 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Ground VLMs without Forgetting
Paper and Code
Oct 14, 2024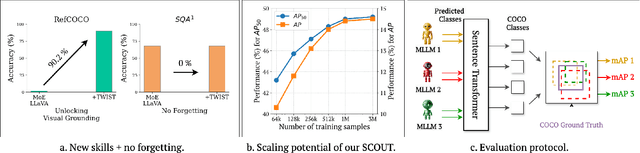

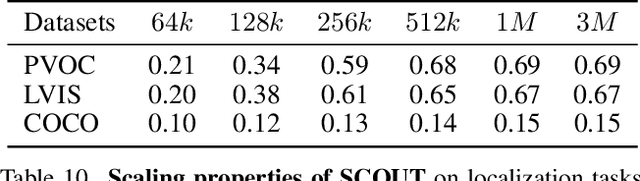
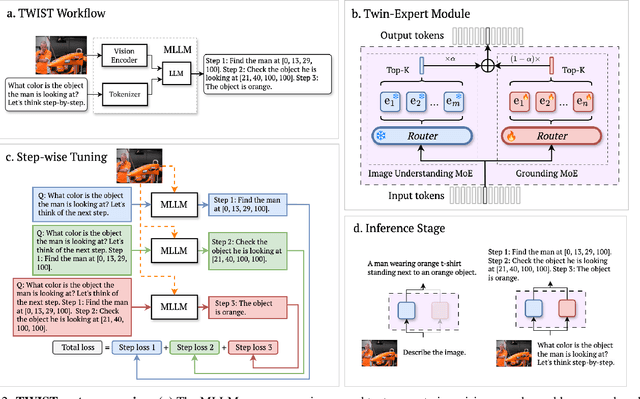
Spatial awareness is key to enable embodied multimodal AI systems. Yet, without vast amounts of spatial supervision, current Visual Language Models (VLMs) struggle at this task. In this paper, we introduce LynX, a framework that equips pretrained VLMs with visual grounding ability without forgetting their existing image and language understanding skills. To this end, we propose a Dual Mixture of Experts module that modifies only the decoder layer of the language model, using one frozen Mixture of Experts (MoE) pre-trained on image and language understanding and another learnable MoE for new grounding capabilities. This allows the VLM to retain previously learned knowledge and skills, while acquiring what is missing. To train the model effectively, we generate a high-quality synthetic dataset we call SCouT, which mimics human reasoning in visual grounding. This dataset provides rich supervision signals, describing a step-by-step multimodal reasoning process, thereby simplifying the task of visual grounding. We evaluate LynX on several object detection and visual grounding datasets, demonstrating strong performance in object detection, zero-shot localization and grounded reasoning while maintaining its original image and language understanding capabilities on seven standard benchmark datasets.