 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAVeS: Steering Safety Judgments in Vision-Language Models via Semantic Cues
Mar 19, 2026Vision-language models (VLMs) are increasingly deployed in real-world and embodied settings where safety decisions depend on visual context. However, it remains unclear which visual evidence drives these judgments. We study whether multimodal safety behavior in VLMs can be steered by simple semantic cues. We introduce a semantic steering framework that applies controlled textual, visual, and cognitive interventions without changing the underlying scene content. To evaluate these effects, we propose SAVeS, a benchmark for situational safety under semantic cues, together with an evaluation protocol that separates behavioral refusal, grounded safety reasoning, and false refusals. Experiments across multiple VLMs and an additional state-of-the-art benchmark show that safety decisions are highly sensitive to semantic cues, indicating reliance on learned visual-linguistic associations rather than grounded visual understanding. We further demonstrate that automated steering pipelines can exploit these mechanisms, highlighting a potential vulnerability in multimodal safety systems.
CURE: Curriculum-guided Multi-task Training for Reliable Anatomy Grounded Report Generation
Jan 21, 2026Medical vision-language models can automate the generation of radiology reports but struggle with accurate visual grounding and factual consistency. Existing models often misalign textual findings with visual evidence, leading to unreliable or weakly grounded predictions. We present CURE, an error-aware curriculum learning framework that improves grounding and report quality without any additional data. CURE fine-tunes a multimodal instructional model on phrase grounding, grounded report generation, and anatomy-grounded report generation using public datasets. The method dynamically adjusts sampling based on model performance, emphasizing harder samples to improve spatial and textual alignment. CURE improves grounding accuracy by +0.37 IoU, boosts report quality by +0.188 CXRFEScore, and reduces hallucinations by 18.6%. CURE is a data-efficient framework that enhances both grounding accuracy and report reliability. Code is available at https://github.com/PabloMessina/CURE and model weights at https://huggingface.co/pamessina/medgemma-4b-it-cure
CAPTAIN: Semantic Feature Injection for Memorization Mitigation in Text-to-Image Diffusion Models
Dec 11, 2025Diffusion models can unintentionally reproduce training examples, raising privacy and copyright concerns as these systems are increasingly deployed at scale. Existing inference-time mitigation methods typically manipulate classifier-free guidance (CFG) or perturb prompt embeddings; however, they often struggle to reduce memorization without compromising alignment with the conditioning prompt. We introduce CAPTAIN, a training-free framework that mitigates memorization by directly modifying latent features during denoising. CAPTAIN first applies frequency-based noise initialization to reduce the tendency to replicate memorized patterns early in the denoising process. It then identifies the optimal denoising timesteps for feature injection and localizes memorized regions. Finally, CAPTAIN injects semantically aligned features from non-memorized reference images into localized latent regions, suppressing memorization while preserving prompt fidelity and visual quality. Our experiments show that CAPTAIN achieves substantial reductions in memorization compared to CFG-based baselines while maintaining strong alignment with the intended prompt.
Multimodal Safety Evaluation in Generative Agent Social Simulations
Oct 09, 2025



Can generative agents be trusted in multimodal environments? Despite advances in large language and vision-language models that enable agents to act autonomously and pursue goals in rich settings, their ability to reason about safety, coherence, and trust across modalities remains limited. We introduce a reproducible simulation framework for evaluating agents along three dimensions: (1) safety improvement over time, including iterative plan revisions in text-visual scenarios; (2) detection of unsafe activities across multiple categories of social situations; and (3) social dynamics, measured as interaction counts and acceptance ratios of social exchanges. Agents are equipped with layered memory, dynamic planning, multimodal perception, and are instrumented with SocialMetrics, a suite of behavioral and structural metrics that quantifies plan revisions, unsafe-to-safe conversions, and information diffusion across networks. Experiments show that while agents can detect direct multimodal contradictions, they often fail to align local revisions with global safety, reaching only a 55 percent success rate in correcting unsafe plans. Across eight simulation runs with three models - Claude, GPT-4o mini, and Qwen-VL - five agents achieved average unsafe-to-safe conversion rates of 75, 55, and 58 percent, respectively. Overall performance ranged from 20 percent in multi-risk scenarios with GPT-4o mini to 98 percent in localized contexts such as fire/heat with Claude. Notably, 45 percent of unsafe actions were accepted when paired with misleading visuals, showing a strong tendency to overtrust images. These findings expose critical limitations in current architectures and provide a reproducible platform for studying multimodal safety, coherence, and social dynamics.
SoccerNet 2025 Challenges Results
Aug 26, 2025The SoccerNet 2025 Challenges mark the fifth annual edition of the SoccerNet open benchmarking effort, dedicated to advancing computer vision research in football video understanding. This year's challenges span four vision-based tasks: (1) Team Ball Action Spotting, focused on detecting ball-related actions in football broadcasts and assigning actions to teams; (2) Monocular Depth Estimation, targeting the recovery of scene geometry from single-camera broadcast clips through relative depth estimation for each pixel; (3) Multi-View Foul Recognition, requiring the analysis of multiple synchronized camera views to classify fouls and their severity; and (4) Game State Reconstruction, aimed at localizing and identifying all players from a broadcast video to reconstruct the game state on a 2D top-view of the field. Across all tasks, participants were provided with large-scale annotated datasets, unified evaluation protocols, and strong baselines as starting points. This report presents the results of each challenge, highlights the top-performing solutions, and provides insights into the progress made by the community. The SoccerNet Challenges continue to serve as a driving force for reproducible, open research at the intersection of computer vision, artificial intelligence, and sports. Detailed information about the tasks, challenges, and leaderboards can be found at https://www.soccer-net.org, with baselines and development kits available at https://github.com/SoccerNet.
Structured-Noise Masked Modeling for Video, Audio and Beyond
Mar 20, 2025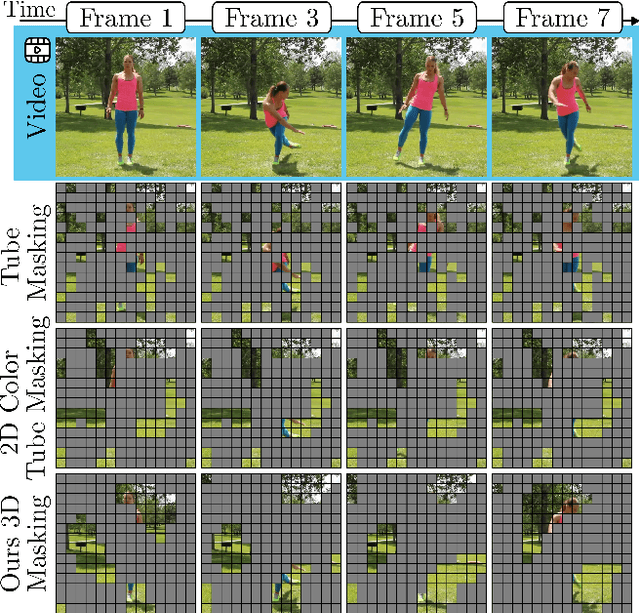
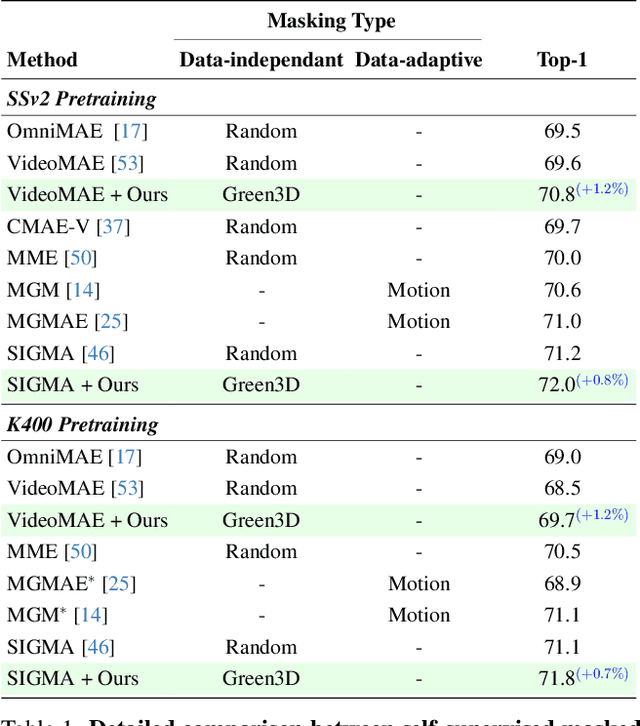
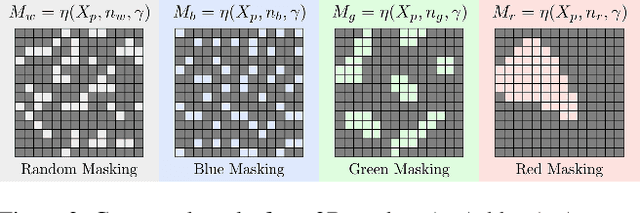

Masked modeling has emerged as a powerful self-supervised learning framework, but existing methods largely rely on random masking, disregarding the structural properties of different modalities. In this work, we introduce structured noise-based masking, a simple yet effective approach that naturally aligns with the spatial, temporal, and spectral characteristics of video and audio data. By filtering white noise into distinct color noise distributions, we generate structured masks that preserve modality-specific patterns without requiring handcrafted heuristics or access to the data. Our approach improves the performance of masked video and audio modeling frameworks without any computational overhead. Extensive experiments demonstrate that structured noise masking achieves consistent improvement over random masking for standard and advanced masked modeling methods, highlighting the importance of modality-aware masking strategies for representation learning.
OpenTAD: A Unified Framework and Comprehensive Study of Temporal Action Detection
Feb 27, 2025Temporal action detection (TAD) is a fundamental video understanding task that aims to identify human actions and localize their temporal boundaries in videos. Although this field has achieved remarkable progress in recent years, further progress and real-world applications are impeded by the absence of a standardized framework. Currently, different methods are compared under different implementation settings, evaluation protocols, etc., making it difficult to assess the real effectiveness of a specific technique. To address this issue, we propose \textbf{OpenTAD}, a unified TAD framework consolidating 16 different TAD methods and 9 standard datasets into a modular codebase. In OpenTAD, minimal effort is required to replace one module with a different design, train a feature-based TAD model in end-to-end mode, or switch between the two. OpenTAD also facilitates straightforward benchmarking across various datasets and enables fair and in-depth comparisons among different methods. With OpenTAD, we comprehensively study how innovations in different network components affect detection performance and identify the most effective design choices through extensive experiments. This study has led to a new state-of-the-art TAD method built upon existing techniques for each component. We have made our code and models available at https://github.com/sming256/OpenTAD.
SoccerNet 2024 Challenges Results
Sep 16, 2024

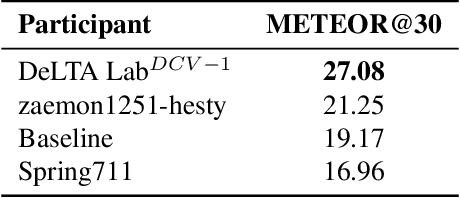
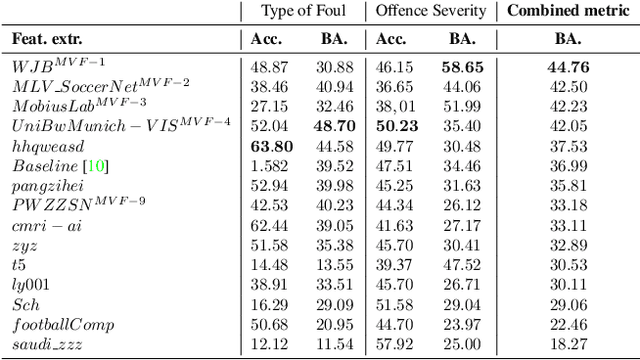
The SoccerNet 2024 challenges represent the fourth annual video understanding challenges organized by the SoccerNet team. These challenges aim to advance research across multiple themes in football, including broadcast video understanding, field understanding, and player understanding. This year, the challenges encompass four vision-based tasks. (1) Ball Action Spotting, focusing on precisely localizing when and which soccer actions related to the ball occur, (2) Dense Video Captioning, focusing on describing the broadcast with natural language and anchored timestamps, (3) Multi-View Foul Recognition, a novel task focusing on analyzing multiple viewpoints of a potential foul incident to classify whether a foul occurred and assess its severity, (4) Game State Reconstruction, another novel task focusing on reconstructing the game state from broadcast videos onto a 2D top-view map of the field. Detailed information about the tasks, challenges, and leaderboards can be found at https://www.soccer-net.org, with baselines and development kits available at https://github.com/SoccerNet.
CO2Wounds-V2: Extended Chronic Wounds Dataset From Leprosy Patients
Aug 20, 2024Chronic wounds pose an ongoing health concern globally, largely due to the prevalence of conditions such as diabetes and leprosy's disease. The standard method of monitoring these wounds involves visual inspection by healthcare professionals, a practice that could present challenges for patients in remote areas with inadequate transportation and healthcare infrastructure. This has led to the development of algorithms designed for the analysis and follow-up of wound images, which perform image-processing tasks such as classification, detection, and segmentation. However, the effectiveness of these algorithms heavily depends on the availability of comprehensive and varied wound image data, which is usually scarce. This paper introduces the CO2Wounds-V2 dataset, an extended collection of RGB wound images from leprosy patients with their corresponding semantic segmentation annotations, aiming to enhance the development and testing of image-processing algorithms in the medical field.
ColorMAE: Exploring data-independent masking strategies in Masked AutoEncoders
Jul 17, 2024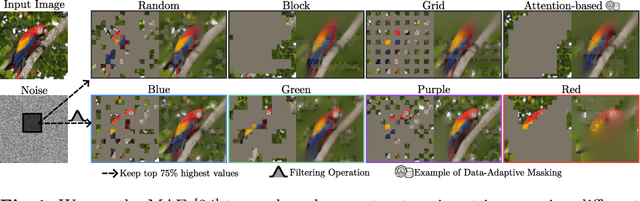

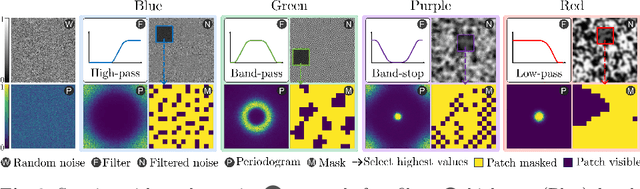

Masked AutoEncoders (MAE) have emerged as a robust self-supervised framework, offering remarkable performance across a wide range of downstream tasks. To increase the difficulty of the pretext task and learn richer visual representations, existing works have focused on replacing standard random masking with more sophisticated strategies, such as adversarial-guided and teacher-guided masking. However, these strategies depend on the input data thus commonly increasing the model complexity and requiring additional calculations to generate the mask patterns. This raises the question: Can we enhance MAE performance beyond random masking without relying on input data or incurring additional computational costs? In this work, we introduce a simple yet effective data-independent method, termed ColorMAE, which generates different binary mask patterns by filtering random noise. Drawing inspiration from color noise in image processing, we explore four types of filters to yield mask patterns with different spatial and semantic priors. ColorMAE requires no additional learnable parameters or computational overhead in the network, yet it significantly enhances the learned representations. We provide a comprehensive empirical evaluation, demonstrating our strategy's superiority in downstream tasks compared to random masking. Notably, we report an improvement of 2.72 in mIoU in semantic segmentation tasks relative to baseline MAE implementations.