 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Parameter-Efficient Learning Approach to Arabic Dialect Identification with Pre-Trained General-Purpose Speech Model
Paper and Code
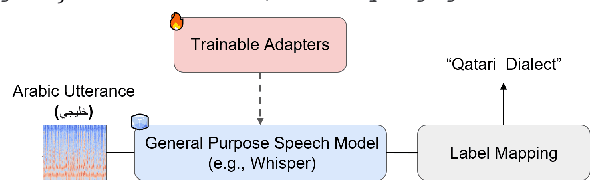
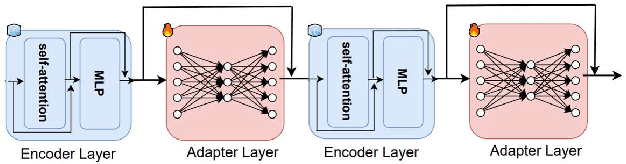
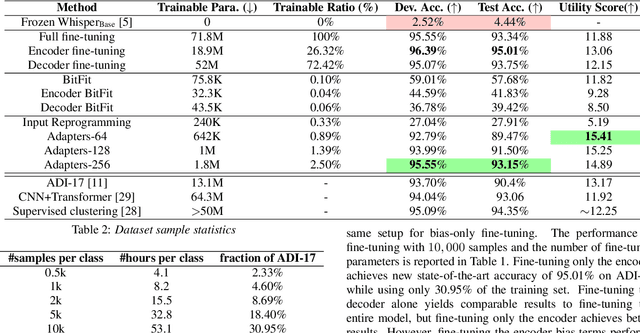
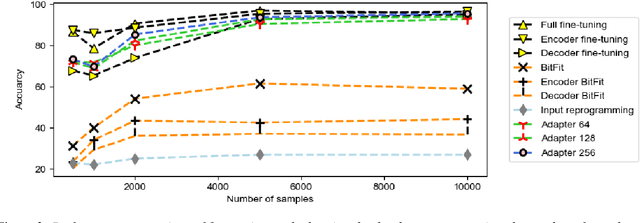
In this work, we explore Parameter-Efficient-Learning (PEL) techniques to repurpose a General-Purpose-Speech (GSM) model for Arabic dialect identification (ADI). Specifically, we investigate different setups to incorporate trainable features into a multi-layer encoder-decoder GSM formulation under frozen pre-trained settings. Our architecture includes residual adapter and model reprogramming (input-prompting). We design a token-level label mapping to condition the GSM for Arabic Dialect Identification (ADI). This is challenging due to the high variation in vocabulary and pronunciation among the numerous regional dialects. We achieve new state-of-the-art accuracy on the ADI-17 dataset by vanilla fine-tuning. We further reduce the training budgets with the PEL method, which performs within 1.86% accuracy to fine-tuning using only 2.5% of (extra) network trainable parameters. Our study demonstrates how to identify Arabic dialects using a small dataset and limited computation with open source code and pre-trained models.