 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUNITYAI-GUARD: Pioneering Toxicity Detection Across Low-Resource Indian Languages
Mar 29, 2025This work introduces UnityAI-Guard, a framework for binary toxicity classification targeting low-resource Indian languages. While existing systems predominantly cater to high-resource languages, UnityAI-Guard addresses this critical gap by developing state-of-the-art models for identifying toxic content across diverse Brahmic/Indic scripts. Our approach achieves an impressive average F1-score of 84.23% across seven languages, leveraging a dataset of 888k training instances and 35k manually verified test instances. By advancing multilingual content moderation for linguistically diverse regions, UnityAI-Guard also provides public API access to foster broader adoption and application.
Ensemble based approach to quantifying uncertainty of LLM based classifications
Feb 12, 2025The output of Large Language Models (LLMs) are a function of the internal model's parameters and the input provided into the context window. The hypothesis presented here is that under a greedy sampling strategy the variance in the LLM's output is a function of the conceptual certainty embedded in the model's parametric knowledge, as well as the lexical variance in the input. Finetuning the model results in reducing the sensitivity of the model output to the lexical input variations. This is then applied to a classification problem and a probabilistic method is proposed for estimating the certainties of the predicted classes.
Sitting, Standing and Walking Control of the Series-Parallel Hybrid Recupera-Reha Exoskeleton
Oct 08, 2024



This paper presents advancements in the functionalities of the Recupera-Reha lower extremity exoskeleton robot. The exoskeleton features a series-parallel hybrid design characterized by multiple kinematic loops resulting in 148 degrees of freedom in its spanning tree and 102 independent loop closure constraints, which poses significant challenges for modeling and control. To address these challenges, we applied an optimal control approach to generate feasible trajectories such as sitting, standing, and static walking, and tested these trajectories on the exoskeleton robot. Our method efficiently solves the optimal control problem using a serial abstraction of the model to generate trajectories. It then utilizes the full series-parallel hybrid model, which takes all the kinematic loop constraints into account to generate the final actuator commands. The experimental results demonstrate the effectiveness of our approach in generating the desired motions for the exoskeleton.
Sub-Resolution mmWave FMCW Radar-based Touch Localization using Deep Learning
Aug 07, 2024Touchscreen-based interaction on display devices are ubiquitous nowadays. However, capacitive touch screens, the core technology that enables its widespread use, are prohibitively expensive to be used in large displays because the cost increases proportionally with the screen area. In this paper, we propose a millimeter wave (mmWave) radar-based solution to achieve subresolution error performance using a network of four mmWave radar sensors. Unfortunately, achieving this is non-trivial due to inherent range resolution limitations of mmWave radars, since the target (human hand, finger etc.) is 'distributed' in space. We overcome this using a deep learning-based approach, wherein we train a deep convolutional neural network (CNN) on range-FFT (range vs power profile)-based features against ground truth (GT) positions obtained using a capacitive touch screen. To emulate the clutter characteristics encountered in radar-based positioning of human fingers, we use a metallic finger mounted on a metallic robot arm as the target. Using this setup, we demonstrate subresolution position error performance. Compared to conventional signal processing (CSP)-based approaches, we achieve a 2-3x reduction in positioning error using the CNN. Furthermore, we observe that the inference time performance and CNN model size support real-time integration of our approach on general purpose processor-based computing platforms.
TACLE: Task and Class-aware Exemplar-free Semi-supervised Class Incremental Learning
Jul 10, 2024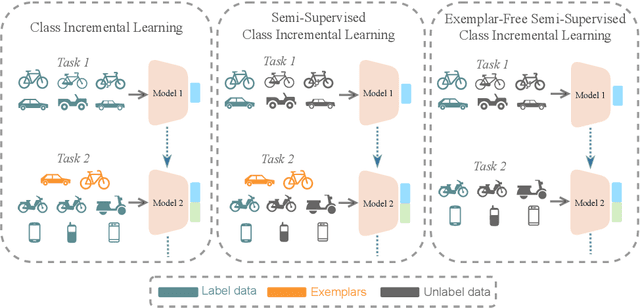
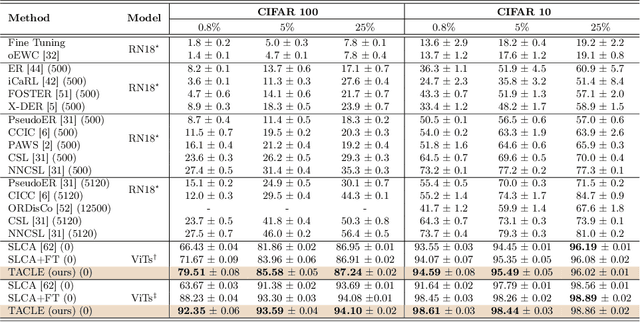
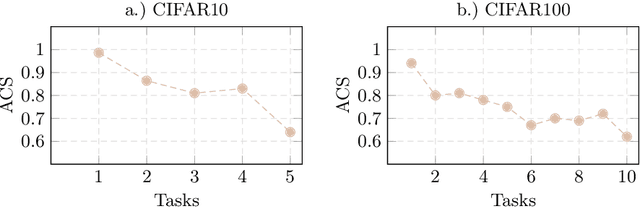
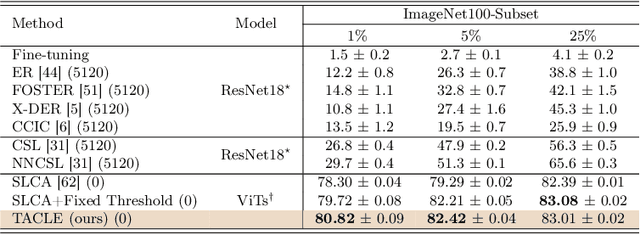
We propose a novel TACLE (TAsk and CLass-awarE) framework to address the relatively unexplored and challenging problem of exemplar-free semi-supervised class incremental learning. In this scenario, at each new task, the model has to learn new classes from both (few) labeled and unlabeled data without access to exemplars from previous classes. In addition to leveraging the capabilities of pre-trained models, TACLE proposes a novel task-adaptive threshold, thereby maximizing the utilization of the available unlabeled data as incremental learning progresses. Additionally, to enhance the performance of the under-represented classes within each task, we propose a class-aware weighted cross-entropy loss. We also exploit the unlabeled data for classifier alignment, which further enhances the model performance. Extensive experiments on benchmark datasets, namely CIFAR10, CIFAR100, and ImageNet-Subset100 demonstrate the effectiveness of the proposed TACLE framework. We further showcase its effectiveness when the unlabeled data is imbalanced and also for the extreme case of one labeled example per class.
Evaluating the Robustness of Off-Road Autonomous Driving Segmentation against Adversarial Attacks: A Dataset-Centric analysis
Feb 03, 2024This study investigates the vulnerability of semantic segmentation models to adversarial input perturbations, in the domain of off-road autonomous driving. Despite good performance in generic conditions, the state-of-the-art classifiers are often susceptible to (even) small perturbations, ultimately resulting in inaccurate predictions with high confidence. Prior research has directed their focus on making models more robust by modifying the architecture and training with noisy input images, but has not explored the influence of datasets in adversarial attacks. Our study aims to address this gap by examining the impact of non-robust features in off-road datasets and comparing the effects of adversarial attacks on different segmentation network architectures. To enable this, a robust dataset is created consisting of only robust features and training the networks on this robustified dataset. We present both qualitative and quantitative analysis of our findings, which have important implications on improving the robustness of machine learning models in off-road autonomous driving applications. Additionally, this work contributes to the safe navigation of autonomous robot Unimog U5023 in rough off-road unstructured environments by evaluating the robustness of segmentation outputs. The code is publicly available at https://github.com/rohtkumar/adversarial_attacks_ on_segmentation
Whispering LLaMA: A Cross-Modal Generative Error Correction Framework for Speech Recognition
Oct 16, 2023We introduce a new cross-modal fusion technique designed for generative error correction in automatic speech recognition (ASR). Our methodology leverages both acoustic information and external linguistic representations to generate accurate speech transcription contexts. This marks a step towards a fresh paradigm in generative error correction within the realm of n-best hypotheses. Unlike the existing ranking-based rescoring methods, our approach adeptly uses distinct initialization techniques and parameter-efficient algorithms to boost ASR performance derived from pre-trained speech and text models. Through evaluation across diverse ASR datasets, we evaluate the stability and reproducibility of our fusion technique, demonstrating its improved word error rate relative (WERR) performance in comparison to n-best hypotheses by relatively 37.66%. To encourage future research, we have made our code and pre-trained models open source at https://github.com/Srijith-rkr/Whispering-LLaMA.
Speech enhancement with frequency domain auto-regressive modeling
Sep 24, 2023Speech applications in far-field real world settings often deal with signals that are corrupted by reverberation. The task of dereverberation constitutes an important step to improve the audible quality and to reduce the error rates in applications like automatic speech recognition (ASR). We propose a unified framework of speech dereverberation for improving the speech quality and the ASR performance using the approach of envelope-carrier decomposition provided by an autoregressive (AR) model. The AR model is applied in the frequency domain of the sub-band speech signals to separate the envelope and carrier parts. A novel neural architecture based on dual path long short term memory (DPLSTM) model is proposed, which jointly enhances the sub-band envelope and carrier components. The dereverberated envelope-carrier signals are modulated and the sub-band signals are synthesized to reconstruct the audio signal back. The DPLSTM model for dereverberation of envelope and carrier components also allows the joint learning of the network weights for the down stream ASR task. In the ASR tasks on the REVERB challenge dataset as well as on the VOiCES dataset, we illustrate that the joint learning of speech dereverberation network and the E2E ASR model yields significant performance improvements over the baseline ASR system trained on log-mel spectrogram as well as other benchmarks for dereverberation (average relative improvements of 10-24% over the baseline system). The speech quality improvements, evaluated using subjective listening tests, further highlight the improved quality of the reconstructed audio.
* 10 pages
Multilingual Tourist Assistance using ChatGPT: Comparing Capabilities in Hindi, Telugu, and Kannada
Jul 28, 2023

This research investigates the effectiveness of ChatGPT, an AI language model by OpenAI, in translating English into Hindi, Telugu, and Kannada languages, aimed at assisting tourists in India's linguistically diverse environment. To measure the translation quality, a test set of 50 questions from diverse fields such as general knowledge, food, and travel was used. These were assessed by five volunteers for accuracy and fluency, and the scores were subsequently converted into a BLEU score. The BLEU score evaluates the closeness of a machine-generated translation to a human translation, with a higher score indicating better translation quality. The Hindi translations outperformed others, showcasing superior accuracy and fluency, whereas Telugu translations lagged behind. Human evaluators rated both the accuracy and fluency of translations, offering a comprehensive perspective on the language model's performance.
Local Relighting of Real Scenes
Jul 06, 2022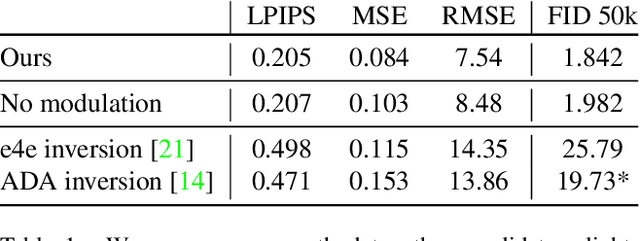

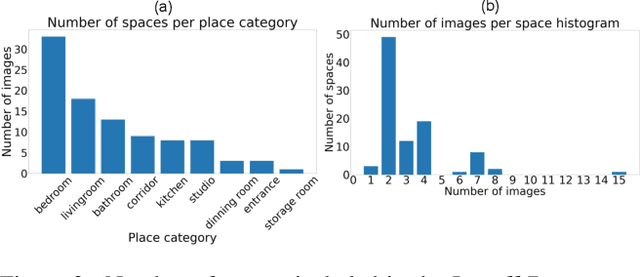
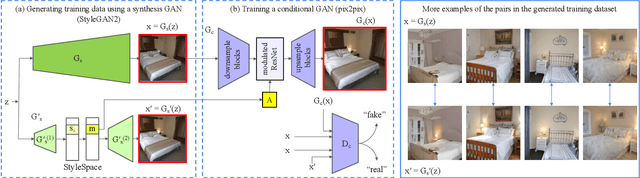
We introduce the task of local relighting, which changes a photograph of a scene by switching on and off the light sources that are visible within the image. This new task differs from the traditional image relighting problem, as it introduces the challenge of detecting light sources and inferring the pattern of light that emanates from them. We propose an approach for local relighting that trains a model without supervision of any novel image dataset by using synthetically generated image pairs from another model. Concretely, we collect paired training images from a stylespace-manipulated GAN; then we use these images to train a conditional image-to-image model. To benchmark local relighting, we introduce Lonoff, a collection of 306 precisely aligned images taken in indoor spaces with different combinations of lights switched on. We show that our method significantly outperforms baseline methods based on GAN inversion. Finally, we demonstrate extensions of our method that control different light sources separately. We invite the community to tackle this new task of local relighting.