Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExamining Racial Bias in an Online Abuse Corpus with Structural Topic Modeling
Paper and Code
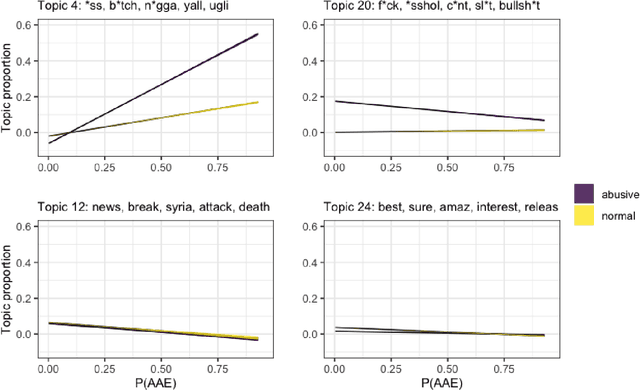
We use structural topic modeling to examine racial bias in data collected to train models to detect hate speech and abusive language in social media posts. We augment the abusive language dataset by adding an additional feature indicating the predicted probability of the tweet being written in African-American English. We then use structural topic modeling to examine the content of the tweets and how the prevalence of different topics is related to both abusiveness annotation and dialect prediction. We find that certain topics are disproportionately racialized and considered abusive. We discuss how topic modeling may be a useful approach for identifying bias in annotated data.
* Please cite the published version, see proceedings of ICWSM 2020
View paper on