 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOlmo Hybrid: From Theory to Practice and Back
Apr 07, 2026Recent work has demonstrated the potential of non-transformer language models, especially linear recurrent neural networks (RNNs) and hybrid models that mix recurrence and attention. Yet there is no consensus on whether the potential benefits of these new architectures justify the risk and effort of scaling them up. To address this, we provide evidence for the advantages of hybrid models over pure transformers on several fronts. First, theoretically, we show that hybrid models do not merely inherit the expressivity of transformers and linear RNNs, but can express tasks beyond both, such as code execution. Putting this theory to practice, we train Olmo Hybrid, a 7B-parameter model largely comparable to Olmo 3 7B but with the sliding window layers replaced by Gated DeltaNet layers. We show that Olmo Hybrid outperforms Olmo 3 across standard pretraining and mid-training evaluations, demonstrating the benefit of hybrid models in a controlled, large-scale setting. We find that the hybrid model scales significantly more efficiently than the transformer, explaining its higher performance. However, its unclear why greater expressivity on specific formal problems should result in better scaling or superior performance on downstream tasks unrelated to those problems. To explain this apparent gap, we return to theory and argue why increased expressivity should translate to better scaling efficiency, completing the loop. Overall, our results suggest that hybrid models mixing attention and recurrent layers are a powerful extension to the language modeling paradigm: not merely to reduce memory during inference, but as a fundamental way to obtain more expressive models that scale better during pretraining.
Olmix: A Framework for Data Mixing Throughout LM Development
Feb 12, 2026Data mixing -- determining the ratios of data from different domains -- is a first-order concern for training language models (LMs). While existing mixing methods show promise, they fall short when applied during real-world LM development. We present Olmix, a framework that addresses two such challenges. First, the configuration space for developing a mixing method is not well understood -- design choices across existing methods lack justification or consensus and overlook practical issues like data constraints. We conduct a comprehensive empirical study of this space, identifying which design choices lead to a strong mixing method. Second, in practice, the domain set evolves throughout LM development as datasets are added, removed, partitioned, and revised -- a problem setting largely unaddressed by existing works, which assume fixed domains. We study how to efficiently recompute the mixture after the domain set is updated, leveraging information from past mixtures. We introduce mixture reuse, a mechanism that reuses existing ratios and recomputes ratios only for domains affected by the update. Over a sequence of five domain-set updates mirroring real-world LM development, mixture reuse matches the performance of fully recomputing the mix after each update with 74% less compute and improves over training without mixing by 11.6% on downstream tasks.
Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces
Jan 17, 2026AI agents may soon become capable of autonomously completing valuable, long-horizon tasks in diverse domains. Current benchmarks either do not measure real-world tasks, or are not sufficiently difficult to meaningfully measure frontier models. To this end, we present Terminal-Bench 2.0: a carefully curated hard benchmark composed of 89 tasks in computer terminal environments inspired by problems from real workflows. Each task features a unique environment, human-written solution, and comprehensive tests for verification. We show that frontier models and agents score less than 65\% on the benchmark and conduct an error analysis to identify areas for model and agent improvement. We publish the dataset and evaluation harness to assist developers and researchers in future work at https://www.tbench.ai/ .
Olmo 3
Dec 15, 2025We introduce Olmo 3, a family of state-of-the-art, fully-open language models at the 7B and 32B parameter scales. Olmo 3 model construction targets long-context reasoning, function calling, coding, instruction following, general chat, and knowledge recall. This release includes the entire model flow, i.e., the full lifecycle of the family of models, including every stage, checkpoint, data point, and dependency used to build it. Our flagship model, Olmo 3 Think 32B, is the strongest fully-open thinking model released to-date.
Signal and Noise: A Framework for Reducing Uncertainty in Language Model Evaluation
Aug 18, 2025Developing large language models is expensive and involves making decisions with small experiments, typically by evaluating on large, multi-task evaluation suites. In this work, we analyze specific properties which make a benchmark more reliable for such decisions, and interventions to design higher-quality evaluation benchmarks. We introduce two key metrics that show differences in current benchmarks: signal, a benchmark's ability to separate better models from worse models, and noise, a benchmark's sensitivity to random variability between training steps. We demonstrate that benchmarks with a better signal-to-noise ratio are more reliable when making decisions at small scale, and those with less noise have lower scaling law prediction error. These results suggest that improving signal or noise will lead to more useful benchmarks, so we introduce three interventions designed to directly affect signal or noise. For example, we propose that switching to a metric that has better signal and noise (e.g., perplexity rather than accuracy) leads to better reliability and improved scaling law error. We also find that filtering noisy subtasks, to improve an aggregate signal-to-noise ratio, leads to more reliable multi-task evaluations. We also find that averaging the output of a model's intermediate checkpoints to reduce noise leads to consistent improvements. We conclude by recommending that those creating new benchmarks, or selecting which existing benchmarks to use, aim for high signal and low noise. We use 30 benchmarks for these experiments, and 375 open-weight language models from 60M to 32B parameters, resulting in a new, publicly available dataset of 900K evaluation benchmark results, totaling 200M instances.
Evaluating LLMs on Chinese Idiom Translation
Aug 14, 2025Idioms, whose figurative meanings usually differ from their literal interpretations, are common in everyday language, especially in Chinese, where they often contain historical references and follow specific structural patterns. Despite recent progress in machine translation with large language models, little is known about Chinese idiom translation. In this work, we introduce IdiomEval, a framework with a comprehensive error taxonomy for Chinese idiom translation. We annotate 900 translation pairs from nine modern systems, including GPT-4o and Google Translate, across four domains: web, news, Wikipedia, and social media. We find these systems fail at idiom translation, producing incorrect, literal, partial, or even missing translations. The best-performing system, GPT-4, makes errors in 28% of cases. We also find that existing evaluation metrics measure idiom quality poorly with Pearson correlation below 0.48 with human ratings. We thus develop improved models that achieve F$_1$ scores of 0.68 for detecting idiom translation errors.
DataDecide: How to Predict Best Pretraining Data with Small Experiments
Apr 15, 2025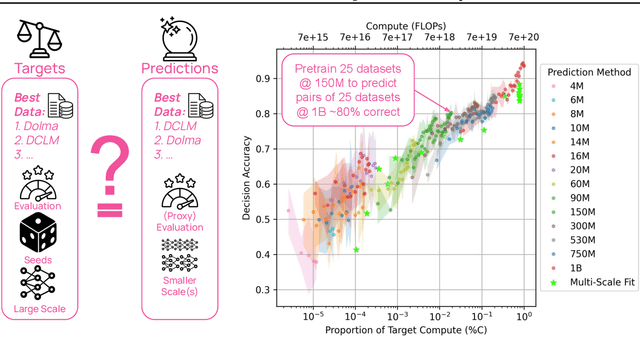
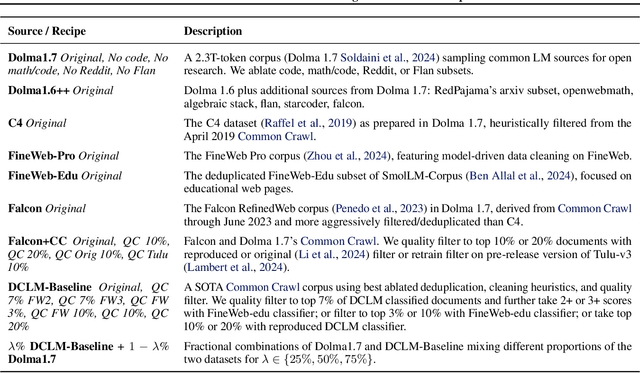
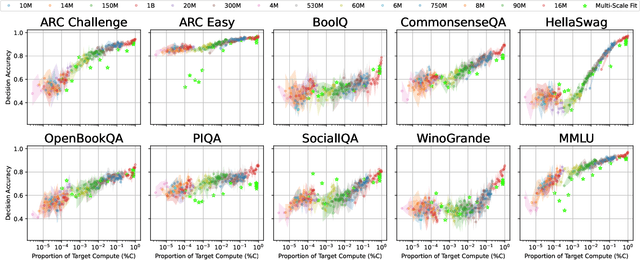
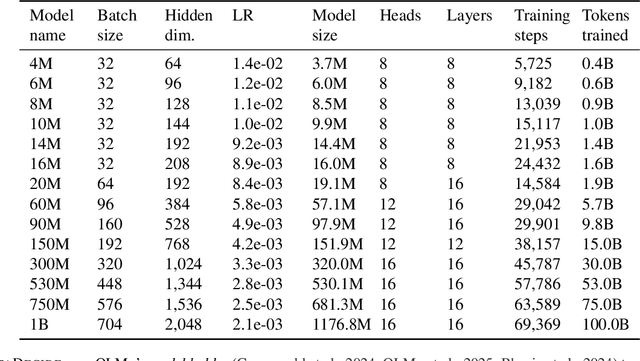
Because large language models are expensive to pretrain on different datasets, using smaller-scale experiments to decide on data is crucial for reducing costs. Which benchmarks and methods of making decisions from observed performance at small scale most accurately predict the datasets that yield the best large models? To empower open exploration of this question, we release models, data, and evaluations in DataDecide -- the most extensive open suite of models over differences in data and scale. We conduct controlled pretraining experiments across 25 corpora with differing sources, deduplication, and filtering up to 100B tokens, model sizes up to 1B parameters, and 3 random seeds. We find that the ranking of models at a single, small size (e.g., 150M parameters) is a strong baseline for predicting best models at our larger target scale (1B) (~80% of com parisons correct). No scaling law methods among 8 baselines exceed the compute-decision frontier of single-scale predictions, but DataDecide can measure improvement in future scaling laws. We also identify that using continuous likelihood metrics as proxies in small experiments makes benchmarks including MMLU, ARC, HellaSwag, MBPP, and HumanEval >80% predictable at the target 1B scale with just 0.01% of the compute.
Establishing Task Scaling Laws via Compute-Efficient Model Ladders
Dec 05, 2024We develop task scaling laws and model ladders to predict the individual task performance of pretrained language models (LMs) in the overtrained setting. Standard power laws for language modeling loss cannot accurately model task performance. Therefore, we leverage a two-step prediction approach: first use model and data size to predict a task-specific loss, and then use this task loss to predict task performance. We train a set of small-scale "ladder" models, collect data points to fit the parameterized functions of the two prediction steps, and make predictions for two target models: a 7B model trained to 4T tokens and a 13B model trained to 5T tokens. Training the ladder models only costs 1% of the compute used for the target models. On four multiple-choice tasks written in ranked classification format, we can predict the accuracy of both target models within 2 points of absolute error. We have higher prediction error on four other tasks (average absolute error 6.9) and find that these are often tasks with higher variance in task metrics. We also find that using less compute to train fewer ladder models tends to deteriorate predictions. Finally, we empirically show that our design choices and the two-step approach lead to superior performance in establishing scaling laws.
Improving Minimum Bayes Risk Decoding with Multi-Prompt
Jul 22, 2024



While instruction fine-tuned LLMs are effective text generators, sensitivity to prompt construction makes performance unstable and sub-optimal in practice. Relying on a single "best" prompt cannot capture all differing approaches to a generation problem. Using this observation, we propose multi-prompt decoding, where many candidate generations are decoded from a prompt bank at inference-time. To ensemble candidates, we use Minimum Bayes Risk (MBR) decoding, which selects a final output using a trained value metric. We show multi-prompt improves MBR across a comprehensive set of conditional generation tasks, and show this is a result of estimating a more diverse and higher quality candidate space than that of a single prompt. Further experiments confirm multi-prompt improves generation across tasks, models and metrics.
Towards a Path Dependent Account of Category Fluency
May 14, 2024Category fluency is a widely studied cognitive phenomenon, yet two conflicting accounts have been proposed as the underlying retrieval mechanism -- an optimal foraging process deliberately searching through memory (Hills et al., 2012) and a random walk sampling from a semantic network (Abbott et al., 2015). Evidence for both accounts has centered around predicting human patch switches, where both existing models of category fluency produce paradoxically identical results. We begin by peeling back the assumptions made by existing models, namely that each named example only depends on the previous example, by (i) adding an additional bias to model the category transition probability directly and (ii) relying on a large language model to predict based on the entire existing sequence. Then, we present evidence towards resolving the disagreement between each account of foraging by reformulating models as sequence generators. To evaluate, we compare generated category fluency runs to a bank of human-written sequences by proposing a metric based on n-gram overlap. We find category switch predictors do not necessarily produce human-like sequences, in fact the additional biases used by the Hills et al. (2012) model are required to improve generation quality, which are later improved by our category modification. Even generating exclusively with an LLM requires an additional global cue to trigger the patch switching behavior during production. Further tests on only the search process on top of the semantic network highlight the importance of deterministic search to replicate human behavior.