-Dimensional (3-space + 1-time) tensors. And it is widely believed that the spatio-temporal patterns in fMRI manifests as behaviour and clinical symptoms. Because of the high dimensionality ($\sim$ 1 Million) of fMRI, and the added constraints of limited cardinality of data sets, extracting such patterns are challenging. A standard approach to overcome these hurdles is to reduce the dimensionality of the data by either summarizing activation over time or space at the expense of possible loss of useful information. Here, we introduce an end-to-end algorithm capable of extracting spatiotemporal features from the full 4-D data using 3-D CNNs and 3-D Convolutional LSTMs. We evaluate our proposed model on the publicly available ABIDE dataset to demonstrate the capability of our model to classify Autism Spectrum Disorder (ASD) from resting-state fMRI data. Our results show that the proposed model achieves state of the art results on single sites with F1-scores of 0.78 and 0.7 on NYU and UM sites, respectively.
* 8pages