 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Future of Fundamental Science Led by Generative Closed-Loop Artificial Intelligence
Jul 09, 2023



Recent advances in machine learning and AI, including Generative AI and LLMs, are disrupting technological innovation, product development, and society as a whole. AI's contribution to technology can come from multiple approaches that require access to large training data sets and clear performance evaluation criteria, ranging from pattern recognition and classification to generative models. Yet, AI has contributed less to fundamental science in part because large data sets of high-quality data for scientific practice and model discovery are more difficult to access. Generative AI, in general, and Large Language Models in particular, may represent an opportunity to augment and accelerate the scientific discovery of fundamental deep science with quantitative models. Here we explore and investigate aspects of an AI-driven, automated, closed-loop approach to scientific discovery, including self-driven hypothesis generation and open-ended autonomous exploration of the hypothesis space. Integrating AI-driven automation into the practice of science would mitigate current problems, including the replication of findings, systematic production of data, and ultimately democratisation of the scientific process. Realising these possibilities requires a vision for augmented AI coupled with a diversity of AI approaches able to deal with fundamental aspects of causality analysis and model discovery while enabling unbiased search across the space of putative explanations. These advances hold the promise to unleash AI's potential for searching and discovering the fundamental structure of our world beyond what human scientists have been able to achieve. Such a vision would push the boundaries of new fundamental science rather than automatize current workflows and instead open doors for technological innovation to tackle some of the greatest challenges facing humanity today.
CILP: Co-simulation based Imitation Learner for Dynamic Resource Provisioning in Cloud Computing Environments
Feb 11, 2023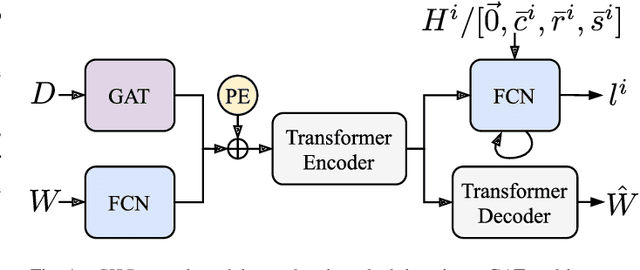

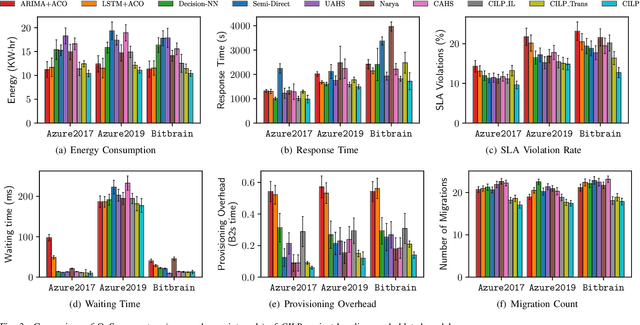

Intelligent Virtual Machine (VM) provisioning is central to cost and resource efficient computation in cloud computing environments. As bootstrapping VMs is time-consuming, a key challenge for latency-critical tasks is to predict future workload demands to provision VMs proactively. However, existing AI-based solutions \blue{tend to not holistically consider} all crucial aspects such as provisioning overheads, heterogeneous VM costs and Quality of Service (QoS) of the cloud system. To address this, we propose a novel method, called CILP, that formulates the VM provisioning problem as two sub-problems of prediction and optimization, where the provisioning plan is optimized based on predicted workload demands. CILP leverages a neural network as a surrogate model to predict future workload demands with a co-simulated digital-twin of the infrastructure to compute QoS scores. We extend the neural network to also act as an imitation learner that dynamically decides the optimal VM provisioning plan. A transformer based neural model reduces training and inference overheads while our novel two-phase decision making loop facilitates in making informed provisioning decisions. Crucially, we address limitations of prior work by including resource utilization, deployment costs and provisioning overheads to inform the provisioning decisions in our imitation learning framework. Experiments with three public benchmarks demonstrate that CILP gives up to 22% higher resource utilization, 14% higher QoS scores and 44% lower execution costs compared to the current online and offline optimization based state-of-the-art methods.
DeepFT: Fault-Tolerant Edge Computing using a Self-Supervised Deep Surrogate Model
Dec 02, 2022The emergence of latency-critical AI applications has been supported by the evolution of the edge computing paradigm. However, edge solutions are typically resource-constrained, posing reliability challenges due to heightened contention for compute and communication capacities and faulty application behavior in the presence of overload conditions. Although a large amount of generated log data can be mined for fault prediction, labeling this data for training is a manual process and thus a limiting factor for automation. Due to this, many companies resort to unsupervised fault-tolerance models. Yet, failure models of this kind can incur a loss of accuracy when they need to adapt to non-stationary workloads and diverse host characteristics. To cope with this, we propose a novel modeling approach, called DeepFT, to proactively avoid system overloads and their adverse effects by optimizing the task scheduling and migration decisions. DeepFT uses a deep surrogate model to accurately predict and diagnose faults in the system and co-simulation based self-supervised learning to dynamically adapt the model in volatile settings. It offers a highly scalable solution as the model size scales by only 3 and 1 percent per unit increase in the number of active tasks and hosts. Extensive experimentation on a Raspberry-Pi based edge cluster with DeFog benchmarks shows that DeepFT can outperform state-of-the-art baseline methods in fault-detection and QoS metrics. Specifically, DeepFT gives the highest F1 scores for fault-detection, reducing service deadline violations by up to 37\% while also improving response time by up to 9%.
DRAGON: Decentralized Fault Tolerance in Edge Federations
Aug 16, 2022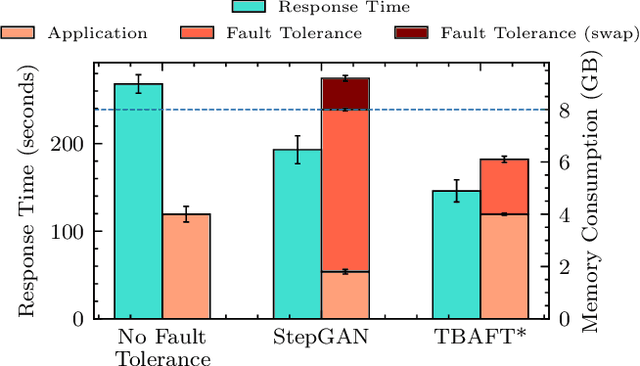
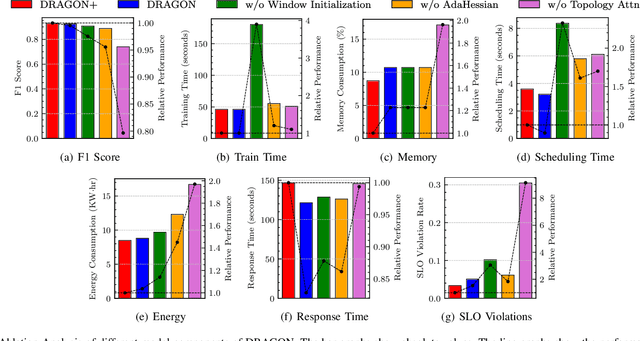
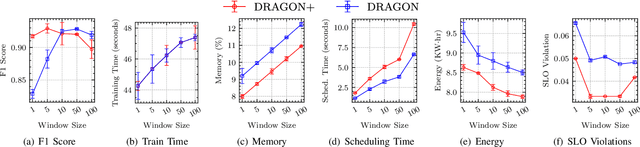
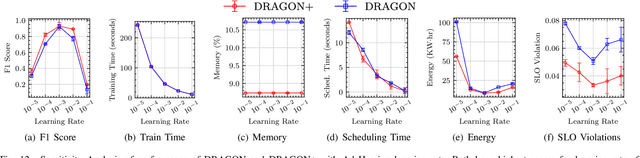
Edge Federation is a new computing paradigm that seamlessly interconnects the resources of multiple edge service providers. A key challenge in such systems is the deployment of latency-critical and AI based resource-intensive applications in constrained devices. To address this challenge, we propose a novel memory-efficient deep learning based model, namely generative optimization networks (GON). Unlike GANs, GONs use a single network to both discriminate input and generate samples, significantly reducing their memory footprint. Leveraging the low memory footprint of GONs, we propose a decentralized fault-tolerance method called DRAGON that runs simulations (as per a digital modeling twin) to quickly predict and optimize the performance of the edge federation. Extensive experiments with real-world edge computing benchmarks on multiple Raspberry-Pi based federated edge configurations show that DRAGON can outperform the baseline methods in fault-detection and Quality of Service (QoS) metrics. Specifically, the proposed method gives higher F1 scores for fault-detection than the best deep learning (DL) method, while consuming lower memory than the heuristic methods. This allows for improvement in energy consumption, response time and service level agreement violations by up to 74, 63 and 82 percent, respectively.
MetaNet: Automated Dynamic Selection of Scheduling Policies in Cloud Environments
May 21, 2022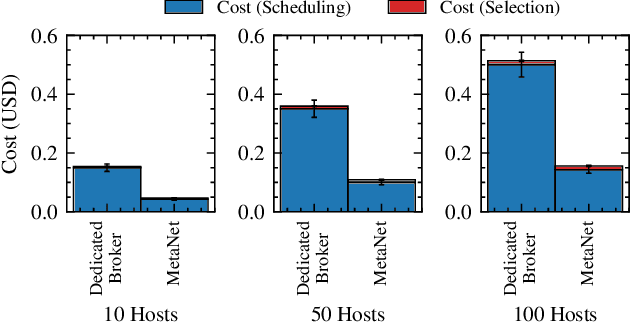
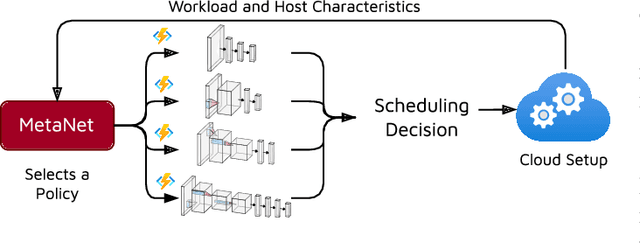
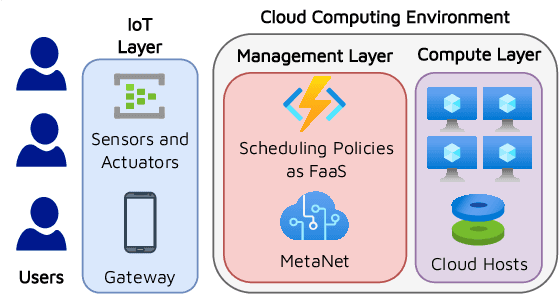
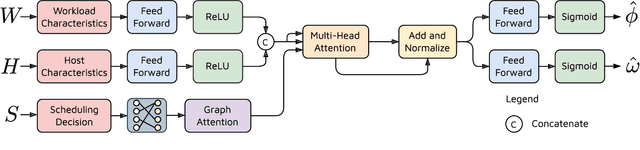
Task scheduling is a well-studied problem in the context of optimizing the Quality of Service (QoS) of cloud computing environments. In order to sustain the rapid growth of computational demands, one of the most important QoS metrics for cloud schedulers is the execution cost. In this regard, several data-driven deep neural networks (DNNs) based schedulers have been proposed in recent years to allow scalable and efficient resource management in dynamic workload settings. However, optimal scheduling frequently relies on sophisticated DNNs with high computational needs implying higher execution costs. Further, even in non-stationary environments, sophisticated schedulers might not always be required and we could briefly rely on low-cost schedulers in the interest of cost-efficiency. Therefore, this work aims to solve the non-trivial meta problem of online dynamic selection of a scheduling policy using a surrogate model called MetaNet. Unlike traditional solutions with a fixed scheduling policy, MetaNet on-the-fly chooses a scheduler from a large set of DNN based methods to optimize task scheduling and execution costs in tandem. Compared to state-of-the-art DNN schedulers, this allows for improvement in execution costs, energy consumption, response time and service level agreement violations by up to 11, 43, 8 and 13 percent, respectively.
SplitPlace: AI Augmented Splitting and Placement of Large-Scale Neural Networks in Mobile Edge Environments
May 21, 2022


In recent years, deep learning models have become ubiquitous in industry and academia alike. Deep neural networks can solve some of the most complex pattern-recognition problems today, but come with the price of massive compute and memory requirements. This makes the problem of deploying such large-scale neural networks challenging in resource-constrained mobile edge computing platforms, specifically in mission-critical domains like surveillance and healthcare. To solve this, a promising solution is to split resource-hungry neural networks into lightweight disjoint smaller components for pipelined distributed processing. At present, there are two main approaches to do this: semantic and layer-wise splitting. The former partitions a neural network into parallel disjoint models that produce a part of the result, whereas the latter partitions into sequential models that produce intermediate results. However, there is no intelligent algorithm that decides which splitting strategy to use and places such modular splits to edge nodes for optimal performance. To combat this, this work proposes a novel AI-driven online policy, SplitPlace, that uses Multi-Armed-Bandits to intelligently decide between layer and semantic splitting strategies based on the input task's service deadline demands. SplitPlace places such neural network split fragments on mobile edge devices using decision-aware reinforcement learning for efficient and scalable computing. Moreover, SplitPlace fine-tunes its placement engine to adapt to volatile environments. Our experiments on physical mobile-edge environments with real-world workloads show that SplitPlace can significantly improve the state-of-the-art in terms of average response time, deadline violation rate, inference accuracy, and total reward by up to 46, 69, 3 and 12 percent respectively.
CAROL: Confidence-Aware Resilience Model for Edge Federations
Mar 14, 2022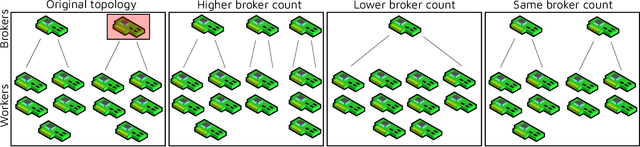


In recent years, the deployment of large-scale Internet of Things (IoT) applications has given rise to edge federations that seamlessly interconnect and leverage resources from multiple edge service providers. The requirement of supporting both latency-sensitive and compute-intensive IoT tasks necessitates service resilience, especially for the broker nodes in typical broker-worker deployment designs. Existing fault-tolerance or resilience schemes often lack robustness and generalization capability in non-stationary workload settings. This is typically due to the expensive periodic fine-tuning of models required to adapt them in dynamic scenarios. To address this, we present a confidence aware resilience model, CAROL, that utilizes a memory-efficient generative neural network to predict the Quality of Service (QoS) for a future state and a confidence score for each prediction. Thus, whenever a broker fails, we quickly recover the system by executing a local-search over the broker-worker topology space and optimize future QoS. The confidence score enables us to keep track of the prediction performance and run parsimonious neural network fine-tuning to avoid excessive overheads, further improving the QoS of the system. Experiments on a Raspberry-Pi based edge testbed with IoT benchmark applications show that CAROL outperforms state-of-the-art resilience schemes by reducing the energy consumption, deadline violation rates and resilience overheads by up to 16, 17 and 36 percent, respectively.
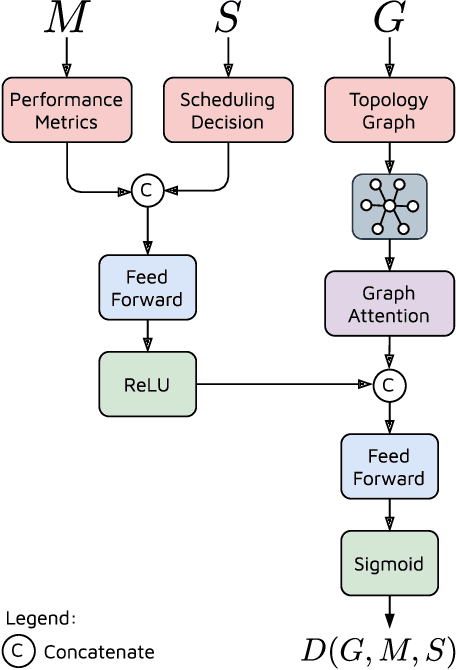
TranAD: Deep Transformer Networks for Anomaly Detection in Multivariate Time Series Data
Feb 08, 2022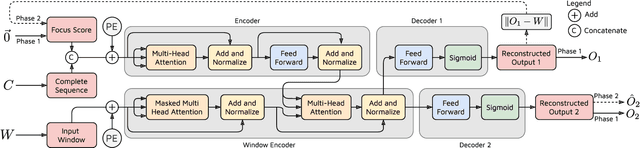

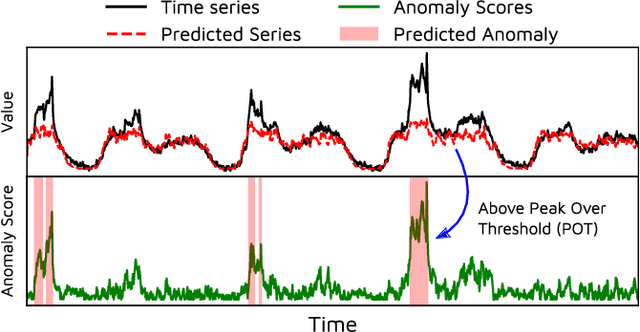
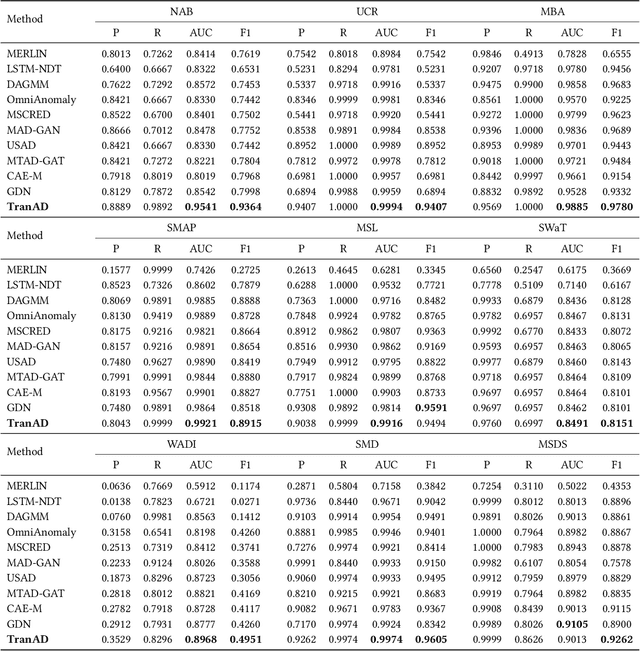
Efficient anomaly detection and diagnosis in multivariate time-series data is of great importance for modern industrial applications. However, building a system that is able to quickly and accurately pinpoint anomalous observations is a challenging problem. This is due to the lack of anomaly labels, high data volatility and the demands of ultra-low inference times in modern applications. Despite the recent developments of deep learning approaches for anomaly detection, only a few of them can address all of these challenges. In this paper, we propose TranAD, a deep transformer network based anomaly detection and diagnosis model which uses attention-based sequence encoders to swiftly perform inference with the knowledge of the broader temporal trends in the data. TranAD uses focus score-based self-conditioning to enable robust multi-modal feature extraction and adversarial training to gain stability. Additionally, model-agnostic meta learning (MAML) allows us to train the model using limited data. Extensive empirical studies on six publicly available datasets demonstrate that TranAD can outperform state-of-the-art baseline methods in detection and diagnosis performance with data and time-efficient training. Specifically, TranAD increases F1 scores by up to 17%, reducing training times by up to 99% compared to the baselines.
GOSH: Task Scheduling Using Deep Surrogate Models in Fog Computing Environments
Dec 16, 2021

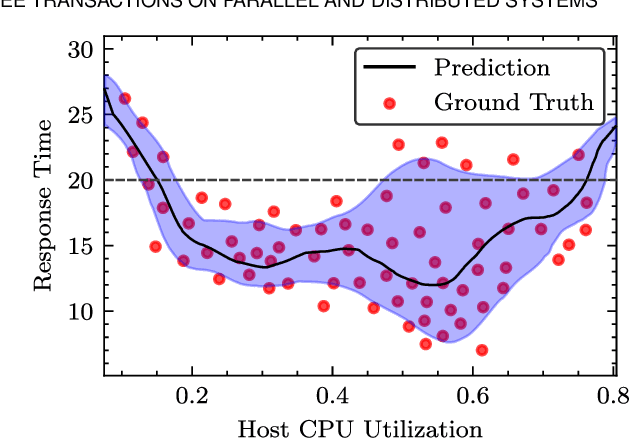

Recently, intelligent scheduling approaches using surrogate models have been proposed to efficiently allocate volatile tasks in heterogeneous fog environments. Advances like deterministic surrogate models, deep neural networks (DNN) and gradient-based optimization allow low energy consumption and response times to be reached. However, deterministic surrogate models, which estimate objective values for optimization, do not consider the uncertainties in the distribution of the Quality of Service (QoS) objective function that can lead to high Service Level Agreement (SLA) violation rates. Moreover, the brittle nature of DNN training and prevent such models from reaching minimal energy or response times. To overcome these difficulties, we present a novel scheduler: GOSH i.e. Gradient Based Optimization using Second Order derivatives and Heteroscedastic Deep Surrogate Models. GOSH uses a second-order gradient based optimization approach to obtain better QoS and reduce the number of iterations to converge to a scheduling decision, subsequently lowering the scheduling time. Instead of a vanilla DNN, GOSH uses a Natural Parameter Network to approximate objective scores. Further, a Lower Confidence Bound optimization approach allows GOSH to find an optimal trade-off between greedy minimization of the mean latency and uncertainty reduction by employing error-based exploration. Thus, GOSH and its co-simulation based extension GOSH*, can adapt quickly and reach better objective scores than baseline methods. We show that GOSH* reaches better objective scores than GOSH, but it is suitable only for high resource availability settings, whereas GOSH is apt for limited resource settings. Real system experiments for both GOSH and GOSH* show significant improvements against the state-of-the-art in terms of energy consumption, response time and SLA violations by up to 18, 27 and 82 percent, respectively.
MCDS: AI Augmented Workflow Scheduling in Mobile Edge Cloud Computing Systems
Dec 14, 2021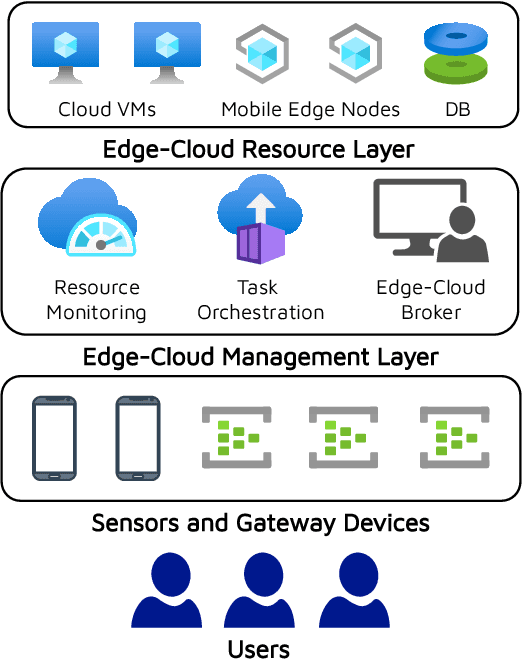


Workflow scheduling is a long-studied problem in parallel and distributed computing (PDC), aiming to efficiently utilize compute resources to meet user's service requirements. Recently proposed scheduling methods leverage the low response times of edge computing platforms to optimize application Quality of Service (QoS). However, scheduling workflow applications in mobile edge-cloud systems is challenging due to computational heterogeneity, changing latencies of mobile devices and the volatile nature of workload resource requirements. To overcome these difficulties, it is essential, but at the same time challenging, to develop a long-sighted optimization scheme that efficiently models the QoS objectives. In this work, we propose MCDS: Monte Carlo Learning using Deep Surrogate Models to efficiently schedule workflow applications in mobile edge-cloud computing systems. MCDS is an Artificial Intelligence (AI) based scheduling approach that uses a tree-based search strategy and a deep neural network-based surrogate model to estimate the long-term QoS impact of immediate actions for robust optimization of scheduling decisions. Experiments on physical and simulated edge-cloud testbeds show that MCDS can improve over the state-of-the-art methods in terms of energy consumption, response time, SLA violations and cost by at least 6.13, 4.56, 45.09 and 30.71 percent respectively.