 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhispering LLaMA: A Cross-Modal Generative Error Correction Framework for Speech Recognition
Oct 16, 2023We introduce a new cross-modal fusion technique designed for generative error correction in automatic speech recognition (ASR). Our methodology leverages both acoustic information and external linguistic representations to generate accurate speech transcription contexts. This marks a step towards a fresh paradigm in generative error correction within the realm of n-best hypotheses. Unlike the existing ranking-based rescoring methods, our approach adeptly uses distinct initialization techniques and parameter-efficient algorithms to boost ASR performance derived from pre-trained speech and text models. Through evaluation across diverse ASR datasets, we evaluate the stability and reproducibility of our fusion technique, demonstrating its improved word error rate relative (WERR) performance in comparison to n-best hypotheses by relatively 37.66%. To encourage future research, we have made our code and pre-trained models open source at https://github.com/Srijith-rkr/Whispering-LLaMA.
A Parameter-Efficient Learning Approach to Arabic Dialect Identification with Pre-Trained General-Purpose Speech Model
May 18, 2023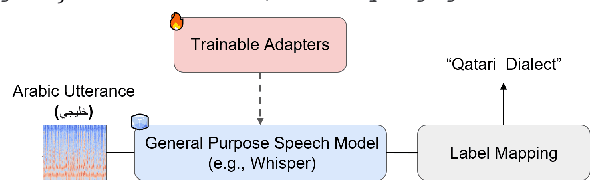
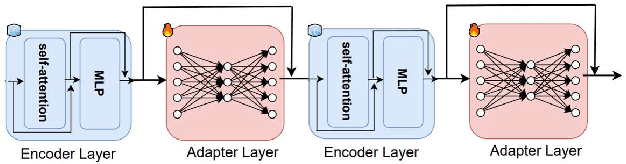
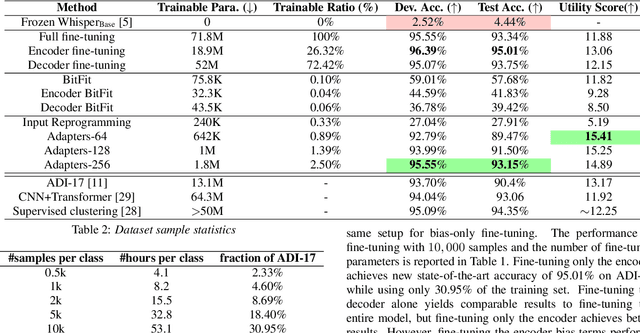
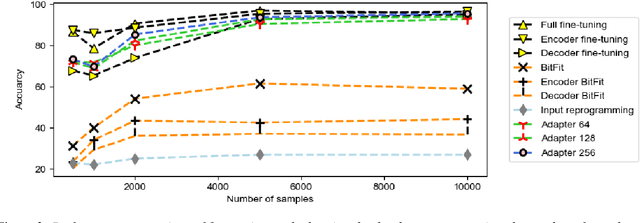
In this work, we explore Parameter-Efficient-Learning (PEL) techniques to repurpose a General-Purpose-Speech (GSM) model for Arabic dialect identification (ADI). Specifically, we investigate different setups to incorporate trainable features into a multi-layer encoder-decoder GSM formulation under frozen pre-trained settings. Our architecture includes residual adapter and model reprogramming (input-prompting). We design a token-level label mapping to condition the GSM for Arabic Dialect Identification (ADI). This is challenging due to the high variation in vocabulary and pronunciation among the numerous regional dialects. We achieve new state-of-the-art accuracy on the ADI-17 dataset by vanilla fine-tuning. We further reduce the training budgets with the PEL method, which performs within 1.86% accuracy to fine-tuning using only 2.5% of (extra) network trainable parameters. Our study demonstrates how to identify Arabic dialects using a small dataset and limited computation with open source code and pre-trained models.
Evolving Neural Networks through a Reverse Encoding Tree
Feb 03, 2020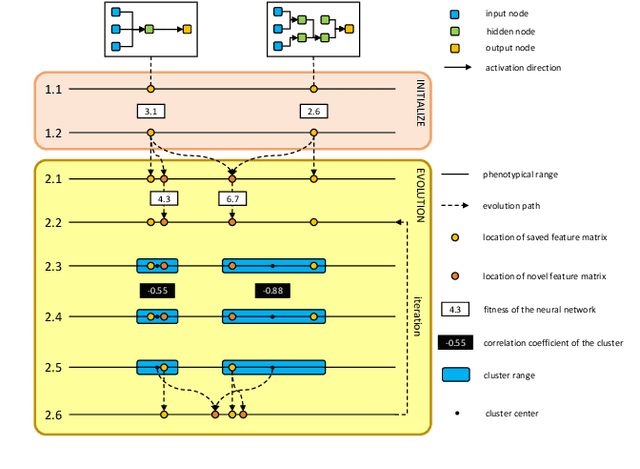
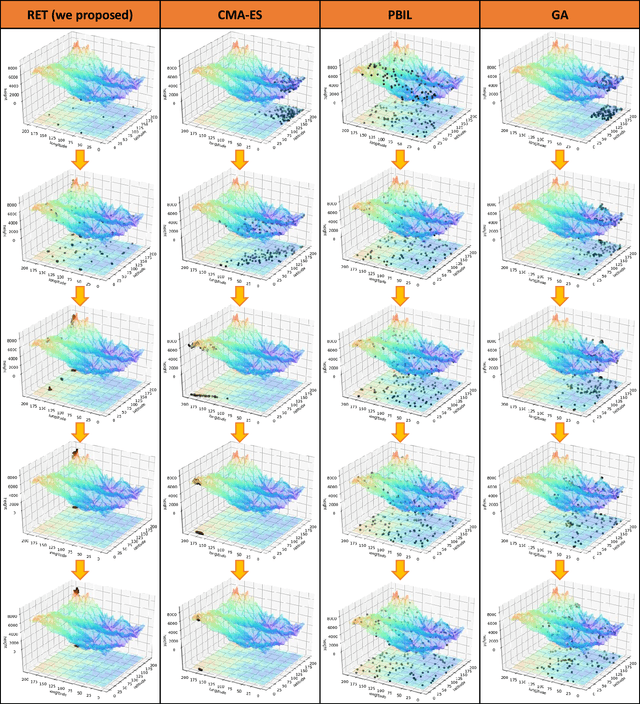
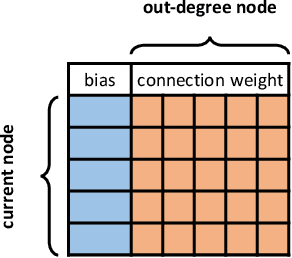
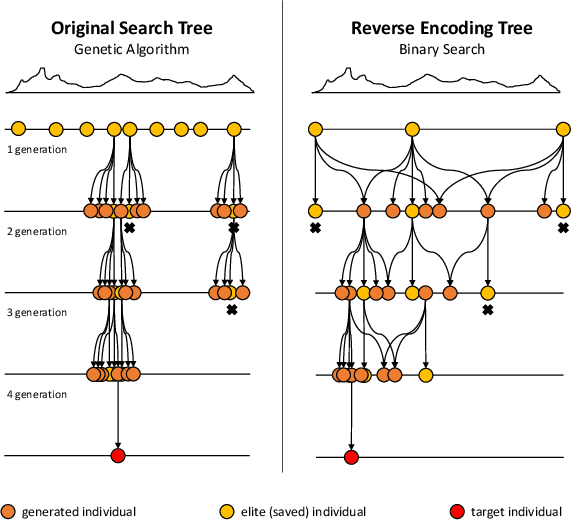
NeuroEvolution is one of the most competitive evolutionary learning frameworks for designing novel neural networks for use in specific tasks, such as logic circuit design and digital gaming. However, the application of benchmark methods such as the NeuroEvolution of Augmenting Topologies (NEAT) remains a challenge, in terms of their computational cost and search time inefficiency. This paper advances a method which incorporates a type of topological edge coding, named Reverse Encoding Tree (RET), for evolving scalable neural networks efficiently. Using RET, two types of approaches -- NEAT with Binary search encoding (Bi-NEAT) and NEAT with Golden-Section search encoding (GS-NEAT) -- have been designed to solve problems in benchmark continuous learning environments such as logic gates, Cartpole, and Lunar Lander, and tested against classical NEAT and FS-NEAT as baselines. Additionally, we conduct a robustness test to evaluate the resilience of the proposed NEAT algorithms. The results show that the two proposed strategies deliver an improved performance, characterized by (1) a higher accumulated reward within a finite number of time steps; (2) using fewer episodes to solve problems in targeted environments, and (3) maintaining adaptive robustness under noisy perturbations, which outperform the baselines in all tested cases. Our analysis also demonstrates that RET expends potential future research directions in dynamic environments. Code is available from https://github.com/HaolingZHANG/ReverseEncodingTree.
Algorithmic Probability-guided Supervised Machine Learning on Non-differentiable Spaces
Oct 08, 2019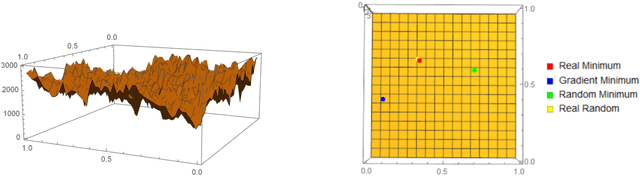

We show how complexity theory can be introduced in machine learning to help bring together apparently disparate areas of current research. We show that this new approach requires less training data and is more generalizable as it shows greater resilience to random attacks. We investigate the shape of the discrete algorithmic space when performing regression or classification using a loss function parametrized by algorithmic complexity, demonstrating that the property of differentiation is not necessary to achieve results similar to those obtained using differentiable programming approaches such as deep learning. In doing so we use examples which enable the two approaches to be compared (small, given the computational power required for estimations of algorithmic complexity). We find and report that (i) machine learning can successfully be performed on a non-smooth surface using algorithmic complexity; (ii) that parameter solutions can be found using an algorithmic-probability classifier, establishing a bridge between a fundamentally discrete theory of computability and a fundamentally continuous mathematical theory of optimization methods; (iii) a formulation of an algorithmically directed search technique in non-smooth manifolds can be defined and conducted; (iv) exploitation techniques and numerical methods for algorithmic search to navigate these discrete non-differentiable spaces can be performed; in application of the (a) identification of generative rules from data observations; (b) solutions to image classification problems more resilient against pixel attacks compared to neural networks; (c) identification of equation parameters from a small data-set in the presence of noise in continuous ODE system problem, (d) classification of Boolean NK networks by (1) network topology, (2) underlying Boolean function, and (3) number of incoming edges.
Algorithmic Causal Deconvolution of Intertwined Programs and Networks by Generative Mechanism
Sep 12, 2018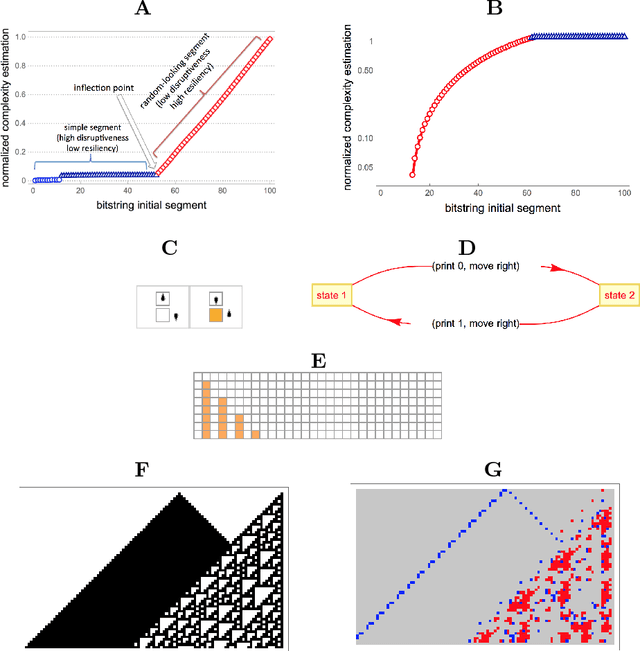
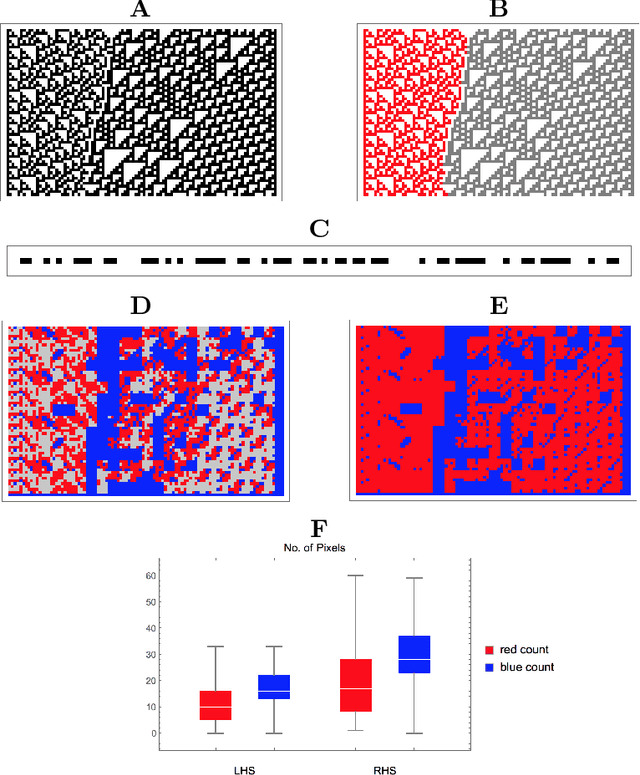
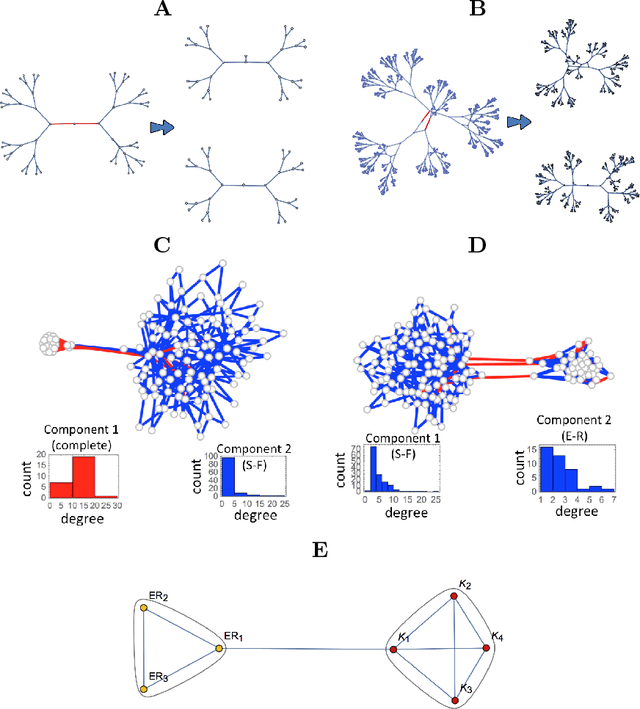
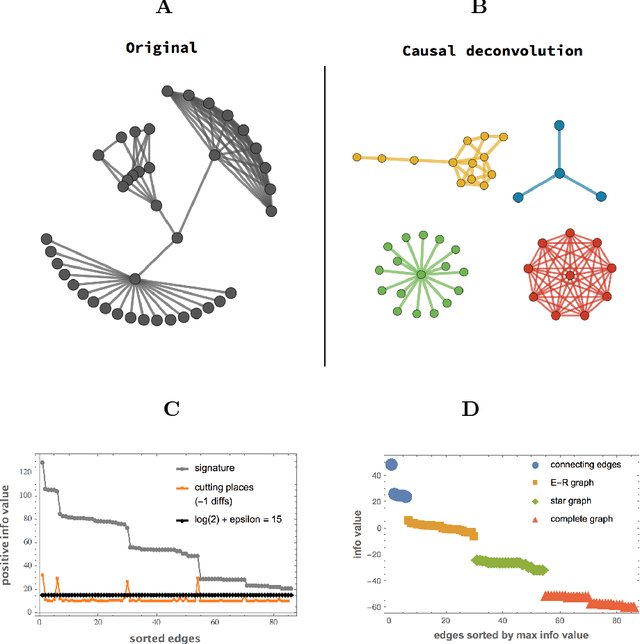
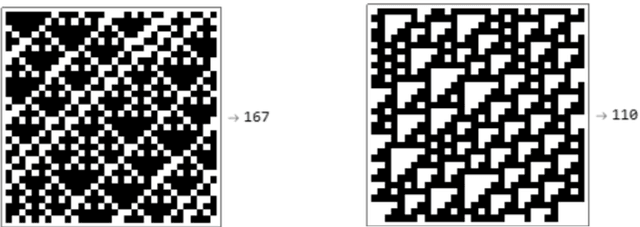
Complex data usually results from the interaction of objects produced by different generating mechanisms. Here we introduce a universal, unsupervised and parameter-free model-oriented approach, based upon the seminal concept of algorithmic probability, that decomposes an observation into its most likely algorithmic generative sources. Our approach uses a causal calculus to infer model representations. We demonstrate its ability to deconvolve interacting mechanisms regardless of whether the resultant objects are strings, space-time evolution diagrams, images or networks. While this is mostly a conceptual contribution and a novel framework, we provide numerical evidence evaluating the ability of our methods to separate data from observations produced by discrete dynamical systems such as cellular automata and complex networks. We think that these separating techniques can contribute to tackling the challenge of causation, thus complementing other statistically oriented approaches.