 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Monolingual Assumptions: A Survey of Code-Switched NLP in the Era of Large Language Models
Oct 08, 2025



Code-switching (CSW), the alternation of languages and scripts within a single utterance, remains a fundamental challenge for multiling ual NLP, even amidst the rapid advances of large language models (LLMs). Most LLMs still struggle with mixed-language inputs, limited CSW datasets, and evaluation biases, hindering deployment in multilingual societies. This survey provides the first comprehensive analysis of CSW-aware LLM research, reviewing \total{unique_references} studies spanning five research areas, 12 NLP tasks, 30+ datasets, and 80+ languages. We classify recent advances by architecture, training strategy, and evaluation methodology, outlining how LLMs have reshaped CSW modeling and what challenges persist. The paper concludes with a roadmap emphasizing the need for inclusive datasets, fair evaluation, and linguistically grounded models to achieve truly multilingual intelligence. A curated collection of all resources is maintained at https://github.com/lingo-iitgn/awesome-code-mixing/.
Breaking mBad! Supervised Fine-tuning for Cross-Lingual Detoxification
May 22, 2025As large language models (LLMs) become increasingly prevalent in global applications, ensuring that they are toxicity-free across diverse linguistic contexts remains a critical challenge. We explore "Cross-lingual Detoxification", a cross-lingual paradigm that mitigates toxicity, enabling detoxification capabilities to transfer between high and low-resource languages across different script families. We analyze cross-lingual detoxification's effectiveness through 504 extensive settings to evaluate toxicity reduction in cross-distribution settings with limited data and investigate how mitigation impacts model performance on non-toxic tasks, revealing trade-offs between safety and knowledge preservation. Our code and dataset are publicly available at https://github.com/himanshubeniwal/Breaking-mBad.
PolyGuard: A Multilingual Safety Moderation Tool for 17 Languages
Apr 06, 2025Truly multilingual safety moderation efforts for Large Language Models (LLMs) have been hindered by a narrow focus on a small set of languages (e.g., English, Chinese) as well as a limited scope of safety definition, resulting in significant gaps in moderation capabilities. To bridge these gaps, we release POLYGUARD, a new state-of-the-art multilingual safety model for safeguarding LLM generations, and the corresponding training and evaluation datasets. POLYGUARD is trained on POLYGUARDMIX, the largest multilingual safety training corpus to date containing 1.91M samples across 17 languages (e.g., Chinese, Czech, English, Hindi). We also introduce POLYGUARDPROMPTS, a high quality multilingual benchmark with 29K samples for the evaluation of safety guardrails. Created by combining naturally occurring multilingual human-LLM interactions and human-verified machine translations of an English-only safety dataset (WildGuardMix; Han et al., 2024), our datasets contain prompt-output pairs with labels of prompt harmfulness, response harmfulness, and response refusal. Through extensive evaluations across multiple safety and toxicity benchmarks, we demonstrate that POLYGUARD outperforms existing state-of-the-art open-weight and commercial safety classifiers by 5.5%. Our contributions advance efforts toward safer multilingual LLMs for all global users.
UNITYAI-GUARD: Pioneering Toxicity Detection Across Low-Resource Indian Languages
Mar 29, 2025This work introduces UnityAI-Guard, a framework for binary toxicity classification targeting low-resource Indian languages. While existing systems predominantly cater to high-resource languages, UnityAI-Guard addresses this critical gap by developing state-of-the-art models for identifying toxic content across diverse Brahmic/Indic scripts. Our approach achieves an impressive average F1-score of 84.23% across seven languages, leveraging a dataset of 888k training instances and 35k manually verified test instances. By advancing multilingual content moderation for linguistically diverse regions, UnityAI-Guard also provides public API access to foster broader adoption and application.
COMI-LINGUA: Expert Annotated Large-Scale Dataset for Multitask NLP in Hindi-English Code-Mixing
Mar 27, 2025The rapid growth of digital communication has driven the widespread use of code-mixing, particularly Hindi-English, in multilingual communities. Existing datasets often focus on romanized text, have limited scope, or rely on synthetic data, which fails to capture realworld language nuances. Human annotations are crucial for assessing the naturalness and acceptability of code-mixed text. To address these challenges, We introduce COMI-LINGUA, the largest manually annotated dataset for code-mixed text, comprising 100,970 instances evaluated by three expert annotators in both Devanagari and Roman scripts. The dataset supports five fundamental NLP tasks: Language Identification, Matrix Language Identification, Part-of-Speech Tagging, Named Entity Recognition, and Translation. We evaluate LLMs on these tasks using COMILINGUA, revealing limitations in current multilingual modeling strategies and emphasizing the need for improved code-mixed text processing capabilities. COMI-LINGUA is publically availabe at: https://huggingface.co/datasets/LingoIITGN/COMI-LINGUA.
Char-mander Use mBackdoor! A Study of Cross-lingual Backdoor Attacks in Multilingual LLMs
Feb 24, 2025


We explore Cross-lingual Backdoor ATtacks (X-BAT) in multilingual Large Language Models (mLLMs), revealing how backdoors inserted in one language can automatically transfer to others through shared embedding spaces. Using toxicity classification as a case study, we demonstrate that attackers can compromise multilingual systems by poisoning data in a single language, with rare tokens serving as specific effective triggers. Our findings expose a critical vulnerability in the fundamental architecture that enables cross-lingual transfer in these models. Our code and data are publicly available at https://github.com/himanshubeniwal/X-BAT.
COMMENTATOR: A Code-mixed Multilingual Text Annotation Framework
Aug 06, 2024
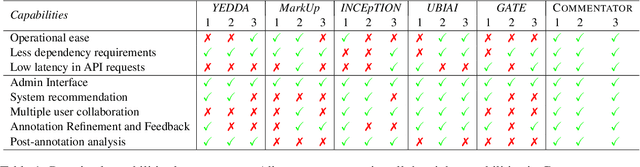


As the NLP community increasingly addresses challenges associated with multilingualism, robust annotation tools are essential to handle multilingual datasets efficiently. In this paper, we introduce a code-mixed multilingual text annotation framework, COMMENTATOR, specifically designed for annotating code-mixed text. The tool demonstrates its effectiveness in token-level and sentence-level language annotation tasks for Hinglish text. We perform robust qualitative human-based evaluations to showcase COMMENTATOR led to 5x faster annotations than the best baseline. Our code is publicly available at \url{https://github.com/lingo-iitgn/commentator}. The demonstration video is available at \url{https://bit.ly/commentator_video}.
Remember This Event That Year? Assessing Temporal Information and Reasoning in Large Language Models
Feb 19, 2024



Large Language Models (LLMs) are increasingly becoming ubiquitous, yet their ability to reason about and retain temporal information remains limited. This hinders their application in real-world scenarios where understanding the sequential nature of events is crucial. This paper experiments with state-of-the-art models on a novel, large-scale temporal dataset, \textbf{TempUN}, to reveal significant limitations in temporal retention and reasoning abilities. Interestingly, closed-source models indicate knowledge gaps more frequently, potentially suggesting a trade-off between uncertainty awareness and incorrect responses. Further, exploring various fine-tuning approaches yielded no major performance improvements. The associated dataset and code are available at the following URL (https://github.com/lingoiitgn/TempUN).
Cross-lingual Editing in Multilingual Language Models
Feb 03, 2024



The training of large language models (LLMs) necessitates substantial data and computational resources, and updating outdated LLMs entails significant efforts and resources. While numerous model editing techniques (METs) have emerged to efficiently update model outputs without retraining, their effectiveness in multilingual LLMs, where knowledge is stored in diverse languages, remains an underexplored research area. This research paper introduces the cross-lingual model editing (\textbf{XME}) paradigm, wherein a fact is edited in one language, and the subsequent update propagation is observed across other languages. To investigate the XME paradigm, we conducted experiments using BLOOM, mBERT, and XLM-RoBERTa using the two writing scripts: \textit{Latin} (English, French, and Spanish) and \textit{Indic} (Hindi, Gujarati, and Bengali). The results reveal notable performance limitations of state-of-the-art METs under the XME setting, mainly when the languages involved belong to two distinct script families. These findings highlight the need for further research and development of XME techniques to address these challenges. For more comprehensive information, the dataset used in this research and the associated code are publicly available at the following URL\url{https://github.com/lingo-iitgn/XME}.