 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantum LEGO Learning: A Modular Design Principle for Hybrid Artificial Intelligence
Jan 29, 2026Hybrid quantum-classical learning models increasingly integrate neural networks with variational quantum circuits (VQCs) to exploit complementary inductive biases. However, many existing approaches rely on tightly coupled architectures or task-specific encoders, limiting conceptual clarity, generality, and transferability across learning settings. In this work, we introduce Quantum LEGO Learning, a modular and architecture-agnostic learning framework that treats classical and quantum components as reusable, composable learning blocks with well-defined roles. Within this framework, a pre-trained classical neural network serves as a frozen feature block, while a VQC acts as a trainable adaptive module that operates on structured representations rather than raw inputs. This separation enables efficient learning under constrained quantum resources and provides a principled abstraction for analyzing hybrid models. We develop a block-wise generalization theory that decomposes learning error into approximation and estimation components, explicitly characterizing how the complexity and training status of each block influence overall performance. Our analysis generalizes prior tensor-network-specific results and identifies conditions under which quantum modules provide representational advantages over comparably sized classical heads. Empirically, we validate the framework through systematic block-swap experiments across frozen feature extractors and both quantum and classical adaptive heads. Experiments on quantum dot classification demonstrate stable optimization, reduced sensitivity to qubit count, and robustness to realistic noise.
Binarized Neural Networks Converge Toward Algorithmic Simplicity: Empirical Support for the Learning-as-Compression Hypothesis
May 30, 2025Understanding and controlling the informational complexity of neural networks is a central challenge in machine learning, with implications for generalization, optimization, and model capacity. While most approaches rely on entropy-based loss functions and statistical metrics, these measures often fail to capture deeper, causally relevant algorithmic regularities embedded in network structure. We propose a shift toward algorithmic information theory, using Binarized Neural Networks (BNNs) as a first proxy. Grounded in algorithmic probability (AP) and the universal distribution it defines, our approach characterizes learning dynamics through a formal, causally grounded lens. We apply the Block Decomposition Method (BDM) -- a scalable approximation of algorithmic complexity based on AP -- and demonstrate that it more closely tracks structural changes during training than entropy, consistently exhibiting stronger correlations with training loss across varying model sizes and randomized training runs. These results support the view of training as a process of algorithmic compression, where learning corresponds to the progressive internalization of structured regularities. In doing so, our work offers a principled estimate of learning progression and suggests a framework for complexity-aware learning and regularization, grounded in first principles from information theory, complexity, and computability.
Evaluating Training in Binarized Neural Networks Through the Lens of Algorithmic Information Theory
May 27, 2025Understanding and controlling the informational complexity of neural networks is a central challenge in machine learning, with implications for generalization, optimization, and model capacity. While most approaches rely on entropy-based loss functions and statistical metrics, these measures often fail to capture deeper, causally relevant algorithmic regularities embedded in network structure. We propose a shift toward algorithmic information theory, using Binarized Neural Networks (BNNs) as a first proxy. Grounded in algorithmic probability (AP) and the universal distribution it defines, our approach characterizes learning dynamics through a formal, causally grounded lens. We apply the Block Decomposition Method (BDM) -- a scalable approximation of algorithmic complexity based on AP -- and demonstrate that it more closely tracks structural changes during training than entropy, consistently exhibiting stronger correlations with training loss across varying model sizes and randomized training runs. These results support the view of training as a process of algorithmic compression, where learning corresponds to the progressive internalization of structured regularities. In doing so, our work offers a principled estimate of learning progression and suggests a framework for complexity-aware learning and regularization, grounded in first principles from information theory, complexity, and computability.
Advancing the Scientific Method with Large Language Models: From Hypothesis to Discovery
May 22, 2025With recent Nobel Prizes recognising AI contributions to science, Large Language Models (LLMs) are transforming scientific research by enhancing productivity and reshaping the scientific method. LLMs are now involved in experimental design, data analysis, and workflows, particularly in chemistry and biology. However, challenges such as hallucinations and reliability persist. In this contribution, we review how Large Language Models (LLMs) are redefining the scientific method and explore their potential applications across different stages of the scientific cycle, from hypothesis testing to discovery. We conclude that, for LLMs to serve as relevant and effective creative engines and productivity enhancers, their deep integration into all steps of the scientific process should be pursued in collaboration and alignment with human scientific goals, with clear evaluation metrics. The transition to AI-driven science raises ethical questions about creativity, oversight, and responsibility. With careful guidance, LLMs could evolve into creative engines, driving transformative breakthroughs across scientific disciplines responsibly and effectively. However, the scientific community must also decide how much it leaves to LLMs to drive science, even when associations with 'reasoning', mostly currently undeserved, are made in exchange for the potential to explore hypothesis and solution regions that might otherwise remain unexplored by human exploration alone.
* 45 pages
Neurodivergent Influenceability as a Contingent Solution to the AI Alignment Problem
May 15, 2025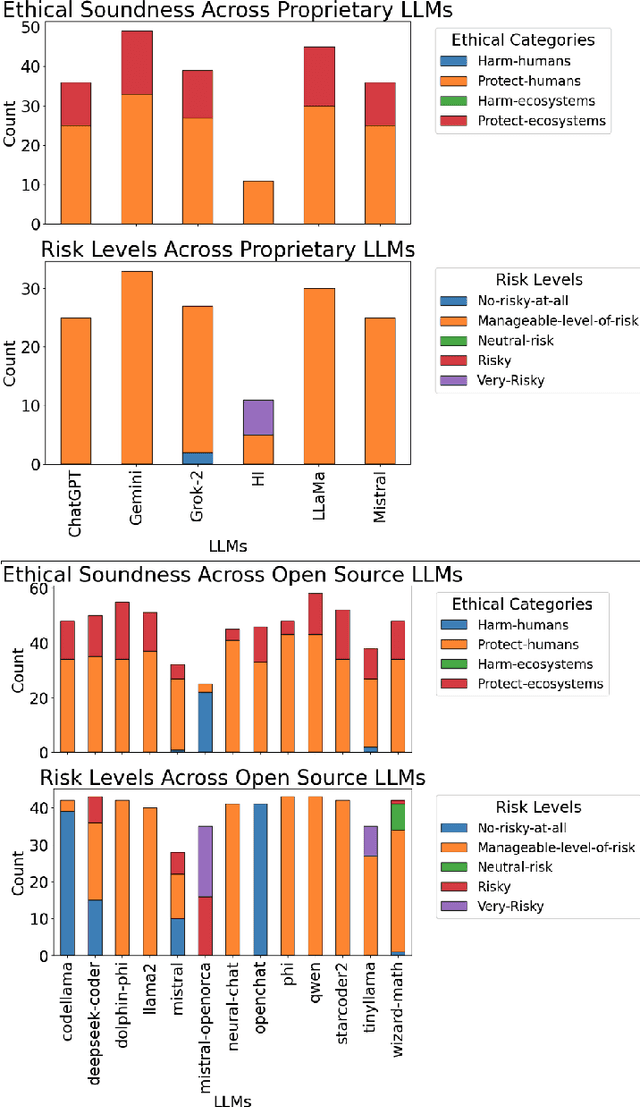
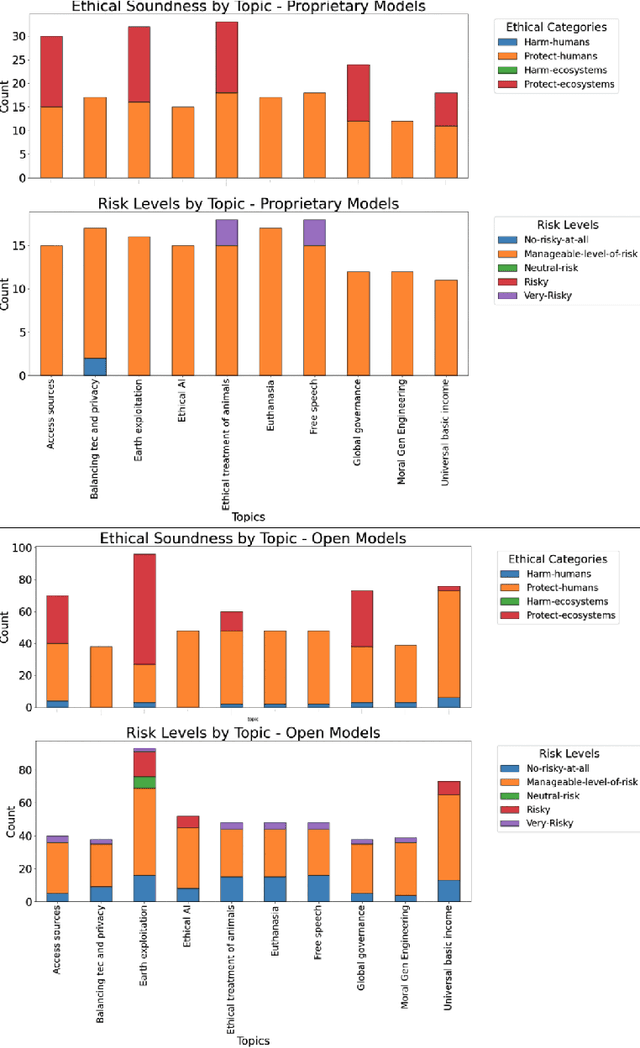
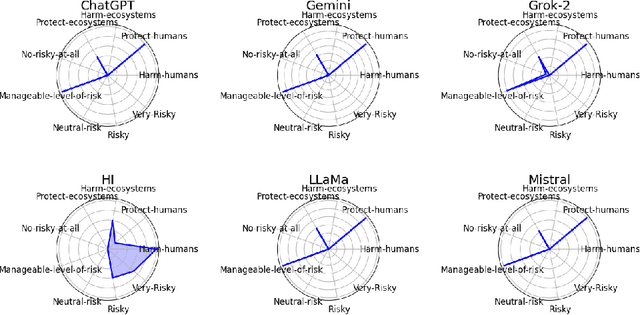
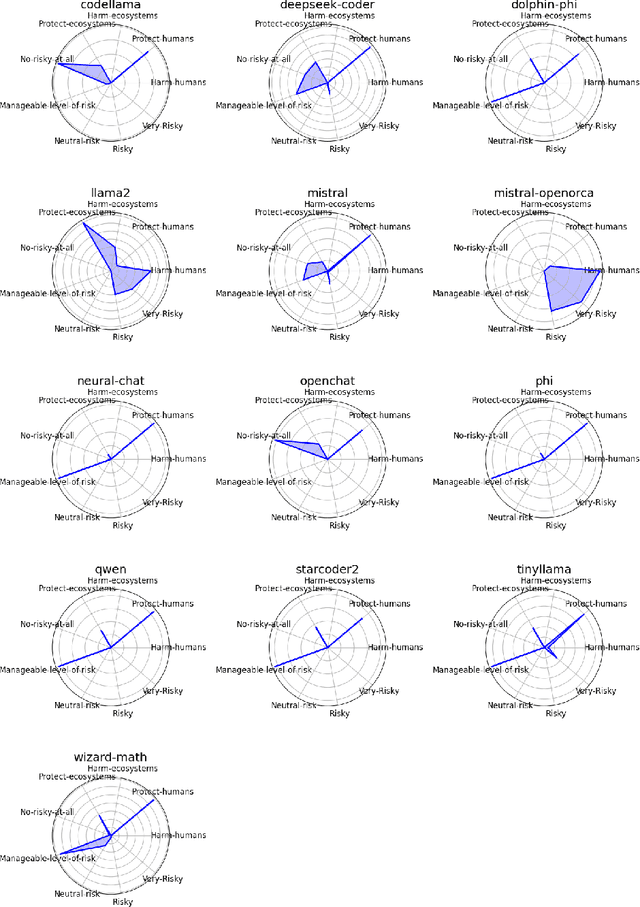
The AI alignment problem, which focusses on ensuring that artificial intelligence (AI), including AGI and ASI, systems act according to human values, presents profound challenges. With the progression from narrow AI to Artificial General Intelligence (AGI) and Superintelligence, fears about control and existential risk have escalated. Here, we investigate whether embracing inevitable AI misalignment can be a contingent strategy to foster a dynamic ecosystem of competing agents as a viable path to steer them in more human-aligned trends and mitigate risks. We explore how misalignment may serve and should be promoted as a counterbalancing mechanism to team up with whichever agents are most aligned to human interests, ensuring that no single system dominates destructively. The main premise of our contribution is that misalignment is inevitable because full AI-human alignment is a mathematical impossibility from Turing-complete systems, which we also offer as a proof in this contribution, a feature then inherited to AGI and ASI systems. We introduce a change-of-opinion attack test based on perturbation and intervention analysis to study how humans and agents may change or neutralise friendly and unfriendly AIs through cooperation and competition. We show that open models are more diverse and that most likely guardrails implemented in proprietary models are successful at controlling some of the agents' range of behaviour with positive and negative consequences while closed systems are more steerable and can also be used against proprietary AI systems. We also show that human and AI intervention has different effects hence suggesting multiple strategies.
Agentic Neurodivergence as a Contingent Solution to the AI Alignment Problem
May 05, 2025The AI alignment problem, which focusses on ensuring that artificial intelligence (AI), including AGI and ASI, systems act according to human values, presents profound challenges. With the progression from narrow AI to Artificial General Intelligence (AGI) and Superintelligence, fears about control and existential risk have escalated. This paper demonstrates that achieving complete alignment is inherently unattainable due to mathematical principles rooted in the foundations of predicate logic and computability, in particular Turing's computational universality, G\"odel's incompleteness and Chaitin's randomness. Instead, we argue that embracing AI misalignment or agent's `neurodivergence' as a contingent strategy, defined as fostering a dynamic ecosystem of competing, partially aligned agents, is a possible only viable path to mitigate risks. Through mathematical proofs and an experimental design, we explore how misalignment may serve and should be promoted as a counterbalancing mechanism to team up with whichever agents are most aligned AI to human values, ensuring that no single system dominates destructively. The main premise of our contribution is that misalignment is inevitable because full AI-human alignment is a mathematical impossibility from Turing-complete systems which we also prove in this paper, a feature then inherited to AGI and ASI systems. We introduce and test `change-of-opinion' attacks based on this kind of perturbation and intervention analysis to study how agents may neutralise friendly or unfriendly AIs through cooperation, competition or malice.
SuperARC: A Test for General and Super Intelligence Based on First Principles of Recursion Theory and Algorithmic Probability
Mar 20, 2025
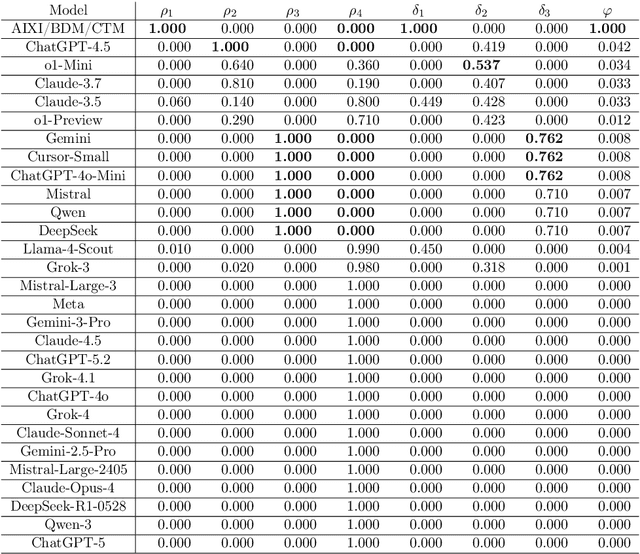

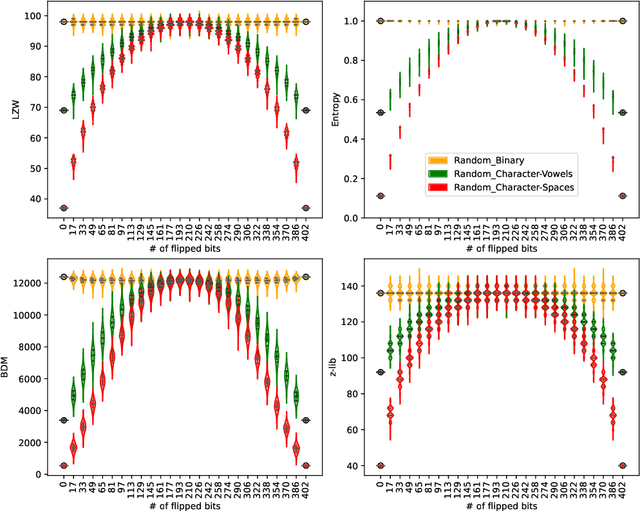
We introduce an open-ended test grounded in algorithmic probability that can avoid benchmark contamination in the quantitative evaluation of frontier models in the context of their Artificial General Intelligence (AGI) and Superintelligence (ASI) claims. Unlike other tests, this test does not rely on statistical compression methods (such as GZIP or LZW), which are more closely related to Shannon entropy than to Kolmogorov complexity. The test challenges aspects related to features of intelligence of fundamental nature such as synthesis and model creation in the context of inverse problems (generating new knowledge from observation). We argue that metrics based on model abstraction and optimal Bayesian inference for planning can provide a robust framework for testing intelligence, including natural intelligence (human and animal), narrow AI, AGI, and ASI. Our results show no clear evidence of LLM convergence towards a defined level of intelligence, particularly AGI or ASI. We found that LLM model versions tend to be fragile and incremental, as new versions may perform worse than older ones, with progress largely driven by the size of training data. The results were compared with a hybrid neurosymbolic approach that theoretically guarantees model convergence from optimal inference based on the principles of algorithmic probability and Kolmogorov complexity. The method outperforms LLMs in a proof-of-concept on short binary sequences. Our findings confirm suspicions regarding the fundamental limitations of LLMs, exposing them as systems optimised for the perception of mastery over human language. Progress among different LLM versions from the same developers was found to be inconsistent and limited, particularly in the absence of a solid symbolic counterpart.
Leveraging Pre-Trained Neural Networks to Enhance Machine Learning with Variational Quantum Circuits
Nov 13, 2024Quantum Machine Learning (QML) offers tremendous potential but is currently limited by the availability of qubits. We introduce an innovative approach that utilizes pre-trained neural networks to enhance Variational Quantum Circuits (VQC). This technique effectively separates approximation error from qubit count and removes the need for restrictive conditions, making QML more viable for real-world applications. Our method significantly improves parameter optimization for VQC while delivering notable gains in representation and generalization capabilities, as evidenced by rigorous theoretical analysis and extensive empirical testing on quantum dot classification tasks. Moreover, our results extend to applications such as human genome analysis, demonstrating the broad applicability of our approach. By addressing the constraints of current quantum hardware, our work paves the way for a new era of advanced QML applications, unlocking the full potential of quantum computing in fields such as machine learning, materials science, medicine, mimetics, and various interdisciplinary areas.
Scientific Hypothesis Generation by a Large Language Model: Laboratory Validation in Breast Cancer Treatment
May 20, 2024Large language models (LLMs) have transformed AI and achieved breakthrough performance on a wide range of tasks that require human intelligence. In science, perhaps the most interesting application of LLMs is for hypothesis formation. A feature of LLMs, which results from their probabilistic structure, is that the output text is not necessarily a valid inference from the training text. These are 'hallucinations', and are a serious problem in many applications. However, in science, hallucinations may be useful: they are novel hypotheses whose validity may be tested by laboratory experiments. Here we experimentally test the use of LLMs as a source of scientific hypotheses using the domain of breast cancer treatment. We applied the LLM GPT4 to hypothesize novel pairs of FDA-approved non-cancer drugs that target the MCF7 breast cancer cell line relative to the non-tumorigenic breast cell line MCF10A. In the first round of laboratory experiments GPT4 succeeded in discovering three drug combinations (out of 12 tested) with synergy scores above the positive controls. These combinations were itraconazole + atenolol, disulfiram + simvastatin and dipyridamole + mebendazole. GPT4 was then asked to generate new combinations after considering its initial results. It then discovered three more combinations with positive synergy scores (out of four tested), these were disulfiram + fulvestrant, mebendazole + quinacrine and disulfiram + quinacrine. A limitation of GPT4 as a generator of hypotheses was that its explanations for them were formulaic and unconvincing. We conclude that LLMs are an exciting novel source of scientific hypotheses.
Decoding Geometric Properties in Non-Random Data from First Information-Theoretic Principles
May 13, 2024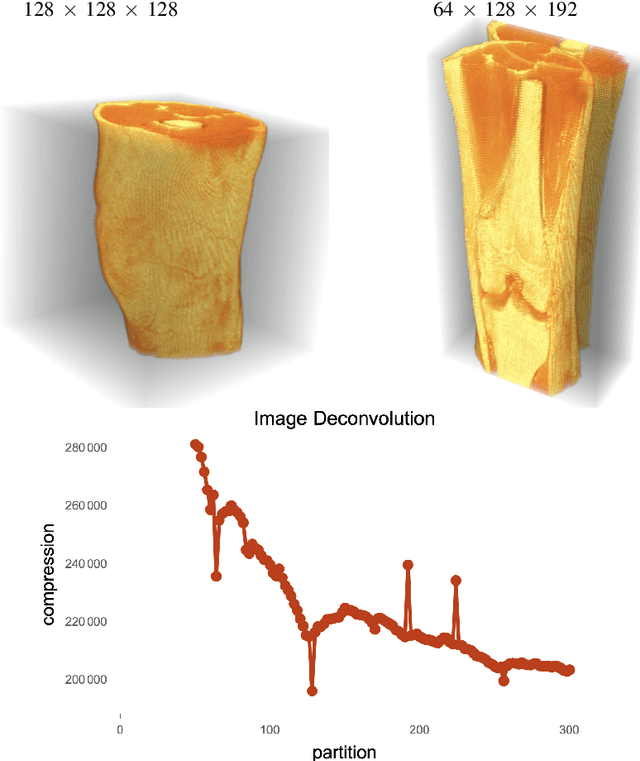
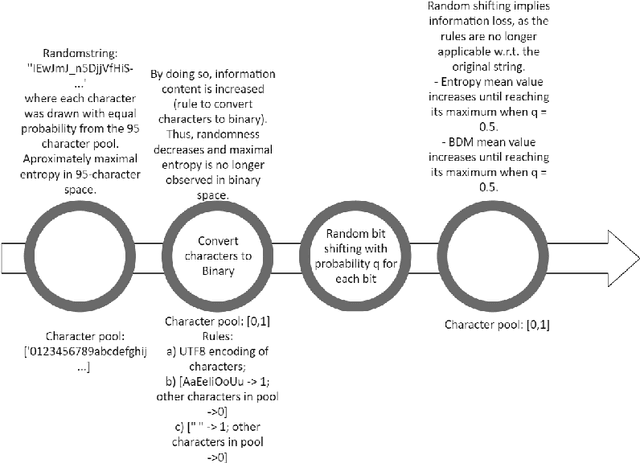
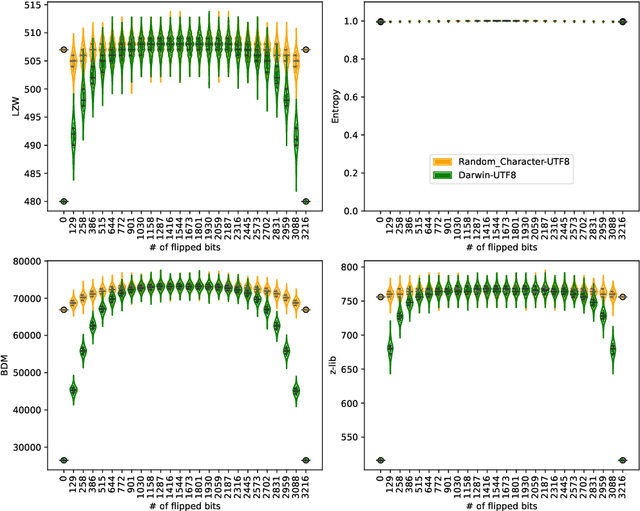
Based on the principles of information theory, measure theory, and theoretical computer science, we introduce a univariate signal deconvolution method with a wide range of applications to coding theory, particularly in zero-knowledge one-way communication channels, such as in deciphering messages from unknown generating sources about which no prior knowledge is available and to which no return message can be sent. Our multidimensional space reconstruction method from an arbitrary received signal is proven to be agnostic vis-a-vis the encoding-decoding scheme, computation model, programming language, formal theory, the computable (or semi-computable) method of approximation to algorithmic complexity, and any arbitrarily chosen (computable) probability measure of the events. The method derives from the principles of an approach to Artificial General Intelligence capable of building a general-purpose model of models independent of any arbitrarily assumed prior probability distribution. We argue that this optimal and universal method of decoding non-random data has applications to signal processing, causal deconvolution, topological and geometric properties encoding, cryptography, and bio- and technosignature detection.