 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Distillation for Visual Autoregressive Models
Jun 04, 2026Autoregressive (AR) image generation models are highly expressive but computationally intensive, motivating effective model compression. Knowledge distillation (KD) is a natural approach for model compression and has been widely studied in language modeling, yet its behavior in visual AR generation remains underexplored. In this work, we present the first systematic study of distillation strategies for AR image models. Our analysis shows that while standard distillation can yield meaningful gains, recent methods developed for language do not directly transfer to images: long decoding horizons and visual token ambiguity make teacher supervision unreliable especially under student-conditioned contexts. To address this, we propose VarKD, a distillation framework for visual autoregressive models that distills on student samples while selectively applying teacher supervision and reducing token-level ambiguity. Experiments on ImageNet across multiple AR backbones show that VarKD consistently outperforms prior distillation baselines, narrowing the gap to large-scale models.
Injecting Image Guidance into Text-Conditioned Diffusion Models at Inference
May 24, 2026Text-to-image diffusion models like Stable Diffusion generate high-quality images from text, but lack a way to inject visual guidance (e.g. sketches, styles) at inference without retraining. Existing methods either require computationally expensive fine-tuning or rely on style transfer techniques that risk semantic misalignment with textual prompts. We introduce Visual Concept Fusion (VCF), the first method offering dual conditioning on both an image and text prompt at inference time without any concept-specific training. VCF enables visual concept injection into Stable Diffusion by aligning CLIP image features with the text embedding space. VCF consists of three components: (1) a lightweight aligner that maps image tokens to the text embedding manifold using InfoNCE and cross-attention reconstruction losses, (2) a fusion strategy that preserves both textual and visual semantics, and (3) an optional Prompt-Noise Optimization (PNO) module for test-time refinement. Our experiments demonstrate that VCF successfully transfers visual attributes including style, composition, and color palette from reference images while maintaining prompt adherence. Quantitative results show a trade-off between text alignment (CLIP score) and visual correspondence (LPIPS), with VCF outperforming baselines in reference fidelity.
MoAlign: Motion-Centric Representation Alignment for Video Diffusion Models
Oct 21, 2025Text-to-video diffusion models have enabled high-quality video synthesis, yet often fail to generate temporally coherent and physically plausible motion. A key reason is the models' insufficient understanding of complex motions that natural videos often entail. Recent works tackle this problem by aligning diffusion model features with those from pretrained video encoders. However, these encoders mix video appearance and dynamics into entangled features, limiting the benefit of such alignment. In this paper, we propose a motion-centric alignment framework that learns a disentangled motion subspace from a pretrained video encoder. This subspace is optimized to predict ground-truth optical flow, ensuring it captures true motion dynamics. We then align the latent features of a text-to-video diffusion model to this new subspace, enabling the generative model to internalize motion knowledge and generate more plausible videos. Our method improves the physical commonsense in a state-of-the-art video diffusion model, while preserving adherence to textual prompts, as evidenced by empirical evaluations on VideoPhy, VideoPhy2, VBench, and VBench-2.0, along with a user study.
Structured-Noise Masked Modeling for Video, Audio and Beyond
Mar 20, 2025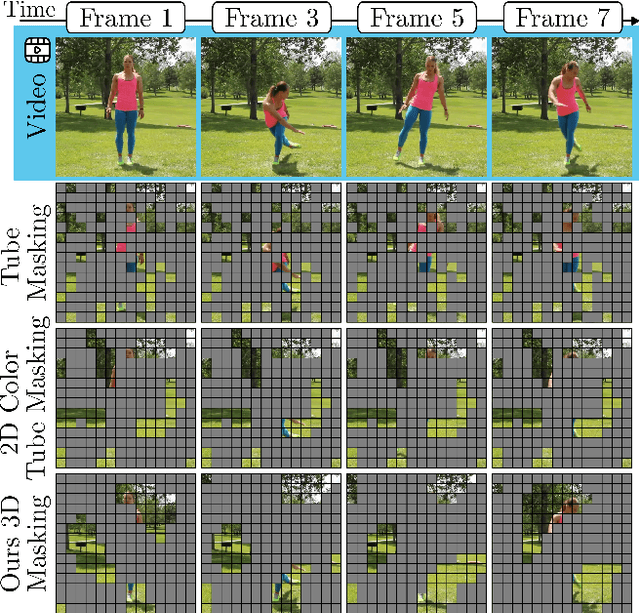
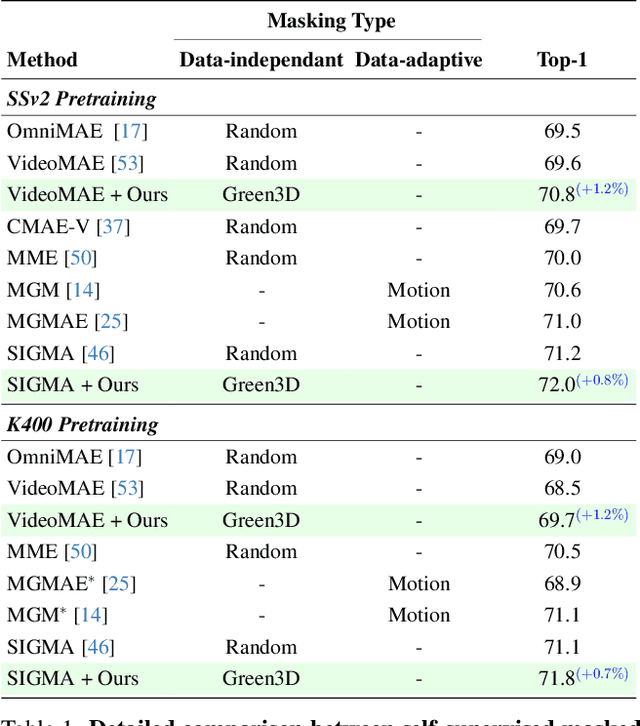
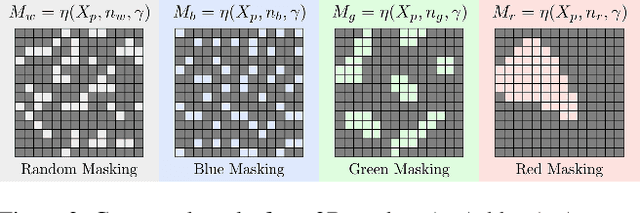

Masked modeling has emerged as a powerful self-supervised learning framework, but existing methods largely rely on random masking, disregarding the structural properties of different modalities. In this work, we introduce structured noise-based masking, a simple yet effective approach that naturally aligns with the spatial, temporal, and spectral characteristics of video and audio data. By filtering white noise into distinct color noise distributions, we generate structured masks that preserve modality-specific patterns without requiring handcrafted heuristics or access to the data. Our approach improves the performance of masked video and audio modeling frameworks without any computational overhead. Extensive experiments demonstrate that structured noise masking achieves consistent improvement over random masking for standard and advanced masked modeling methods, highlighting the importance of modality-aware masking strategies for representation learning.
Learning to Ground VLMs without Forgetting
Oct 14, 2024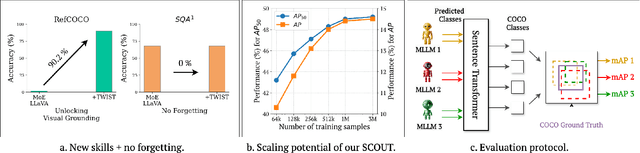

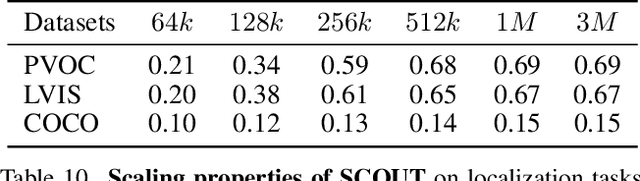
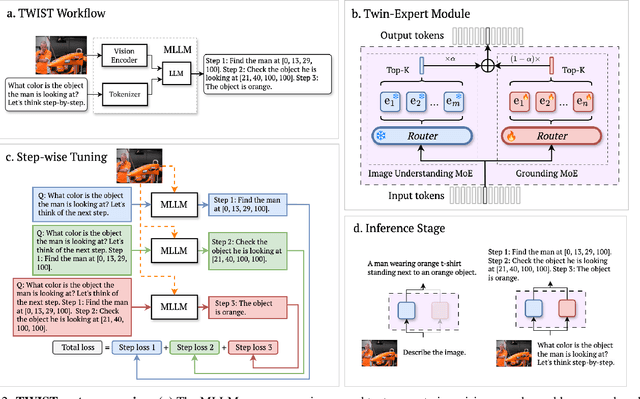
Spatial awareness is key to enable embodied multimodal AI systems. Yet, without vast amounts of spatial supervision, current Visual Language Models (VLMs) struggle at this task. In this paper, we introduce LynX, a framework that equips pretrained VLMs with visual grounding ability without forgetting their existing image and language understanding skills. To this end, we propose a Dual Mixture of Experts module that modifies only the decoder layer of the language model, using one frozen Mixture of Experts (MoE) pre-trained on image and language understanding and another learnable MoE for new grounding capabilities. This allows the VLM to retain previously learned knowledge and skills, while acquiring what is missing. To train the model effectively, we generate a high-quality synthetic dataset we call SCouT, which mimics human reasoning in visual grounding. This dataset provides rich supervision signals, describing a step-by-step multimodal reasoning process, thereby simplifying the task of visual grounding. We evaluate LynX on several object detection and visual grounding datasets, demonstrating strong performance in object detection, zero-shot localization and grounded reasoning while maintaining its original image and language understanding capabilities on seven standard benchmark datasets.
Revisiting Proposal-based Object Detection
Nov 30, 2023



This paper revisits the pipeline for detecting objects in images with proposals. For any object detector, the obtained box proposals or queries need to be classified and regressed towards ground truth boxes. The common solution for the final predictions is to directly maximize the overlap between each proposal and the ground truth box, followed by a winner-takes-all ranking or non-maximum suppression. In this work, we propose a simple yet effective alternative. For proposal regression, we solve a simpler problem where we regress to the area of intersection between proposal and ground truth. In this way, each proposal only specifies which part contains the object, avoiding a blind inpainting problem where proposals need to be regressed beyond their visual scope. In turn, we replace the winner-takes-all strategy and obtain the final prediction by taking the union over the regressed intersections of a proposal group surrounding an object. Our revisited approach comes with minimal changes to the detection pipeline and can be plugged into any existing method. We show that our approach directly improves canonical object detection and instance segmentation architectures, highlighting the utility of intersection-based regression and grouping.
Detecting Objects with Graph Priors and Graph Refinement
Dec 23, 2022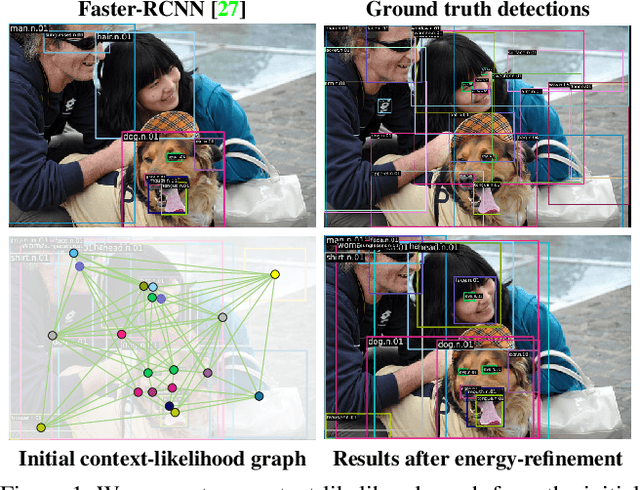



The goal of this paper is to detect objects by exploiting their interrelationships. Rather than relying on predefined and labeled graph structures, we infer a graph prior from object co-occurrence statistics. The key idea of our paper is to model object relations as a function of initial class predictions and co-occurrence priors to generate a graph representation of an image for improved classification and bounding box regression. We additionally learn the object-relation joint distribution via energy based modeling. Sampling from this distribution generates a refined graph representation of the image which in turn produces improved detection performance. Experiments on the Visual Genome and MS-COCO datasets demonstrate our method is detector agnostic, end-to-end trainable, and especially beneficial for rare object classes. What is more, we establish a consistent improvement over object detectors like DETR and Faster-RCNN, as well as state-of-the-art methods modeling object interrelationships.
Reinforced Feature Points: Optimizing Feature Detection and Description for a High-Level Task
Dec 02, 2019
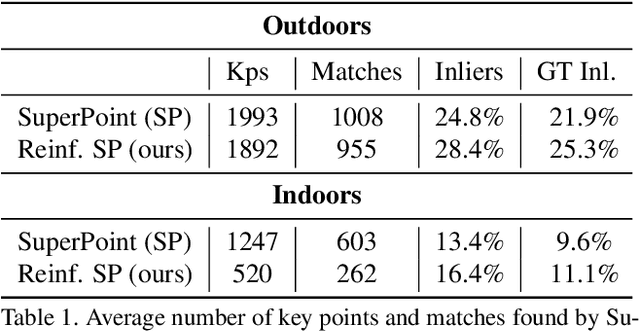
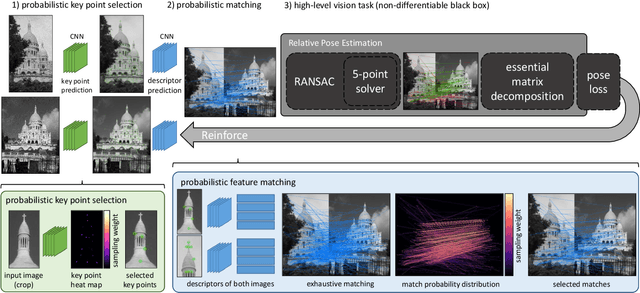
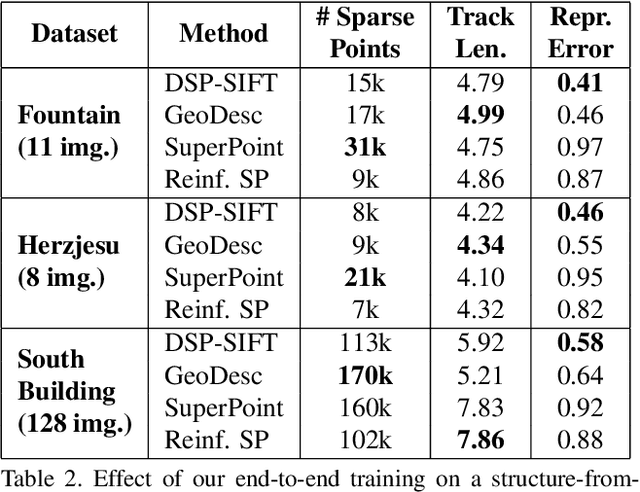
We address a core problem of computer vision: Detection and description of 2D feature points for image matching. For a long time, hand-crafted designs, like the seminal SIFT algorithm, were unsurpassed in accuracy and efficiency. Recently, learned feature detectors emerged that implement detection and description using neural networks. Training these networks usually resorts to optimizing low-level matching scores, often pre-defining sets of image patches which should or should not match, or which should or should not contain key points. Unfortunately, increased accuracy for these low-level matching scores does not necessarily translate to better performance in high-level vision tasks. We propose a new training methodology which embeds the feature detector in a complete vision pipeline, and where the learnable parameters are trained in an end-to-end fashion. We overcome the discrete nature of key point selection and descriptor matching using principles from reinforcement learning. As an example, we address the task of relative pose estimation between a pair of images. We demonstrate that the accuracy of a state-of-the-art learning-based feature detector can be increased when trained for the task it is supposed to solve at test time. Our training methodology poses little restrictions on the task to learn, and works for any architecture which predicts key point heat maps, and descriptors for key point locations.