 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResidualViT for Efficient Temporally Dense Video Encoding
Sep 16, 2025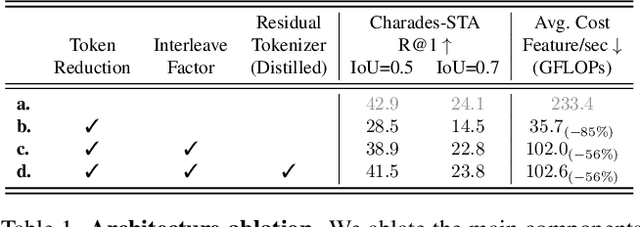
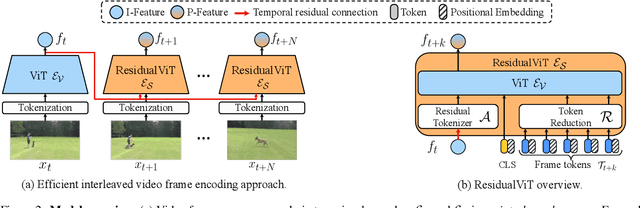
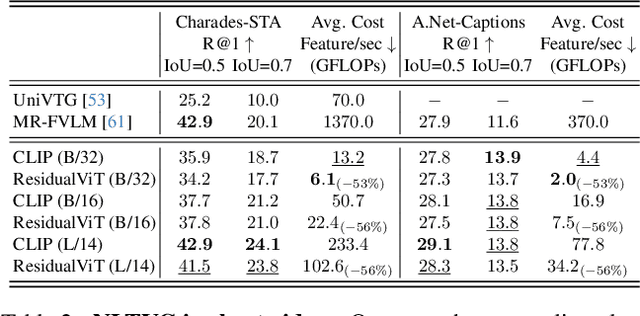

Several video understanding tasks, such as natural language temporal video grounding, temporal activity localization, and audio description generation, require "temporally dense" reasoning over frames sampled at high temporal resolution. However, computing frame-level features for these tasks is computationally expensive given the temporal resolution requirements. In this paper, we make three contributions to reduce the cost of computing features for temporally dense tasks. First, we introduce a vision transformer (ViT) architecture, dubbed ResidualViT, that leverages the large temporal redundancy in videos to efficiently compute temporally dense frame-level features. Our architecture incorporates (i) learnable residual connections that ensure temporal consistency across consecutive frames and (ii) a token reduction module that enhances processing speed by selectively discarding temporally redundant information while reusing weights of a pretrained foundation model. Second, we propose a lightweight distillation strategy to approximate the frame-level features of the original foundation model. Finally, we evaluate our approach across four tasks and five datasets, in both zero-shot and fully supervised settings, demonstrating significant reductions in computational cost (up to 60%) and improvements in inference speed (up to 2.5x faster), all while closely approximating the accuracy of the original foundation model.
OpenTAD: A Unified Framework and Comprehensive Study of Temporal Action Detection
Feb 27, 2025Temporal action detection (TAD) is a fundamental video understanding task that aims to identify human actions and localize their temporal boundaries in videos. Although this field has achieved remarkable progress in recent years, further progress and real-world applications are impeded by the absence of a standardized framework. Currently, different methods are compared under different implementation settings, evaluation protocols, etc., making it difficult to assess the real effectiveness of a specific technique. To address this issue, we propose \textbf{OpenTAD}, a unified TAD framework consolidating 16 different TAD methods and 9 standard datasets into a modular codebase. In OpenTAD, minimal effort is required to replace one module with a different design, train a feature-based TAD model in end-to-end mode, or switch between the two. OpenTAD also facilitates straightforward benchmarking across various datasets and enables fair and in-depth comparisons among different methods. With OpenTAD, we comprehensively study how innovations in different network components affect detection performance and identify the most effective design choices through extensive experiments. This study has led to a new state-of-the-art TAD method built upon existing techniques for each component. We have made our code and models available at https://github.com/sming256/OpenTAD.
Compressed-Language Models for Understanding Compressed File Formats: a JPEG Exploration
May 27, 2024This study investigates whether Compressed-Language Models (CLMs), i.e. language models operating on raw byte streams from Compressed File Formats~(CFFs), can understand files compressed by CFFs. We focus on the JPEG format as a representative CFF, given its commonality and its representativeness of key concepts in compression, such as entropy coding and run-length encoding. We test if CLMs understand the JPEG format by probing their capabilities to perform along three axes: recognition of inherent file properties, handling of files with anomalies, and generation of new files. Our findings demonstrate that CLMs can effectively perform these tasks. These results suggest that CLMs can understand the semantics of compressed data when directly operating on the byte streams of files produced by CFFs. The possibility to directly operate on raw compressed files offers the promise to leverage some of their remarkable characteristics, such as their ubiquity, compactness, multi-modality and segment-nature.
Towards Automated Movie Trailer Generation
Apr 04, 2024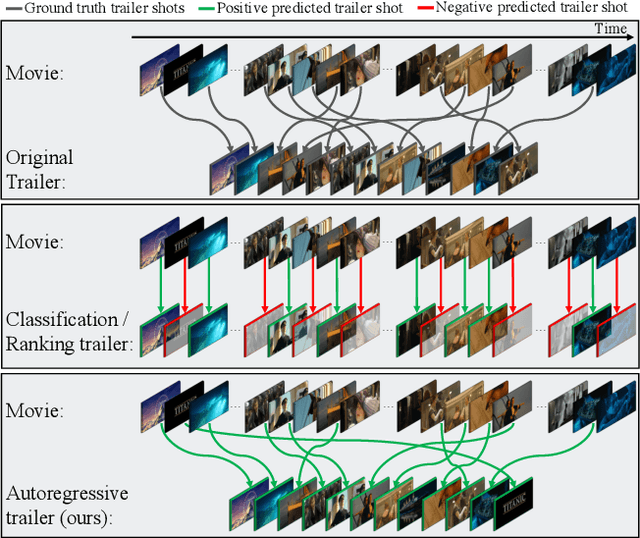

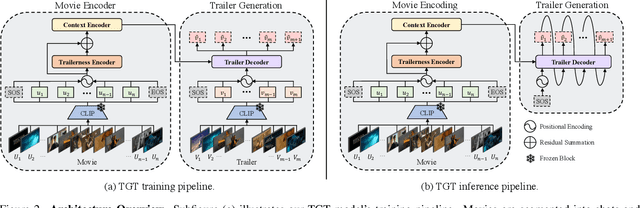
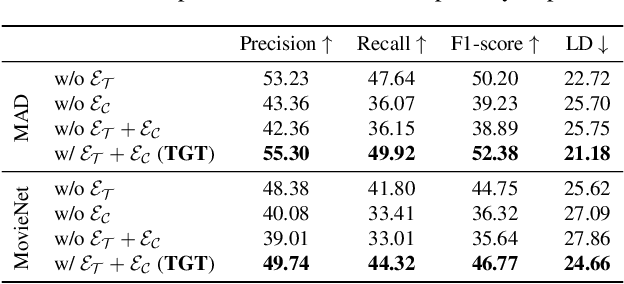
Movie trailers are an essential tool for promoting films and attracting audiences. However, the process of creating trailers can be time-consuming and expensive. To streamline this process, we propose an automatic trailer generation framework that generates plausible trailers from a full movie by automating shot selection and composition. Our approach draws inspiration from machine translation techniques and models the movies and trailers as sequences of shots, thus formulating the trailer generation problem as a sequence-to-sequence task. We introduce Trailer Generation Transformer (TGT), a deep-learning framework utilizing an encoder-decoder architecture. TGT movie encoder is tasked with contextualizing each movie shot representation via self-attention, while the autoregressive trailer decoder predicts the feature representation of the next trailer shot, accounting for the relevance of shots' temporal order in trailers. Our TGT significantly outperforms previous methods on a comprehensive suite of metrics.
Boundary-Denoising for Video Activity Localization
Apr 06, 2023



Video activity localization aims at understanding the semantic content in long untrimmed videos and retrieving actions of interest. The retrieved action with its start and end locations can be used for highlight generation, temporal action detection, etc. Unfortunately, learning the exact boundary location of activities is highly challenging because temporal activities are continuous in time, and there are often no clear-cut transitions between actions. Moreover, the definition of the start and end of events is subjective, which may confuse the model. To alleviate the boundary ambiguity, we propose to study the video activity localization problem from a denoising perspective. Specifically, we propose an encoder-decoder model named DenoiseLoc. During training, a set of action spans is randomly generated from the ground truth with a controlled noise scale. Then we attempt to reverse this process by boundary denoising, allowing the localizer to predict activities with precise boundaries and resulting in faster convergence speed. Experiments show that DenoiseLoc advances %in several video activity understanding tasks. For example, we observe a gain of +12.36% average mAP on QV-Highlights dataset and +1.64% mAP@0.5 on THUMOS'14 dataset over the baseline. Moreover, DenoiseLoc achieves state-of-the-art performance on TACoS and MAD datasets, but with much fewer predictions compared to other current methods.
Localizing Moments in Long Video Via Multimodal Guidance
Feb 26, 2023



The recent introduction of the large-scale long-form MAD dataset for language grounding in videos has enabled researchers to investigate the performance of current state-of-the-art methods in the long-form setup, with unexpected findings. In fact, current grounding methods alone fail at tackling this challenging task and setup due to their inability to process long video sequences. In this work, we propose an effective way to circumvent the long-form burden by introducing a new component to grounding pipelines: a Guidance model. The purpose of the Guidance model is to efficiently remove irrelevant video segments from the search space of grounding methods by coarsely aligning the sentence to chunks of the movies and then applying legacy grounding methods where high correlation is found. We term these video segments as non-describable moments. This two-stage approach reveals to be effective in boosting the performance of several different grounding baselines on the challenging MAD dataset, achieving new state-of-the-art performance.
Egocentric Video-Language Pretraining @ Ego4D Challenge 2022
Jul 04, 2022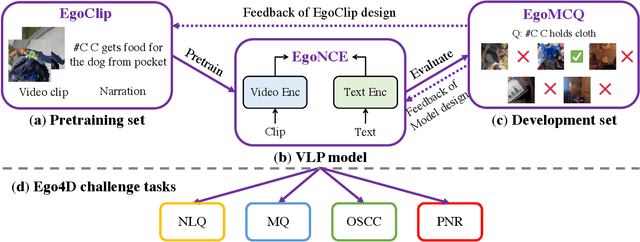
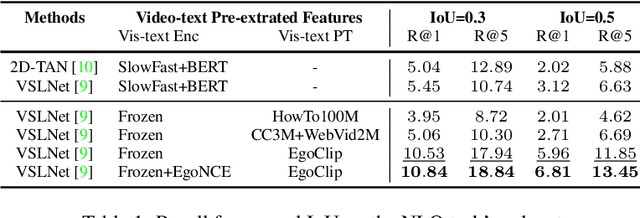
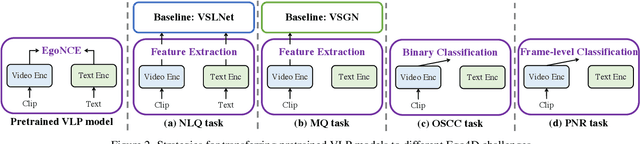
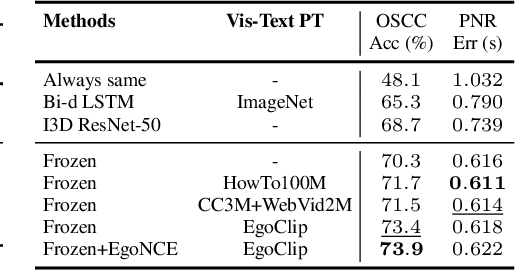
In this report, we propose a video-language pretraining (VLP) based solution \cite{kevin2022egovlp} for four Ego4D challenge tasks, including Natural Language Query (NLQ), Moment Query (MQ), Object State Change Classification (OSCC), and PNR Localization (PNR). Especially, we exploit the recently released Ego4D dataset \cite{grauman2021ego4d} to pioneer Egocentric VLP from pretraining dataset, pretraining objective, and development set. Based on the above three designs, we develop a pretrained video-language model that is able to transfer its egocentric video-text representation or video-only representation to several video downstream tasks. Our Egocentric VLP achieves 10.46R@1&IoU @0.3 on NLQ, 10.33 mAP on MQ, 74% Acc on OSCC, 0.67 sec error on PNR. The code is available at https://github.com/showlab/EgoVLP.
Egocentric Video-Language Pretraining
Jun 03, 2022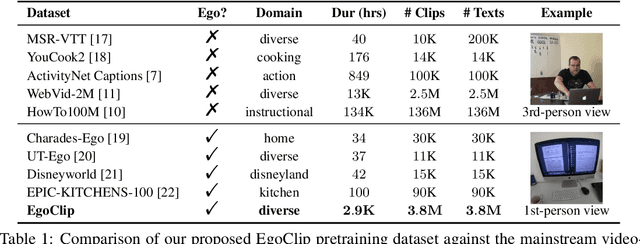
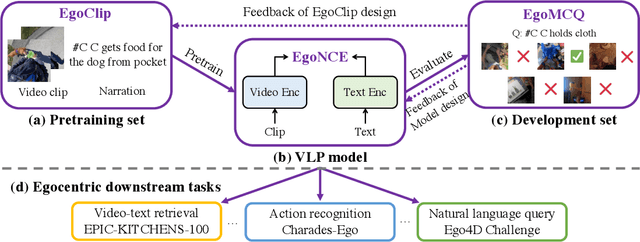

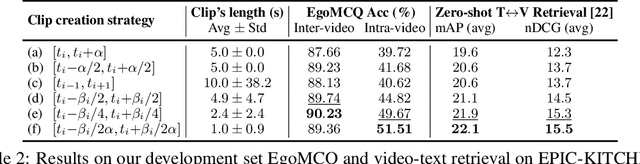
Video-Language Pretraining (VLP), aiming to learn transferable representation to advance a wide range of video-text downstream tasks, has recently received increasing attention. Dominant works that achieve strong performance rely on large-scale, 3rd-person video-text datasets, such as HowTo100M. In this work, we exploit the recently released Ego4D dataset to pioneer Egocentric VLP along three directions. (i) We create EgoClip, a 1st-person video-text pretraining dataset comprising 3.8M clip-text pairs well-chosen from Ego4D, covering a large variety of human daily activities. (ii) We propose a novel pretraining objective, dubbed as EgoNCE, which adapts video-text contrastive learning to egocentric domain by mining egocentric-aware positive and negative samples. (iii) We introduce EgoMCQ, a development benchmark that is close to EgoClip and hence can support effective validation and fast exploration of our design decisions regarding EgoClip and EgoNCE. Furthermore, we demonstrate strong performance on five egocentric downstream tasks across three datasets: video-text retrieval on EPIC-KITCHENS-100; action recognition on Charades-Ego; and natural language query, moment query, and object state change classification on Ego4D challenge benchmarks. The dataset and code will be available at https://github.com/showlab/EgoVLP.
MAD: A Scalable Dataset for Language Grounding in Videos from Movie Audio Descriptions
Dec 01, 2021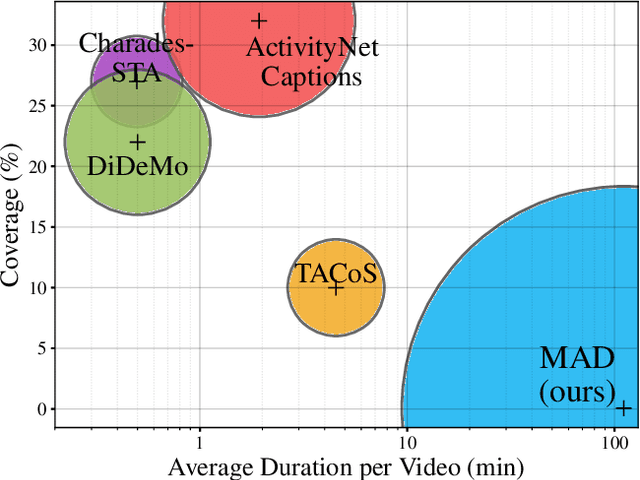
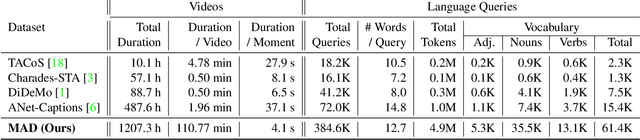


The recent and increasing interest in video-language research has driven the development of large-scale datasets that enable data-intensive machine learning techniques. In comparison, limited effort has been made at assessing the fitness of these datasets for the video-language grounding task. Recent works have begun to discover significant limitations in these datasets, suggesting that state-of-the-art techniques commonly overfit to hidden dataset biases. In this work, we present MAD (Movie Audio Descriptions), a novel benchmark that departs from the paradigm of augmenting existing video datasets with text annotations and focuses on crawling and aligning available audio descriptions of mainstream movies. MAD contains over 384,000 natural language sentences grounded in over 1,200 hours of video and exhibits a significant reduction in the currently diagnosed biases for video-language grounding datasets. MAD's collection strategy enables a novel and more challenging version of video-language grounding, where short temporal moments (typically seconds long) must be accurately grounded in diverse long-form videos that can last up to three hours.
VLG-Net: Video-Language Graph Matching Network for Video Grounding
Nov 19, 2020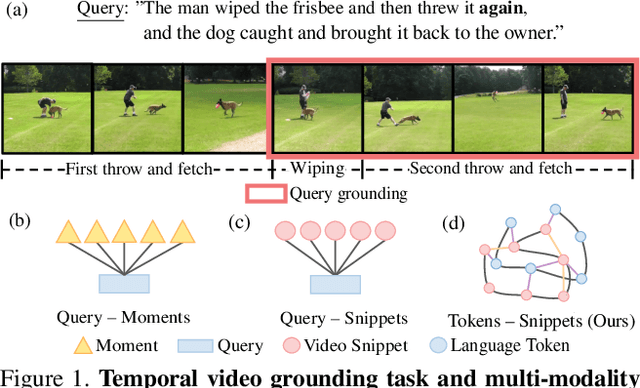

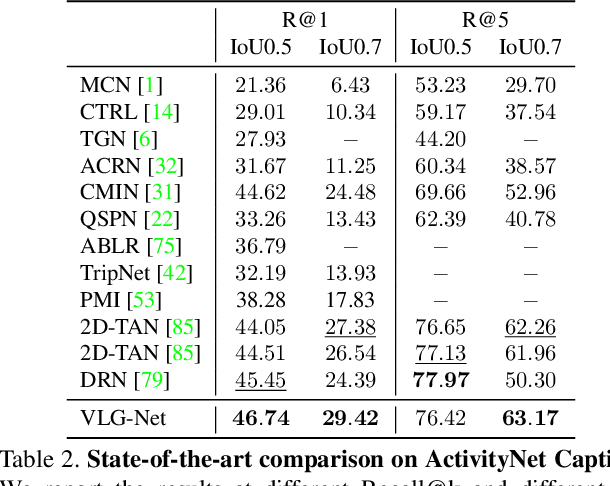
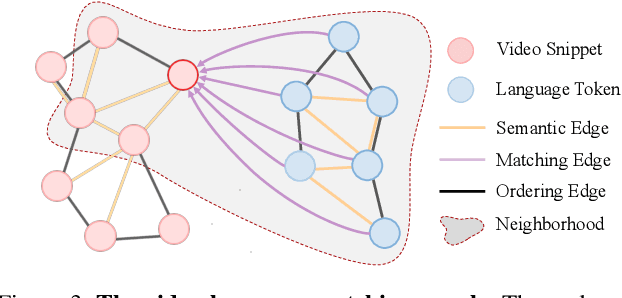
Grounding language queries in videos aims at identifying the time interval (or moment) semantically relevant to a language query. The solution to this challenging task demands the understanding of videos' and queries' semantic content and the fine-grained reasoning about their multi-modal interactions. Our key idea is to recast this challenge into an algorithmic graph matching problem. Fueled by recent advances in Graph Neural Networks, we propose to leverage Graph Convolutional Networks to model video and textual information as well as their semantic alignment. To enable the mutual exchange of information across the domains, we design a novel Video-Language Graph Matching Network (VLG-Net) to match video and query graphs. Core ingredients include representation graphs, built on top of video snippets and query tokens separately, which are used for modeling the intra-modality relationships. A Graph Matching layer is adopted for cross-modal context modeling and multi-modal fusion. Finally, moment candidates are created using masked moment attention pooling by fusing the moment's enriched snippet features. We demonstrate superior performance over state-of-the-art grounding methods on three widely used datasets for temporal localization of moments in videos with natural language queries: ActivityNet-Captions, TACoS, and DiDeMo.