 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Objects with Graph Priors and Graph Refinement
Dec 23, 2022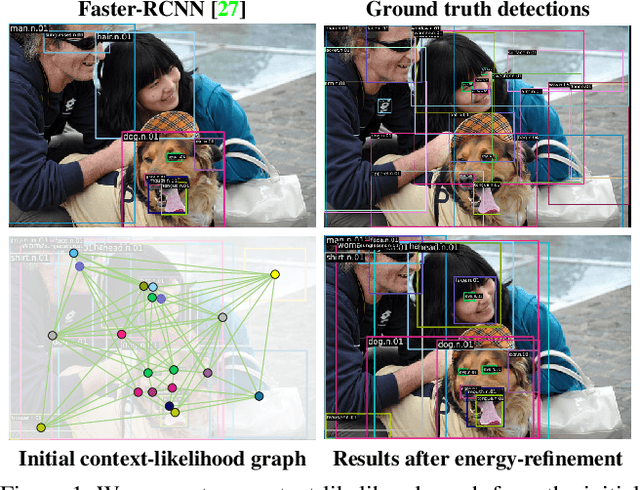



The goal of this paper is to detect objects by exploiting their interrelationships. Rather than relying on predefined and labeled graph structures, we infer a graph prior from object co-occurrence statistics. The key idea of our paper is to model object relations as a function of initial class predictions and co-occurrence priors to generate a graph representation of an image for improved classification and bounding box regression. We additionally learn the object-relation joint distribution via energy based modeling. Sampling from this distribution generates a refined graph representation of the image which in turn produces improved detection performance. Experiments on the Visual Genome and MS-COCO datasets demonstrate our method is detector agnostic, end-to-end trainable, and especially beneficial for rare object classes. What is more, we establish a consistent improvement over object detectors like DETR and Faster-RCNN, as well as state-of-the-art methods modeling object interrelationships.
Exploiting Temporality for Semi-Supervised Video Segmentation
Aug 29, 2019
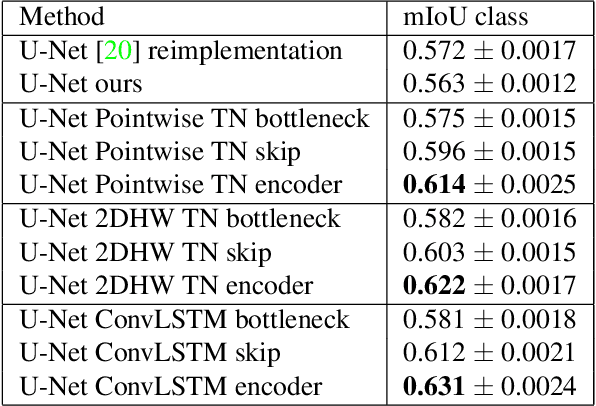
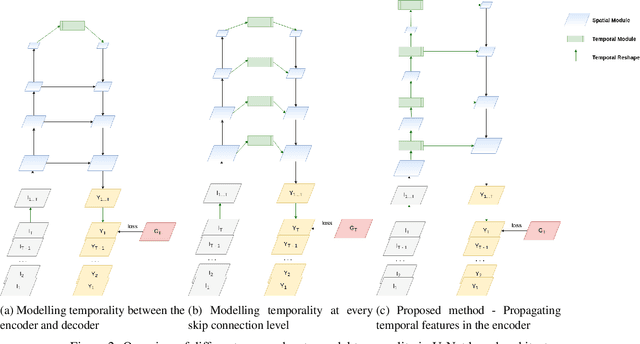
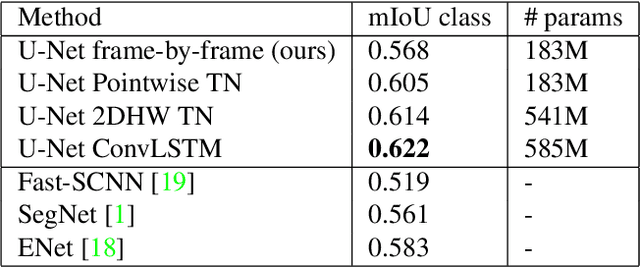
In recent years, there has been remarkable progress in supervised image segmentation. Video segmentation is less explored, despite the temporal dimension being highly informative. Semantic labels, e.g. that cannot be accurately detected in the current frame, may be inferred by incorporating information from previous frames. However, video segmentation is challenging due to the amount of data that needs to be processed and, more importantly, the cost involved in obtaining ground truth annotations for each frame. In this paper, we tackle the issue of label scarcity by using consecutive frames of a video, where only one frame is annotated. We propose a deep, end-to-end trainable model which leverages temporal information in order to make use of easy to acquire unlabeled data. Our network architecture relies on a novel interconnection of two components: a fully convolutional network to model spatial information and temporal units that are employed at intermediate levels of the convolutional network in order to propagate information through time. The main contribution of this work is the guidance of the temporal signal through the network. We show that only placing a temporal module between the encoder and decoder is suboptimal (baseline). Our extensive experiments on the CityScapes dataset indicate that the resulting model can leverage unlabeled temporal frames and significantly outperform both the frame-by-frame image segmentation and the baseline approach.