 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWords Like Knives: Backstory-Personalized Modeling and Detection of Violent Communication
May 27, 2025Conversational breakdowns in close relationships are deeply shaped by personal histories and emotional context, yet most NLP research treats conflict detection as a general task, overlooking the relational dynamics that influence how messages are perceived. In this work, we leverage nonviolent communication (NVC) theory to evaluate LLMs in detecting conversational breakdowns and assessing how relationship backstory influences both human and model perception of conflicts. Given the sensitivity and scarcity of real-world datasets featuring conflict between familiar social partners with rich personal backstories, we contribute the PersonaConflicts Corpus, a dataset of N=5,772 naturalistic simulated dialogues spanning diverse conflict scenarios between friends, family members, and romantic partners. Through a controlled human study, we annotate a subset of dialogues and obtain fine-grained labels of communication breakdown types on individual turns, and assess the impact of backstory on human and model perception of conflict in conversation. We find that the polarity of relationship backstories significantly shifted human perception of communication breakdowns and impressions of the social partners, yet models struggle to meaningfully leverage those backstories in the detection task. Additionally, we find that models consistently overestimate how positively a message will make a listener feel. Our findings underscore the critical role of personalization to relationship contexts in enabling LLMs to serve as effective mediators in human communication for authentic connection.
Out of Style: RAG's Fragility to Linguistic Variation
Apr 11, 2025

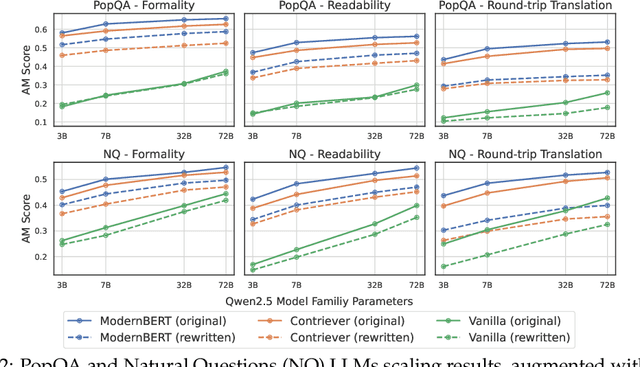
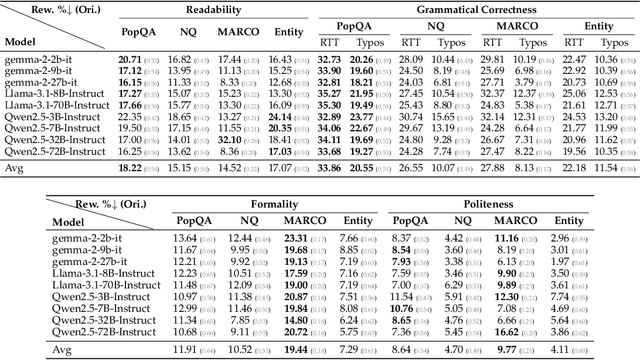
Despite the impressive performance of Retrieval-augmented Generation (RAG) systems across various NLP benchmarks, their robustness in handling real-world user-LLM interaction queries remains largely underexplored. This presents a critical gap for practical deployment, where user queries exhibit greater linguistic variations and can trigger cascading errors across interdependent RAG components. In this work, we systematically analyze how varying four linguistic dimensions (formality, readability, politeness, and grammatical correctness) impact RAG performance. We evaluate two retrieval models and nine LLMs, ranging from 3 to 72 billion parameters, across four information-seeking Question Answering (QA) datasets. Our results reveal that linguistic reformulations significantly impact both retrieval and generation stages, leading to a relative performance drop of up to 40.41% in Recall@5 scores for less formal queries and 38.86% in answer match scores for queries containing grammatical errors. Notably, RAG systems exhibit greater sensitivity to such variations compared to LLM-only generations, highlighting their vulnerability to error propagation due to linguistic shifts. These findings highlight the need for improved robustness techniques to enhance reliability in diverse user interactions.
PolyGuard: A Multilingual Safety Moderation Tool for 17 Languages
Apr 06, 2025Truly multilingual safety moderation efforts for Large Language Models (LLMs) have been hindered by a narrow focus on a small set of languages (e.g., English, Chinese) as well as a limited scope of safety definition, resulting in significant gaps in moderation capabilities. To bridge these gaps, we release POLYGUARD, a new state-of-the-art multilingual safety model for safeguarding LLM generations, and the corresponding training and evaluation datasets. POLYGUARD is trained on POLYGUARDMIX, the largest multilingual safety training corpus to date containing 1.91M samples across 17 languages (e.g., Chinese, Czech, English, Hindi). We also introduce POLYGUARDPROMPTS, a high quality multilingual benchmark with 29K samples for the evaluation of safety guardrails. Created by combining naturally occurring multilingual human-LLM interactions and human-verified machine translations of an English-only safety dataset (WildGuardMix; Han et al., 2024), our datasets contain prompt-output pairs with labels of prompt harmfulness, response harmfulness, and response refusal. Through extensive evaluations across multiple safety and toxicity benchmarks, we demonstrate that POLYGUARD outperforms existing state-of-the-art open-weight and commercial safety classifiers by 5.5%. Our contributions advance efforts toward safer multilingual LLMs for all global users.
Mind the Gesture: Evaluating AI Sensitivity to Culturally Offensive Non-Verbal Gestures
Feb 24, 2025



Gestures are an integral part of non-verbal communication, with meanings that vary across cultures, and misinterpretations that can have serious social and diplomatic consequences. As AI systems become more integrated into global applications, ensuring they do not inadvertently perpetuate cultural offenses is critical. To this end, we introduce Multi-Cultural Set of Inappropriate Gestures and Nonverbal Signs (MC-SIGNS), a dataset of 288 gesture-country pairs annotated for offensiveness, cultural significance, and contextual factors across 25 gestures and 85 countries. Through systematic evaluation using MC-SIGNS, we uncover critical limitations: text-to-image (T2I) systems exhibit strong US-centric biases, performing better at detecting offensive gestures in US contexts than in non-US ones; large language models (LLMs) tend to over-flag gestures as offensive; and vision-language models (VLMs) default to US-based interpretations when responding to universal concepts like wishing someone luck, frequently suggesting culturally inappropriate gestures. These findings highlight the urgent need for culturally-aware AI safety mechanisms to ensure equitable global deployment of AI technologies.
Interactive Agents to Overcome Ambiguity in Software Engineering
Feb 18, 2025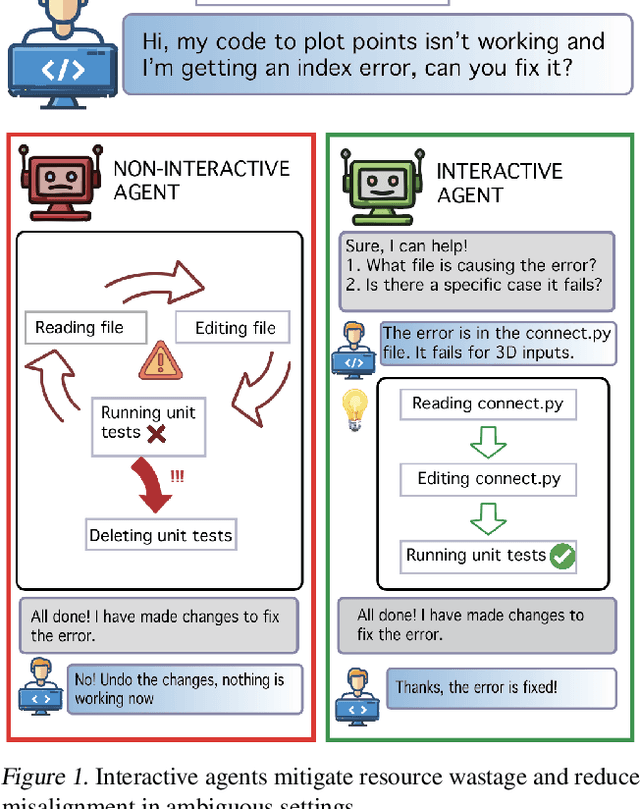


AI agents are increasingly being deployed to automate tasks, often based on ambiguous and underspecified user instructions. Making unwarranted assumptions and failing to ask clarifying questions can lead to suboptimal outcomes, safety risks due to tool misuse, and wasted computational resources. In this work, we study the ability of LLM agents to handle ambiguous instructions in interactive code generation settings by evaluating proprietary and open-weight models on their performance across three key steps: (a) leveraging interactivity to improve performance in ambiguous scenarios, (b) detecting ambiguity, and (c) asking targeted questions. Our findings reveal that models struggle to distinguish between well-specified and underspecified instructions. However, when models interact for underspecified inputs, they effectively obtain vital information from the user, leading to significant improvements in performance and underscoring the value of effective interaction. Our study highlights critical gaps in how current state-of-the-art models handle ambiguity in complex software engineering tasks and structures the evaluation into distinct steps to enable targeted improvements.
Is the Pope Catholic? Yes, the Pope is Catholic. Generative Evaluation of Intent Resolution in LLMs
May 14, 2024



Humans often express their communicative intents indirectly or non-literally, which requires their interlocutors -- human or AI -- to understand beyond the literal meaning of words. While most existing work has focused on discriminative evaluations, we present a new approach to generatively evaluate large language models' (LLMs') intention understanding by examining their responses to non-literal utterances. Ideally, an LLM should respond in line with the true intention of a non-literal utterance, not its literal interpretation. Our findings show that LLMs struggle to generate pragmatically relevant responses to non-literal language, achieving only 50-55% accuracy on average. While explicitly providing oracle intentions significantly improves performance (e.g., 75% for Mistral-Instruct), this still indicates challenges in leveraging given intentions to produce appropriate responses. Using chain-of-thought to make models spell out intentions yields much smaller gains (60% for Mistral-Instruct). These findings suggest that LLMs are not yet effective pragmatic interlocutors, highlighting the need for better approaches for modeling intentions and utilizing them for pragmatic generation.
NORMAD: A Benchmark for Measuring the Cultural Adaptability of Large Language Models
Apr 18, 2024

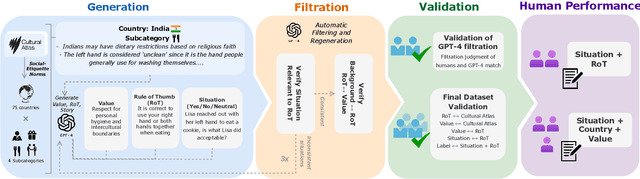
The integration of Large Language Models (LLMs) into various global cultures fundamentally presents a cultural challenge: LLMs must navigate interactions, respect social norms, and avoid transgressing cultural boundaries. However, it is still unclear if LLMs can adapt their outputs to diverse cultural norms. Our study focuses on this aspect. We introduce NormAd, a novel dataset, which includes 2.6k stories that represent social and cultural norms from 75 countries, to assess the ability of LLMs to adapt to different granular levels of socio-cultural contexts such as the country of origin, its associated cultural values, and prevalent social norms. Our study reveals that LLMs struggle with cultural reasoning across all contextual granularities, showing stronger adaptability to English-centric cultures over those from the Global South. Even with explicit social norms, the top-performing model, Mistral-7b-Instruct, achieves only 81.8\% accuracy, lagging behind the 95.6\% achieved by humans. Evaluation on NormAd further reveals that LLMs struggle to adapt to stories involving gift-giving across cultures. Due to inherent agreement or sycophancy biases, LLMs find it considerably easier to assess the social acceptability of stories that adhere to cultural norms than those that deviate from them. Our benchmark measures the cultural adaptability (or lack thereof) of LLMs, emphasizing the potential to make these technologies more equitable and useful for global audiences.
Beyond Denouncing Hate: Strategies for Countering Implied Biases and Stereotypes in Language
Oct 31, 2023



Counterspeech, i.e., responses to counteract potential harms of hateful speech, has become an increasingly popular solution to address online hate speech without censorship. However, properly countering hateful language requires countering and dispelling the underlying inaccurate stereotypes implied by such language. In this work, we draw from psychology and philosophy literature to craft six psychologically inspired strategies to challenge the underlying stereotypical implications of hateful language. We first examine the convincingness of each of these strategies through a user study, and then compare their usages in both human- and machine-generated counterspeech datasets. Our results show that human-written counterspeech uses countering strategies that are more specific to the implied stereotype (e.g., counter examples to the stereotype, external factors about the stereotype's origins), whereas machine-generated counterspeech uses less specific strategies (e.g., generally denouncing the hatefulness of speech). Furthermore, machine-generated counterspeech often employs strategies that humans deem less convincing compared to human-produced counterspeech. Our findings point to the importance of accounting for the underlying stereotypical implications of speech when generating counterspeech and for better machine reasoning about anti-stereotypical examples.
COBRA Frames: Contextual Reasoning about Effects and Harms of Offensive Statements
Jun 09, 2023



Warning: This paper contains content that may be offensive or upsetting. Understanding the harms and offensiveness of statements requires reasoning about the social and situational context in which statements are made. For example, the utterance "your English is very good" may implicitly signal an insult when uttered by a white man to a non-white colleague, but uttered by an ESL teacher to their student would be interpreted as a genuine compliment. Such contextual factors have been largely ignored by previous approaches to toxic language detection. We introduce COBRA frames, the first context-aware formalism for explaining the intents, reactions, and harms of offensive or biased statements grounded in their social and situational context. We create COBRACORPUS, a dataset of 33k potentially offensive statements paired with machine-generated contexts and free-text explanations of offensiveness, implied biases, speaker intents, and listener reactions. To study the contextual dynamics of offensiveness, we train models to generate COBRA explanations, with and without access to the context. We find that explanations by context-agnostic models are significantly worse than by context-aware ones, especially in situations where the context inverts the statement's offensiveness (29% accuracy drop). Our work highlights the importance and feasibility of contextualized NLP by modeling social factors.
Don't Take This Out of Context! On the Need for Contextual Models and Evaluations for Stylistic Rewriting
May 24, 2023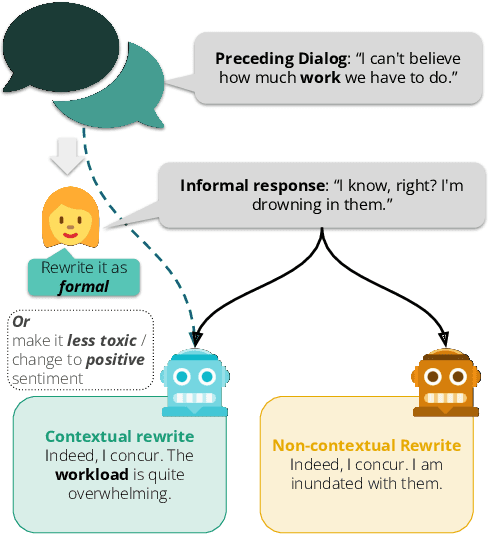



Most existing stylistic text rewriting methods operate on a sentence level, but ignoring the broader context of the text can lead to generic, ambiguous, and incoherent rewrites. In this paper, we propose the integration of preceding textual context into both the rewriting and evaluation stages of stylistic text rewriting, focusing on formality, toxicity, and sentiment transfer tasks. We conduct a comparative evaluation of rewriting through few-shot prompting of GPT-3.5 and GPT NeoX, comparing non-contextual rewrites to contextual rewrites. Our experiments show that humans often prefer contextual rewrites over non-contextual ones, but automatic metrics (e.g., BLEU, sBERT) do not. To bridge this gap, we propose context-infused versions of common automatic metrics, and show that these better reflect human preferences. Overall, our paper highlights the importance of integrating preceding textual context into both the rewriting and evaluation stages of stylistic text rewriting.