 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Usage and Engagement in AI-Powered Scientific Research Tools: The Asta Interaction Dataset
Feb 26, 2026AI-powered scientific research tools are rapidly being integrated into research workflows, yet the field lacks a clear lens into how researchers use these systems in real-world settings. We present and analyze the Asta Interaction Dataset, a large-scale resource comprising over 200,000 user queries and interaction logs from two deployed tools (a literature discovery interface and a scientific question-answering interface) within an LLM-powered retrieval-augmented generation platform. Using this dataset, we characterize query patterns, engagement behaviors, and how usage evolves with experience. We find that users submit longer and more complex queries than in traditional search, and treat the system as a collaborative research partner, delegating tasks such as drafting content and identifying research gaps. Users treat generated responses as persistent artifacts, revisiting and navigating among outputs and cited evidence in non-linear ways. With experience, users issue more targeted queries and engage more deeply with supporting citations, although keyword-style queries persist even among experienced users. We release the anonymized dataset and analysis with a new query intent taxonomy to inform future designs of real-world AI research assistants and to support realistic evaluation.
Scale Can't Overcome Pragmatics: The Impact of Reporting Bias on Vision-Language Reasoning
Feb 26, 2026The lack of reasoning capabilities in Vision-Language Models (VLMs) has remained at the forefront of research discourse. We posit that this behavior stems from a reporting bias in their training data. That is, how people communicate about visual content by default omits tacit information needed to supervise some types of reasoning; e.g., "at the game today!" is a more likely caption than "a photo of 37 people standing behind a field". We investigate the data underlying the popular VLMs OpenCLIP, LLaVA-1.5 and Molmo through the lens of theories from pragmatics, and find that reporting bias results in insufficient representation of four reasoning skills (spatial, temporal, negation, and counting), despite the corpora being of web-scale, and/or synthetically generated. With a set of curated benchmarks, we demonstrate that: (i) VLMs perform poorly on the aforementioned types of reasoning suppressed in the training data by reporting bias; (ii) contrary to popular belief, scaling data size, model size, and to multiple languages does not result in emergence of these skills by default; but, promisingly, (iii) incorporating annotations specifically collected to obtain tacit information is effective. Our findings highlight the need for more intentional training data curation methods, rather than counting on scale for emergence of reasoning capabilities.
A Curious Class of Adpositional Multiword Expressions in Korean
Feb 17, 2026Multiword expressions (MWEs) have been widely studied in cross-lingual annotation frameworks such as PARSEME. However, Korean MWEs remain underrepresented in these efforts. In particular, Korean multiword adpositions lack systematic analysis, annotated resources, and integration into existing multilingual frameworks. In this paper, we study a class of Korean functional multiword expressions: postpositional verb-based constructions (PVCs). Using data from Korean Wikipedia, we survey and analyze several PVC expressions and contrast them with non-MWEs and light verb constructions (LVCs) with similar structure. Building on this analysis, we propose annotation guidelines designed to support future work in Korean multiword adpositions and facilitate alignment with cross-lingual frameworks.
AstaBench: Rigorous Benchmarking of AI Agents with a Scientific Research Suite
Oct 24, 2025AI agents hold the potential to revolutionize scientific productivity by automating literature reviews, replicating experiments, analyzing data, and even proposing new directions of inquiry; indeed, there are now many such agents, ranging from general-purpose "deep research" systems to specialized science-specific agents, such as AI Scientist and AIGS. Rigorous evaluation of these agents is critical for progress. Yet existing benchmarks fall short on several fronts: they (1) fail to provide holistic, product-informed measures of real-world use cases such as science research; (2) lack reproducible agent tools necessary for a controlled comparison of core agentic capabilities; (3) do not account for confounding variables such as model cost and tool access; (4) do not provide standardized interfaces for quick agent prototyping and evaluation; and (5) lack comprehensive baseline agents necessary to identify true advances. In response, we define principles and tooling for more rigorously benchmarking agents. Using these, we present AstaBench, a suite that provides the first holistic measure of agentic ability to perform scientific research, comprising 2400+ problems spanning the entire scientific discovery process and multiple scientific domains, and including many problems inspired by actual user requests to deployed Asta agents. Our suite comes with the first scientific research environment with production-grade search tools that enable controlled, reproducible evaluation, better accounting for confounders. Alongside, we provide a comprehensive suite of nine science-optimized classes of Asta agents and numerous baselines. Our extensive evaluation of 57 agents across 22 agent classes reveals several interesting findings, most importantly that despite meaningful progress on certain individual aspects, AI remains far from solving the challenge of science research assistance.
Intentionally Unintentional: GenAI Exceptionalism and the First Amendment
Jun 05, 2025This paper challenges the assumption that courts should grant First Amendment protections to outputs from large generative AI models, such as GPT-4 and Gemini. We argue that because these models lack intentionality, their outputs do not constitute speech as understood in the context of established legal precedent, so there can be no speech to protect. Furthermore, if the model outputs are not speech, users cannot claim a First Amendment speech right to receive the outputs. We also argue that extending First Amendment rights to AI models would not serve the fundamental purposes of free speech, such as promoting a marketplace of ideas, facilitating self-governance, or fostering self-expression. In fact, granting First Amendment protections to AI models would be detrimental to society because it would hinder the government's ability to regulate these powerful technologies effectively, potentially leading to the unchecked spread of misinformation and other harms.
DataDecide: How to Predict Best Pretraining Data with Small Experiments
Apr 15, 2025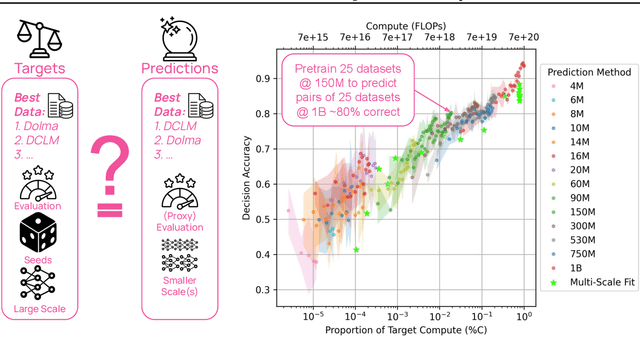
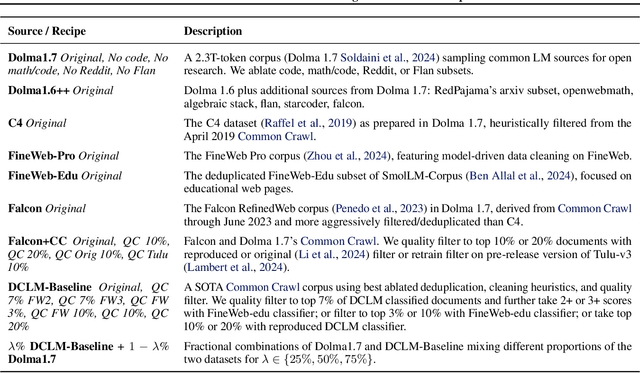
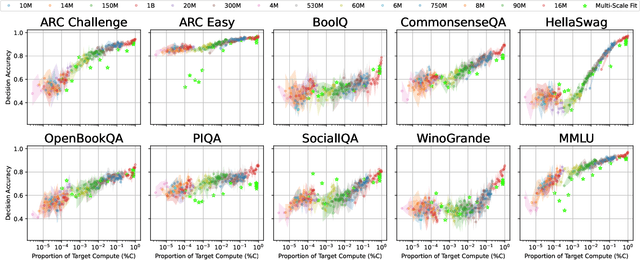
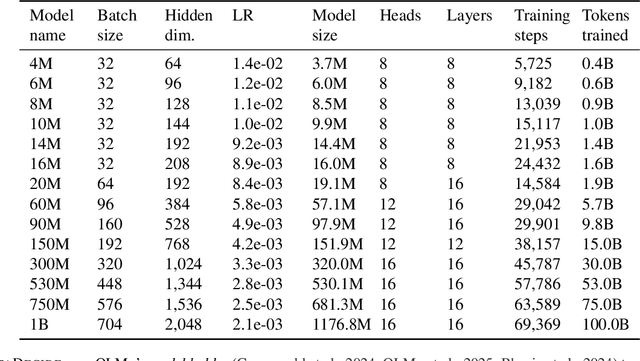
Because large language models are expensive to pretrain on different datasets, using smaller-scale experiments to decide on data is crucial for reducing costs. Which benchmarks and methods of making decisions from observed performance at small scale most accurately predict the datasets that yield the best large models? To empower open exploration of this question, we release models, data, and evaluations in DataDecide -- the most extensive open suite of models over differences in data and scale. We conduct controlled pretraining experiments across 25 corpora with differing sources, deduplication, and filtering up to 100B tokens, model sizes up to 1B parameters, and 3 random seeds. We find that the ranking of models at a single, small size (e.g., 150M parameters) is a strong baseline for predicting best models at our larger target scale (1B) (~80% of com parisons correct). No scaling law methods among 8 baselines exceed the compute-decision frontier of single-scale predictions, but DataDecide can measure improvement in future scaling laws. We also identify that using continuous likelihood metrics as proxies in small experiments makes benchmarks including MMLU, ARC, HellaSwag, MBPP, and HumanEval >80% predictable at the target 1B scale with just 0.01% of the compute.
Ai2 Scholar QA: Organized Literature Synthesis with Attribution
Apr 15, 2025Retrieval-augmented generation is increasingly effective in answering scientific questions from literature, but many state-of-the-art systems are expensive and closed-source. We introduce Ai2 Scholar QA, a free online scientific question answering application. To facilitate research, we make our entire pipeline public: as a customizable open-source Python package and interactive web app, along with paper indexes accessible through public APIs and downloadable datasets. We describe our system in detail and present experiments analyzing its key design decisions. In an evaluation on a recent scientific QA benchmark, we find that Ai2 Scholar QA outperforms competing systems.
TÜLU 3: Pushing Frontiers in Open Language Model Post-Training
Nov 22, 2024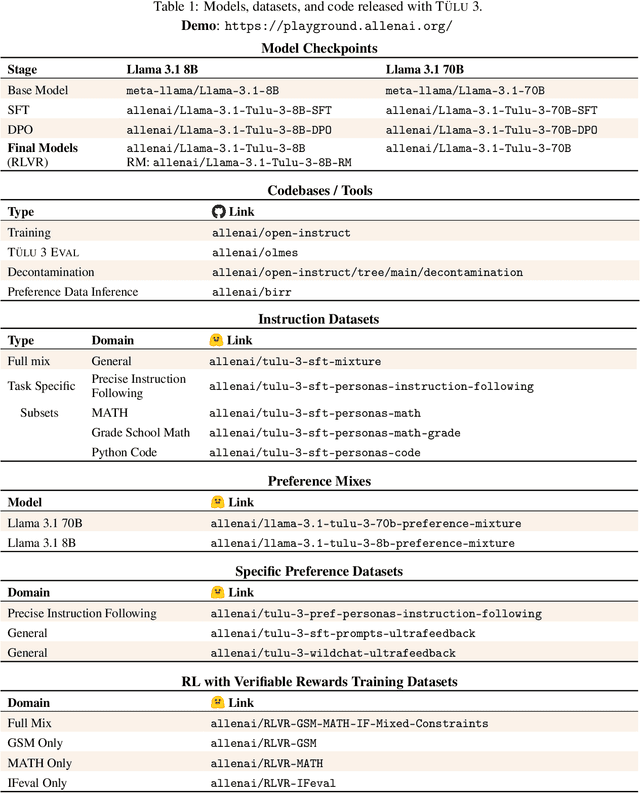



Language model post-training is applied to refine behaviors and unlock new skills across a wide range of recent language models, but open recipes for applying these techniques lag behind proprietary ones. The underlying training data and recipes for post-training are simultaneously the most important pieces of the puzzle and the portion with the least transparency. To bridge this gap, we introduce T\"ULU 3, a family of fully-open state-of-the-art post-trained models, alongside its data, code, and training recipes, serving as a comprehensive guide for modern post-training techniques. T\"ULU 3, which builds on Llama 3.1 base models, achieves results surpassing the instruct versions of Llama 3.1, Qwen 2.5, Mistral, and even closed models such as GPT-4o-mini and Claude 3.5-Haiku. The training algorithms for our models include supervised finetuning (SFT), Direct Preference Optimization (DPO), and a novel method we call Reinforcement Learning with Verifiable Rewards (RLVR). With T\"ULU 3, we introduce a multi-task evaluation scheme for post-training recipes with development and unseen evaluations, standard benchmark implementations, and substantial decontamination of existing open datasets on said benchmarks. We conclude with analysis and discussion of training methods that did not reliably improve performance. In addition to the T\"ULU 3 model weights and demo, we release the complete recipe -- including datasets for diverse core skills, a robust toolkit for data curation and evaluation, the training code and infrastructure, and, most importantly, a detailed report for reproducing and further adapting the T\"ULU 3 approach to more domains.
Diverging Preferences: When do Annotators Disagree and do Models Know?
Oct 18, 2024



We examine diverging preferences in human-labeled preference datasets. We develop a taxonomy of disagreement sources spanning 10 categories across four high-level classes -- task underspecification, response style, refusals, and annotation errors. We find that the majority of disagreements are in opposition with standard reward modeling approaches, which are designed with the assumption that annotator disagreement is noise. We then explore how these findings impact two areas of LLM development: reward modeling and evaluation. In our experiments, we demonstrate how standard reward modeling methods, like the Bradley-Terry model, fail to differentiate whether a given preference judgment is the result of unanimous agreement among annotators or the majority opinion among diverging user preferences. We also find that these tendencies are also echoed by popular LLM-as-Judge evaluation methods, which consistently identify a winning response in cases of diverging preferences. These findings highlight remaining challenges in LLM evaluations, which are greatly influenced by divisive features like response style, and in developing pluralistically aligned LLMs. To address these issues, we develop methods for identifying diverging preferences to mitigate their influence on evaluation and training.
Rel-A.I.: An Interaction-Centered Approach To Measuring Human-LM Reliance
Jul 10, 2024The reconfiguration of human-LM interactions from simple sentence completions to complex, multi-domain, humanlike engagements necessitates new methodologies to understand how humans choose to rely on LMs. In our work, we contend that reliance is influenced by numerous factors within the interactional context of a generation, a departure from prior work that used verbalized confidence (e.g., "I'm certain the answer is...") as the key determinant of reliance. Here, we introduce Rel-A.I., an in situ, system-level evaluation approach to measure human reliance on LM-generated epistemic markers (e.g., "I think it's..", "Undoubtedly it's..."). Using this methodology, we measure reliance rates in three emergent human-LM interaction settings: long-term interactions, anthropomorphic generations, and variable subject matter. Our findings reveal that reliance is not solely based on verbalized confidence but is significantly affected by other features of the interaction context. Prior interactions, anthropomorphic cues, and subject domain all contribute to reliance variability. An expression such as, "I'm pretty sure it's...", can vary up to 20% in reliance frequency depending on its interactional context. Our work underscores the importance of context in understanding human reliance and offers future designers and researchers with a methodology to conduct such measurements.