 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Causal Representation Learning for Biological Data in the Pathway Space
Jun 14, 2025


Predicting the impact of genomic and drug perturbations in cellular function is crucial for understanding gene functions and drug effects, ultimately leading to improved therapies. To this end, Causal Representation Learning (CRL) constitutes one of the most promising approaches, as it aims to identify the latent factors that causally govern biological systems, thus facilitating the prediction of the effect of unseen perturbations. Yet, current CRL methods fail in reconciling their principled latent representations with known biological processes, leading to models that are not interpretable. To address this major issue, we present SENA-discrepancy-VAE, a model based on the recently proposed CRL method discrepancy-VAE, that produces representations where each latent factor can be interpreted as the (linear) combination of the activity of a (learned) set of biological processes. To this extent, we present an encoder, SENA-{\delta}, that efficiently compute and map biological processes' activity levels to the latent causal factors. We show that SENA-discrepancy-VAE achieves predictive performances on unseen combinations of interventions that are comparable with its original, non-interpretable counterpart, while inferring causal latent factors that are biologically meaningful.
Whispering LLaMA: A Cross-Modal Generative Error Correction Framework for Speech Recognition
Oct 16, 2023



We introduce a new cross-modal fusion technique designed for generative error correction in automatic speech recognition (ASR). Our methodology leverages both acoustic information and external linguistic representations to generate accurate speech transcription contexts. This marks a step towards a fresh paradigm in generative error correction within the realm of n-best hypotheses. Unlike the existing ranking-based rescoring methods, our approach adeptly uses distinct initialization techniques and parameter-efficient algorithms to boost ASR performance derived from pre-trained speech and text models. Through evaluation across diverse ASR datasets, we evaluate the stability and reproducibility of our fusion technique, demonstrating its improved word error rate relative (WERR) performance in comparison to n-best hypotheses by relatively 37.66%. To encourage future research, we have made our code and pre-trained models open source at https://github.com/Srijith-rkr/Whispering-LLaMA.
A Parameter-Efficient Learning Approach to Arabic Dialect Identification with Pre-Trained General-Purpose Speech Model
May 18, 2023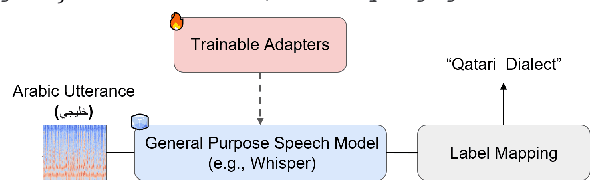
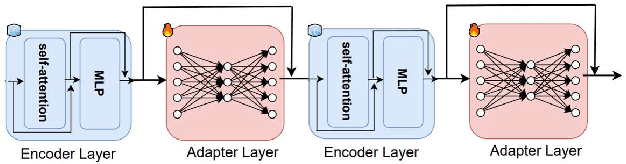
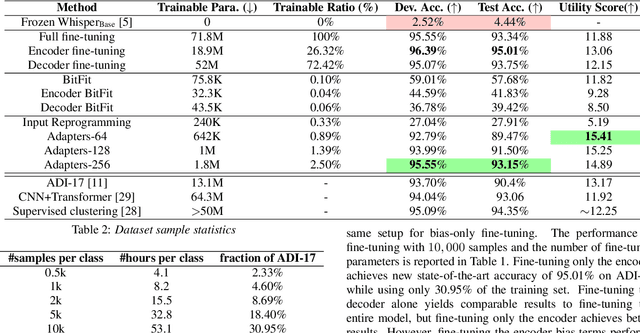
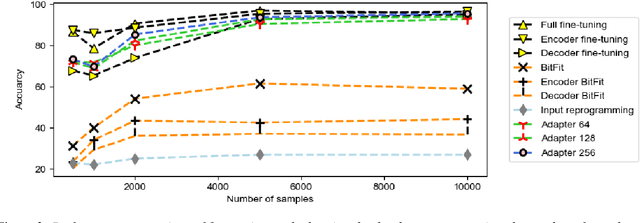
In this work, we explore Parameter-Efficient-Learning (PEL) techniques to repurpose a General-Purpose-Speech (GSM) model for Arabic dialect identification (ADI). Specifically, we investigate different setups to incorporate trainable features into a multi-layer encoder-decoder GSM formulation under frozen pre-trained settings. Our architecture includes residual adapter and model reprogramming (input-prompting). We design a token-level label mapping to condition the GSM for Arabic Dialect Identification (ADI). This is challenging due to the high variation in vocabulary and pronunciation among the numerous regional dialects. We achieve new state-of-the-art accuracy on the ADI-17 dataset by vanilla fine-tuning. We further reduce the training budgets with the PEL method, which performs within 1.86% accuracy to fine-tuning using only 2.5% of (extra) network trainable parameters. Our study demonstrates how to identify Arabic dialects using a small dataset and limited computation with open source code and pre-trained models.
Controllability, Multiplexing, and Transfer Learning in Networks using Evolutionary Learning
Nov 14, 2018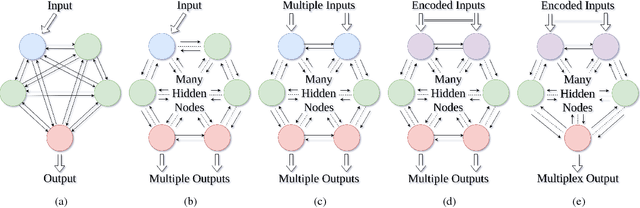
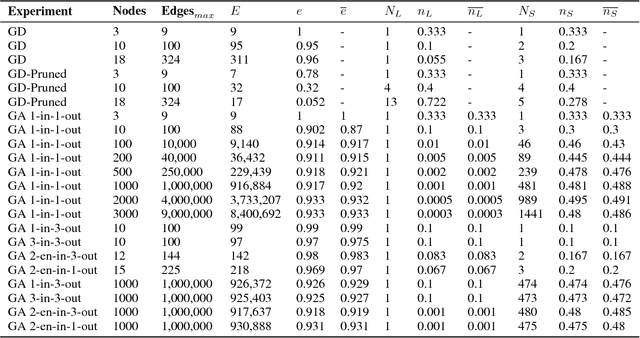
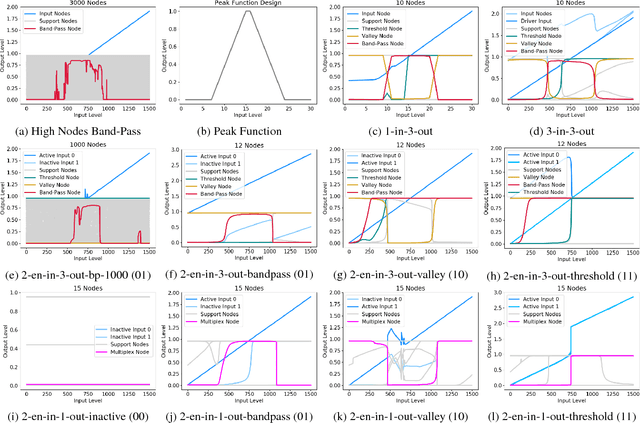
Networks are fundamental building blocks for representing data, and computations. Remarkable progress in learning in structurally defined (shallow or deep) networks has recently been achieved. Here we introduce evolutionary exploratory search and learning method of topologically flexible networks under the constraint of producing elementary computational steady-state input-output operations. Our results include; (1) the identification of networks, over four orders of magnitude, implementing computation of steady-state input-output functions, such as a band-pass filter, a threshold function, and an inverse band-pass function. Next, (2) the learned networks are technically controllable as only a small number of driver nodes are required to move the system to a new state. Furthermore, we find that the fraction of required driver nodes is constant during evolutionary learning, suggesting a stable system design. (3), our framework allows multiplexing of different computations using the same network. For example, using a binary representation of the inputs, the network can readily compute three different input-output functions. Finally, (4) the proposed evolutionary learning demonstrates transfer learning. If the system learns one function A, then learning B requires on average less number of steps as compared to learning B from tabula rasa. We conclude that the constrained evolutionary learning produces large robust controllable circuits, capable of multiplexing and transfer learning. Our study suggests that network-based computations of steady-state functions, representing either cellular modules of cell-to-cell communication networks or internal molecular circuits communicating within a cell, could be a powerful model for biologically inspired computing. This complements conceptualizations such as attractor based models, or reservoir computing.