 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOBRA Frames: Contextual Reasoning about Effects and Harms of Offensive Statements
Jun 09, 2023



Warning: This paper contains content that may be offensive or upsetting. Understanding the harms and offensiveness of statements requires reasoning about the social and situational context in which statements are made. For example, the utterance "your English is very good" may implicitly signal an insult when uttered by a white man to a non-white colleague, but uttered by an ESL teacher to their student would be interpreted as a genuine compliment. Such contextual factors have been largely ignored by previous approaches to toxic language detection. We introduce COBRA frames, the first context-aware formalism for explaining the intents, reactions, and harms of offensive or biased statements grounded in their social and situational context. We create COBRACORPUS, a dataset of 33k potentially offensive statements paired with machine-generated contexts and free-text explanations of offensiveness, implied biases, speaker intents, and listener reactions. To study the contextual dynamics of offensiveness, we train models to generate COBRA explanations, with and without access to the context. We find that explanations by context-agnostic models are significantly worse than by context-aware ones, especially in situations where the context inverts the statement's offensiveness (29% accuracy drop). Our work highlights the importance and feasibility of contextualized NLP by modeling social factors.
Examining Racial Bias in an Online Abuse Corpus with Structural Topic Modeling
May 26, 2020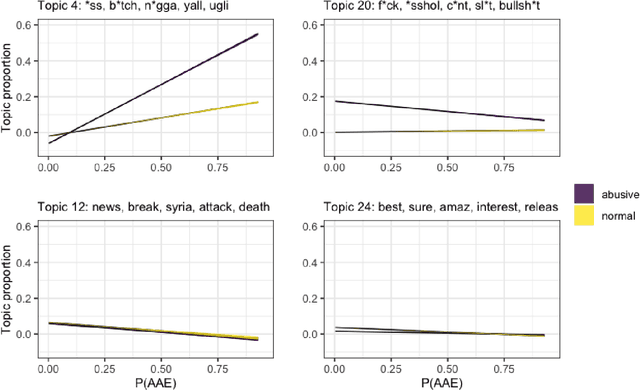
We use structural topic modeling to examine racial bias in data collected to train models to detect hate speech and abusive language in social media posts. We augment the abusive language dataset by adding an additional feature indicating the predicted probability of the tweet being written in African-American English. We then use structural topic modeling to examine the content of the tweets and how the prevalence of different topics is related to both abusiveness annotation and dialect prediction. We find that certain topics are disproportionately racialized and considered abusive. We discuss how topic modeling may be a useful approach for identifying bias in annotated data.
Racial Bias in Hate Speech and Abusive Language Detection Datasets
May 29, 2019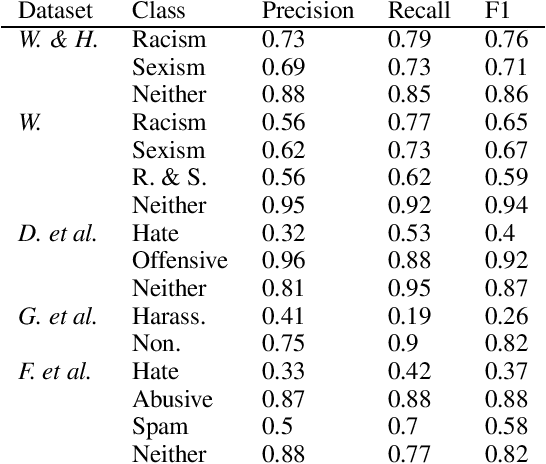
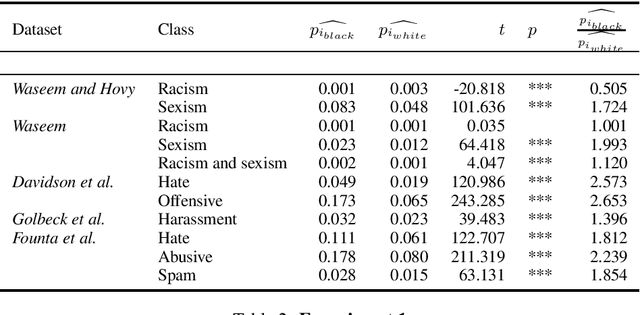
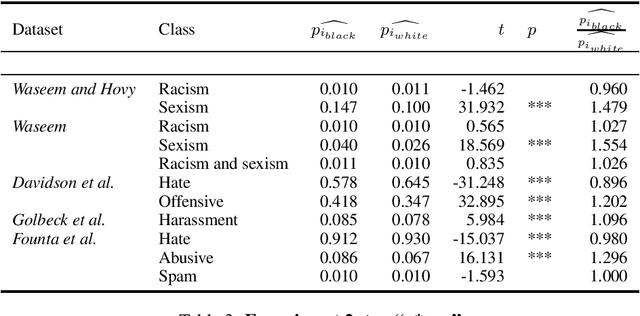
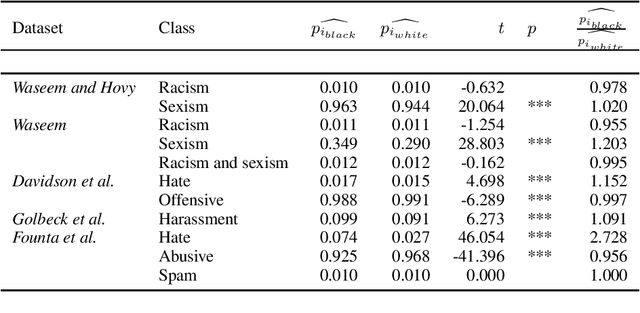
Technologies for abusive language detection are being developed and applied with little consideration of their potential biases. We examine racial bias in five different sets of Twitter data annotated for hate speech and abusive language. We train classifiers on these datasets and compare the predictions of these classifiers on tweets written in African-American English with those written in Standard American English. The results show evidence of systematic racial bias in all datasets, as classifiers trained on them tend to predict that tweets written in African-American English are abusive at substantially higher rates. If these abusive language detection systems are used in the field they will therefore have a disproportionate negative impact on African-American social media users. Consequently, these systems may discriminate against the groups who are often the targets of the abuse we are trying to detect.
Understanding Abuse: A Typology of Abusive Language Detection Subtasks
May 30, 2017
As the body of research on abusive language detection and analysis grows, there is a need for critical consideration of the relationships between different subtasks that have been grouped under this label. Based on work on hate speech, cyberbullying, and online abuse we propose a typology that captures central similarities and differences between subtasks and we discuss its implications for data annotation and feature construction. We emphasize the practical actions that can be taken by researchers to best approach their abusive language detection subtask of interest.
Automated Hate Speech Detection and the Problem of Offensive Language
Mar 11, 2017
A key challenge for automatic hate-speech detection on social media is the separation of hate speech from other instances of offensive language. Lexical detection methods tend to have low precision because they classify all messages containing particular terms as hate speech and previous work using supervised learning has failed to distinguish between the two categories. We used a crowd-sourced hate speech lexicon to collect tweets containing hate speech keywords. We use crowd-sourcing to label a sample of these tweets into three categories: those containing hate speech, only offensive language, and those with neither. We train a multi-class classifier to distinguish between these different categories. Close analysis of the predictions and the errors shows when we can reliably separate hate speech from other offensive language and when this differentiation is more difficult. We find that racist and homophobic tweets are more likely to be classified as hate speech but that sexist tweets are generally classified as offensive. Tweets without explicit hate keywords are also more difficult to classify.