 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantum LEGO Learning: A Modular Design Principle for Hybrid Artificial Intelligence
Jan 29, 2026Hybrid quantum-classical learning models increasingly integrate neural networks with variational quantum circuits (VQCs) to exploit complementary inductive biases. However, many existing approaches rely on tightly coupled architectures or task-specific encoders, limiting conceptual clarity, generality, and transferability across learning settings. In this work, we introduce Quantum LEGO Learning, a modular and architecture-agnostic learning framework that treats classical and quantum components as reusable, composable learning blocks with well-defined roles. Within this framework, a pre-trained classical neural network serves as a frozen feature block, while a VQC acts as a trainable adaptive module that operates on structured representations rather than raw inputs. This separation enables efficient learning under constrained quantum resources and provides a principled abstraction for analyzing hybrid models. We develop a block-wise generalization theory that decomposes learning error into approximation and estimation components, explicitly characterizing how the complexity and training status of each block influence overall performance. Our analysis generalizes prior tensor-network-specific results and identifies conditions under which quantum modules provide representational advantages over comparably sized classical heads. Empirically, we validate the framework through systematic block-swap experiments across frozen feature extractors and both quantum and classical adaptive heads. Experiments on quantum dot classification demonstrate stable optimization, reduced sensitivity to qubit count, and robustness to realistic noise.
Interpretable Causal Representation Learning for Biological Data in the Pathway Space
Jun 14, 2025


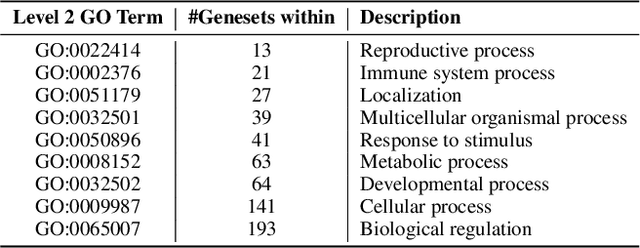
Predicting the impact of genomic and drug perturbations in cellular function is crucial for understanding gene functions and drug effects, ultimately leading to improved therapies. To this end, Causal Representation Learning (CRL) constitutes one of the most promising approaches, as it aims to identify the latent factors that causally govern biological systems, thus facilitating the prediction of the effect of unseen perturbations. Yet, current CRL methods fail in reconciling their principled latent representations with known biological processes, leading to models that are not interpretable. To address this major issue, we present SENA-discrepancy-VAE, a model based on the recently proposed CRL method discrepancy-VAE, that produces representations where each latent factor can be interpreted as the (linear) combination of the activity of a (learned) set of biological processes. To this extent, we present an encoder, SENA-{\delta}, that efficiently compute and map biological processes' activity levels to the latent causal factors. We show that SENA-discrepancy-VAE achieves predictive performances on unseen combinations of interventions that are comparable with its original, non-interpretable counterpart, while inferring causal latent factors that are biologically meaningful.
Advancing the Scientific Method with Large Language Models: From Hypothesis to Discovery
May 22, 2025With recent Nobel Prizes recognising AI contributions to science, Large Language Models (LLMs) are transforming scientific research by enhancing productivity and reshaping the scientific method. LLMs are now involved in experimental design, data analysis, and workflows, particularly in chemistry and biology. However, challenges such as hallucinations and reliability persist. In this contribution, we review how Large Language Models (LLMs) are redefining the scientific method and explore their potential applications across different stages of the scientific cycle, from hypothesis testing to discovery. We conclude that, for LLMs to serve as relevant and effective creative engines and productivity enhancers, their deep integration into all steps of the scientific process should be pursued in collaboration and alignment with human scientific goals, with clear evaluation metrics. The transition to AI-driven science raises ethical questions about creativity, oversight, and responsibility. With careful guidance, LLMs could evolve into creative engines, driving transformative breakthroughs across scientific disciplines responsibly and effectively. However, the scientific community must also decide how much it leaves to LLMs to drive science, even when associations with 'reasoning', mostly currently undeserved, are made in exchange for the potential to explore hypothesis and solution regions that might otherwise remain unexplored by human exploration alone.
* 45 pages
Leveraging Pre-Trained Neural Networks to Enhance Machine Learning with Variational Quantum Circuits
Nov 13, 2024Quantum Machine Learning (QML) offers tremendous potential but is currently limited by the availability of qubits. We introduce an innovative approach that utilizes pre-trained neural networks to enhance Variational Quantum Circuits (VQC). This technique effectively separates approximation error from qubit count and removes the need for restrictive conditions, making QML more viable for real-world applications. Our method significantly improves parameter optimization for VQC while delivering notable gains in representation and generalization capabilities, as evidenced by rigorous theoretical analysis and extensive empirical testing on quantum dot classification tasks. Moreover, our results extend to applications such as human genome analysis, demonstrating the broad applicability of our approach. By addressing the constraints of current quantum hardware, our work paves the way for a new era of advanced QML applications, unlocking the full potential of quantum computing in fields such as machine learning, materials science, medicine, mimetics, and various interdisciplinary areas.
VLG-Net: Video-Language Graph Matching Network for Video Grounding
Nov 19, 2020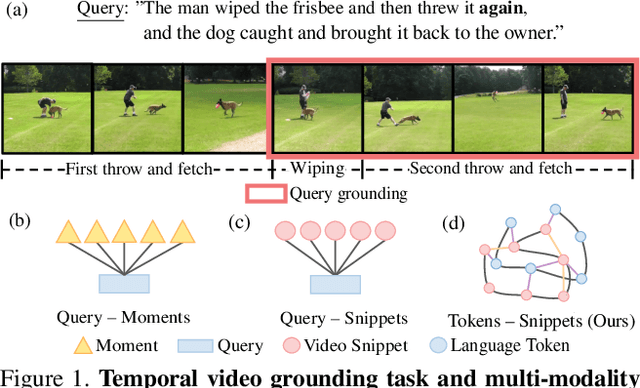

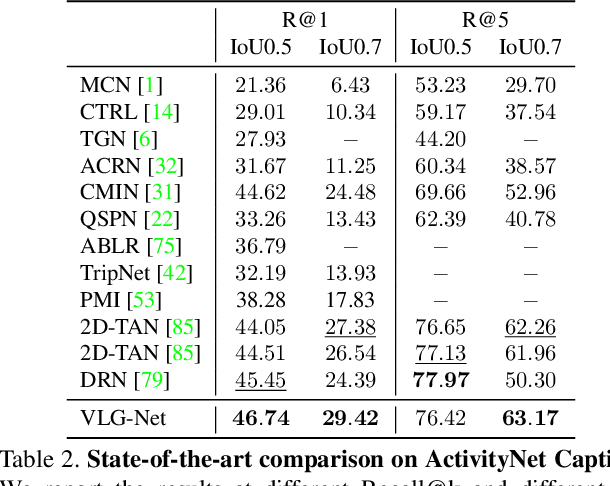
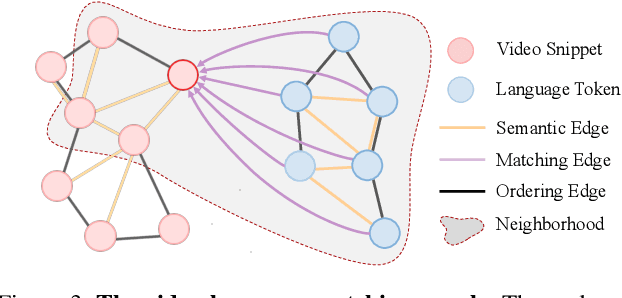
Grounding language queries in videos aims at identifying the time interval (or moment) semantically relevant to a language query. The solution to this challenging task demands the understanding of videos' and queries' semantic content and the fine-grained reasoning about their multi-modal interactions. Our key idea is to recast this challenge into an algorithmic graph matching problem. Fueled by recent advances in Graph Neural Networks, we propose to leverage Graph Convolutional Networks to model video and textual information as well as their semantic alignment. To enable the mutual exchange of information across the domains, we design a novel Video-Language Graph Matching Network (VLG-Net) to match video and query graphs. Core ingredients include representation graphs, built on top of video snippets and query tokens separately, which are used for modeling the intra-modality relationships. A Graph Matching layer is adopted for cross-modal context modeling and multi-modal fusion. Finally, moment candidates are created using masked moment attention pooling by fusing the moment's enriched snippet features. We demonstrate superior performance over state-of-the-art grounding methods on three widely used datasets for temporal localization of moments in videos with natural language queries: ActivityNet-Captions, TACoS, and DiDeMo.
DeepOpht: Medical Report Generation for Retinal Images via Deep Models and Visual Explanation
Nov 01, 2020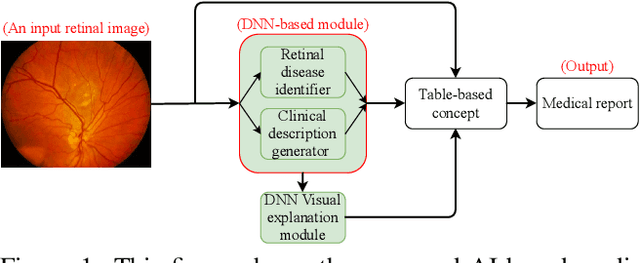
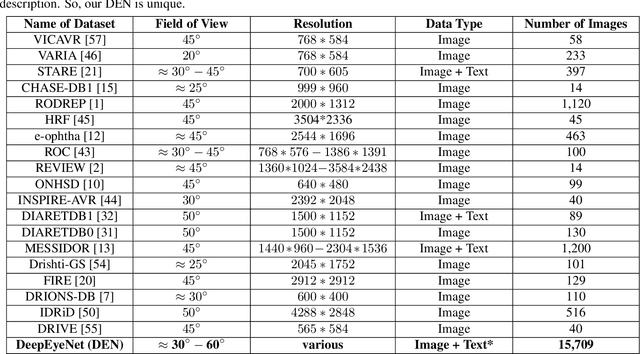
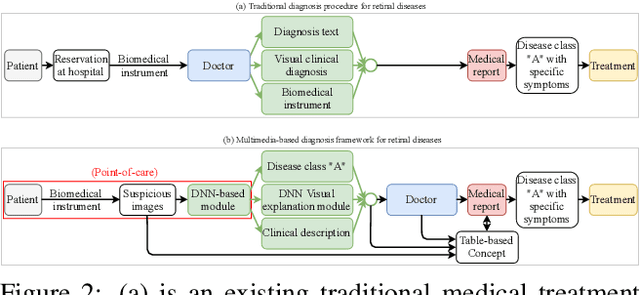
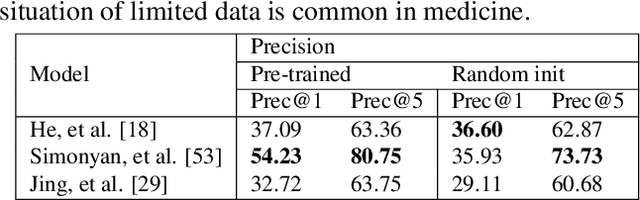
In this work, we propose an AI-based method that intends to improve the conventional retinal disease treatment procedure and help ophthalmologists increase diagnosis efficiency and accuracy. The proposed method is composed of a deep neural networks-based (DNN-based) module, including a retinal disease identifier and clinical description generator, and a DNN visual explanation module. To train and validate the effectiveness of our DNN-based module, we propose a large-scale retinal disease image dataset. Also, as ground truth, we provide a retinal image dataset manually labeled by ophthalmologists to qualitatively show, the proposed AI-based method is effective. With our experimental results, we show that the proposed method is quantitatively and qualitatively effective. Our method is capable of creating meaningful retinal image descriptions and visual explanations that are clinically relevant.
Interpretable Self-Attention Temporal Reasoning for Driving Behavior Understanding
Nov 06, 2019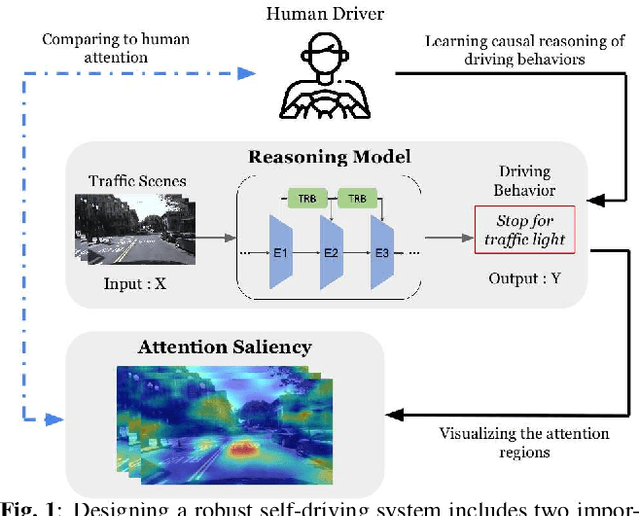
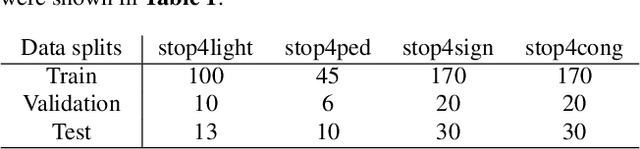
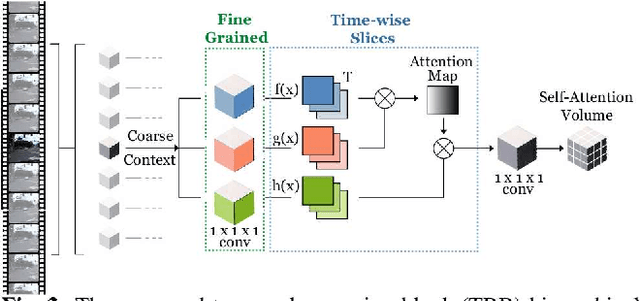
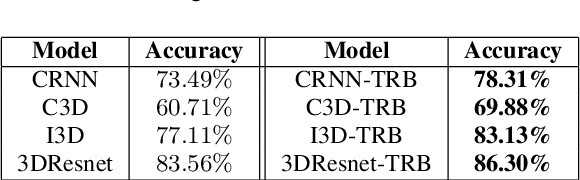
Performing driving behaviors based on causal reasoning is essential to ensure driving safety. In this work, we investigated how state-of-the-art 3D Convolutional Neural Networks (CNNs) perform on classifying driving behaviors based on causal reasoning. We proposed a perturbation-based visual explanation method to inspect the models' performance visually. By examining the video attention saliency, we found that existing models could not precisely capture the causes (e.g., traffic light) of the specific action (e.g., stopping). Therefore, the Temporal Reasoning Block (TRB) was proposed and introduced to the models. With the TRB models, we achieved the accuracy of $\mathbf{86.3\%}$, which outperform the state-of-the-art 3D CNNs from previous works. The attention saliency also demonstrated that TRB helped models focus on the causes more precisely. With both numerical and visual evaluations, we concluded that our proposed TRB models were able to provide accurate driving behavior prediction by learning the causal reasoning of the behaviors.
Synthesizing New Retinal Symptom Images by Multiple Generative Models
Feb 11, 2019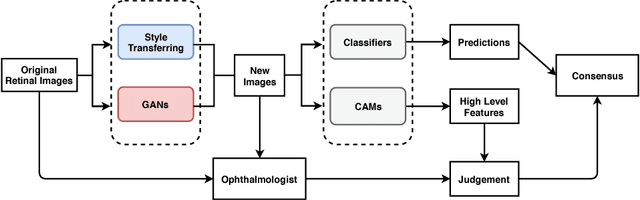
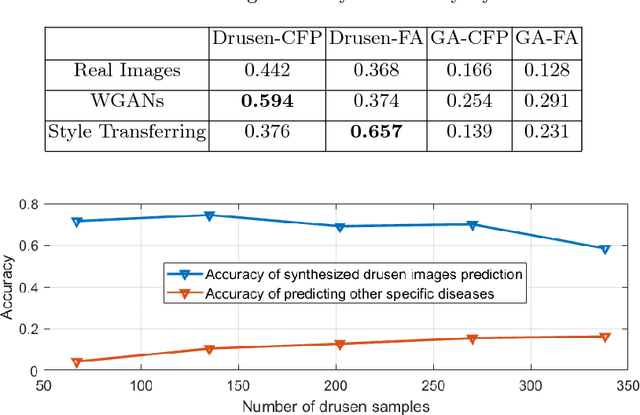
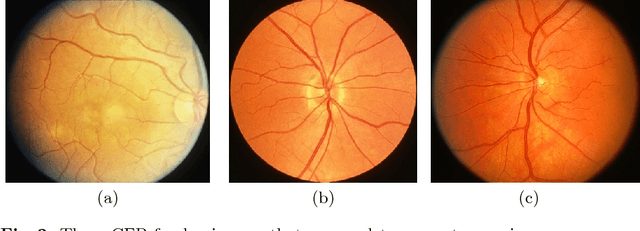
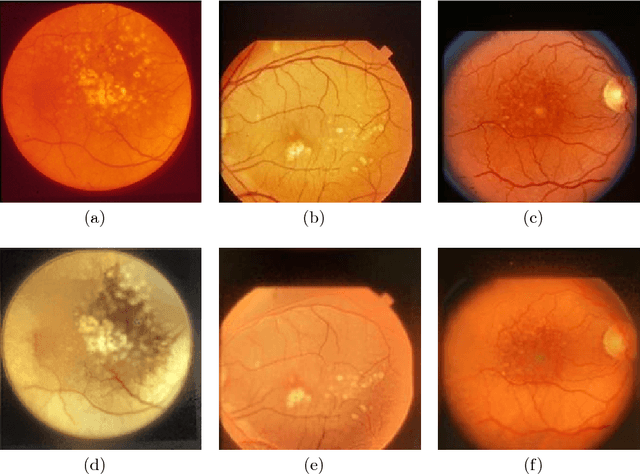
Age-Related Macular Degeneration (AMD) is an asymptomatic retinal disease which may result in loss of vision. There is limited access to high-quality relevant retinal images and poor understanding of the features defining sub-classes of this disease. Motivated by recent advances in machine learning we specifically explore the potential of generative modeling, using Generative Adversarial Networks (GANs) and style transferring, to facilitate clinical diagnosis and disease understanding by feature extraction. We design an analytic pipeline which first generates synthetic retinal images from clinical images; a subsequent verification step is applied. In the synthesizing step we merge GANs (DCGANs and WGANs architectures) and style transferring for the image generation, whereas the verified step controls the accuracy of the generated images. We find that the generated images contain sufficient pathological details to facilitate ophthalmologists' task of disease classification and in discovery of disease relevant features. In particular, our system predicts the drusen and geographic atrophy sub-classes of AMD. Furthermore, the performance using CFP images for GANs outperforms the classification based on using only the original clinical dataset. Our results are evaluated using existing classifier of retinal diseases and class activated maps, supporting the predictive power of the synthetic images and their utility for feature extraction. Our code examples are available online.
Auto-Classification of Retinal Diseases in the Limit of Sparse Data Using a Two-Streams Machine Learning Model
Nov 01, 2018

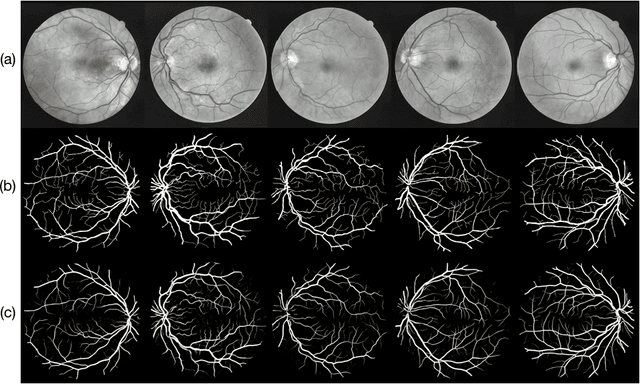
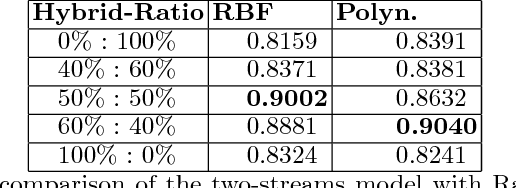
Automatic clinical diagnosis of retinal diseases has emerged as a promising approach to facilitate discovery in areas with limited access to specialists. Based on the fact that fundus structure and vascular disorders are the main characteristics of retinal diseases, we propose a novel visual-assisted diagnosis hybrid model mixing the support vector machine (SVM) and deep neural networks (DNNs). Furthermore, we present a new clinical retina dataset, called EyeNet2, for ophthalmology incorporating 52 retina diseases classes. Using EyeNet2, our model achieves 90.43\% diagnosis accuracy, and the model performance is comparable to the professional ophthalmologists.
* A extension work of a workshop paper arXiv admin note: substantial text overlap with arXiv:1806.06423
A Novel Hybrid Machine Learning Model for Auto-Classification of Retinal Diseases
Jun 17, 2018
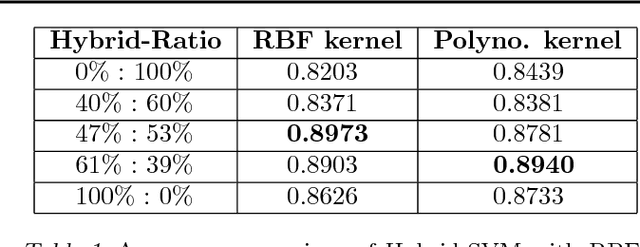
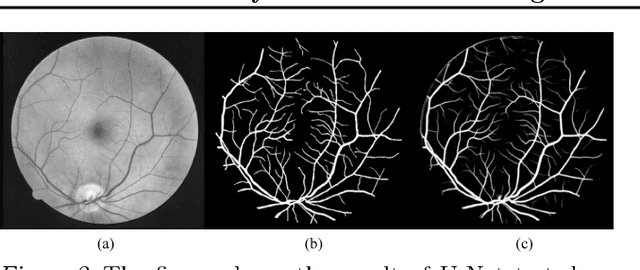
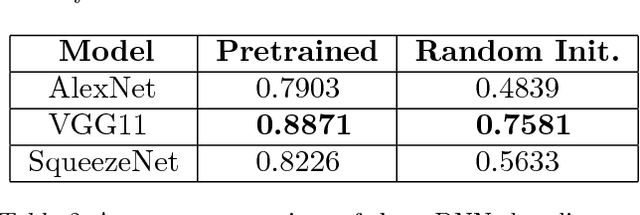
Automatic clinical diagnosis of retinal diseases has emerged as a promising approach to facilitate discovery in areas with limited access to specialists. We propose a novel visual-assisted diagnosis hybrid model based on the support vector machine (SVM) and deep neural networks (DNNs). The model incorporates complementary strengths of DNNs and SVM. Furthermore, we present a new clinical retina label collection for ophthalmology incorporating 32 retina diseases classes. Using EyeNet, our model achieves 89.73% diagnosis accuracy and the model performance is comparable to the professional ophthalmologists.
* Accepted at the Joint ICML and IJCAI Workshop on Computational Biology (ICML-IJCAI WCB) to be held in Stockholm SWEDEN, 2018. Referring to https://sites.google.com/view/wcb2018/accepted-papers?authuser=0