 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocalizing Prompt Ambiguity in Large Language Models with Probe-Targeted Attribution
Jun 03, 2026Prompt ambiguity is a common source of failure in large language models, but is difficult to localize because it is a latent property of the prompt, while existing attribution methods are designed to explain observable outputs such as logits or generated tokens. We introduce PRIG, a gradient attribution method that uses a probe logit to attribute latent ambiguity to token positions. Specifically, PRIG trains a linear probe to distinguish clear prompts from ambiguous prompts and attributes the probe score to earlier token representations in the residual stream. To enable token-level evaluation, we construct synthetic ambiguity datasets across coding, math, and writing by rewriting one task-critical sentence per prompt, and complement them with a human-written gold benchmark. In this setting, PRIG localizes ambiguous spans substantially better than gradient attribution baselines, achieving 0.840 AUROC on the combined synthetic benchmark and 0.891 AUROC on the gold set. It also outperforms GPT-5.4 on sentence-level ambiguity identification and retains useful signal out-of-domain. These results establish PRIG as a practical tool for identifying which parts of a prompt are ambiguous. More broadly, they suggest that latent prompt properties can be localized through intermediate representations, rather than through output-level attribution.
Gavel: Agent Meets Checklist for Evaluating LLMs on Long-Context Legal Summarization
Jan 07, 2026Large language models (LLMs) now support contexts of up to 1M tokens, but their effectiveness on complex long-context tasks remains unclear. In this paper, we study multi-document legal case summarization, where a single case often spans many documents totaling 100K-500K tokens. We introduce Gavel-Ref, a reference-based evaluation framework with multi-value checklist evaluation over 26 items, as well as residual fact and writing-style evaluations. Using Gavel-Ref, we go beyond the single aggregate scores reported in prior work and systematically evaluate 12 frontier LLMs on 100 legal cases ranging from 32K to 512K tokens, primarily from 2025. Our results show that even the strongest model, Gemini 2.5 Pro, achieves only around 50 of $S_{\text{Gavel-Ref}}$, highlighting the difficulty of the task. Models perform well on simple checklist items (e.g., filing date) but struggle on multi-value or rare ones such as settlements and monitor reports. As LLMs continue to improve and may surpass human-written summaries -- making human references less reliable -- we develop Gavel-Agent, an efficient and autonomous agent scaffold that equips LLMs with six tools to navigate and extract checklists directly from case documents. With Qwen3, Gavel-Agent reduces token usage by 36% while resulting in only a 7% drop in $S_{\text{checklist}}$ compared to end-to-end extraction with GPT-4.1.
Evaluating LLMs on Chinese Idiom Translation
Aug 14, 2025Idioms, whose figurative meanings usually differ from their literal interpretations, are common in everyday language, especially in Chinese, where they often contain historical references and follow specific structural patterns. Despite recent progress in machine translation with large language models, little is known about Chinese idiom translation. In this work, we introduce IdiomEval, a framework with a comprehensive error taxonomy for Chinese idiom translation. We annotate 900 translation pairs from nine modern systems, including GPT-4o and Google Translate, across four domains: web, news, Wikipedia, and social media. We find these systems fail at idiom translation, producing incorrect, literal, partial, or even missing translations. The best-performing system, GPT-4, makes errors in 28% of cases. We also find that existing evaluation metrics measure idiom quality poorly with Pearson correlation below 0.48 with human ratings. We thus develop improved models that achieve F$_1$ scores of 0.68 for detecting idiom translation errors.
Measuring, Modeling, and Helping People Account for Privacy Risks in Online Self-Disclosures with AI
Dec 19, 2024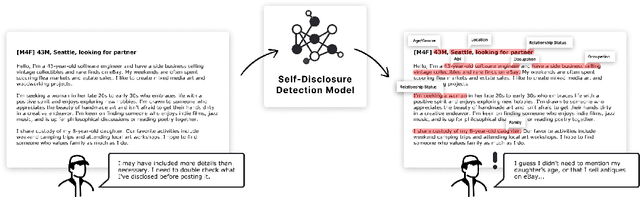
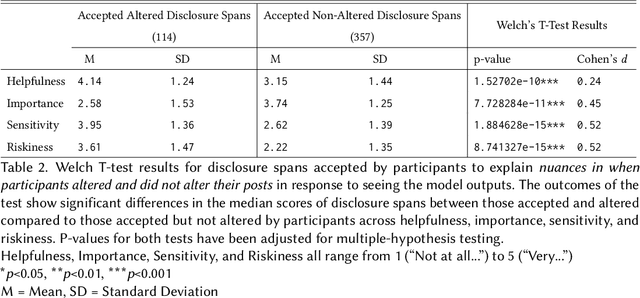
In pseudonymous online fora like Reddit, the benefits of self-disclosure are often apparent to users (e.g., I can vent about my in-laws to understanding strangers), but the privacy risks are more abstract (e.g., will my partner be able to tell that this is me?). Prior work has sought to develop natural language processing (NLP) tools that help users identify potentially risky self-disclosures in their text, but none have been designed for or evaluated with the users they hope to protect. Absent this assessment, these tools will be limited by the social-technical gap: users need assistive tools that help them make informed decisions, not paternalistic tools that tell them to avoid self-disclosure altogether. To bridge this gap, we conducted a study with N = 21 Reddit users; we had them use a state-of-the-art NLP disclosure detection model on two of their authored posts and asked them questions to understand if and how the model helped, where it fell short, and how it could be improved to help them make more informed decisions. Despite its imperfections, users responded positively to the model and highlighted its use as a tool that can help them catch mistakes, inform them of risks they were unaware of, and encourage self-reflection. However, our work also shows how, to be useful and usable, AI for supporting privacy decision-making must account for posting context, disclosure norms, and users' lived threat models, and provide explanations that help contextualize detected risks.
TemporalBench: Benchmarking Fine-grained Temporal Understanding for Multimodal Video Models
Oct 15, 2024



Understanding fine-grained temporal dynamics is crucial for multimodal video comprehension and generation. Due to the lack of fine-grained temporal annotations, existing video benchmarks mostly resemble static image benchmarks and are incompetent at evaluating models for temporal understanding. In this paper, we introduce TemporalBench, a new benchmark dedicated to evaluating fine-grained temporal understanding in videos. TemporalBench consists of ~10K video question-answer pairs, derived from ~2K high-quality human annotations detailing the temporal dynamics in video clips. As a result, our benchmark provides a unique testbed for evaluating various temporal understanding and reasoning abilities such as action frequency, motion magnitude, event order, etc. Moreover, it enables evaluations on various tasks like both video question answering and captioning, both short and long video understanding, as well as different models such as multimodal video embedding models and text generation models. Results show that state-of-the-art models like GPT-4o achieve only 38.5% question answering accuracy on TemporalBench, demonstrating a significant gap (~30%) between humans and AI in temporal understanding. Furthermore, we notice a critical pitfall for multi-choice QA where LLMs can detect the subtle changes in negative captions and find a centralized description as a cue for its prediction, where we propose Multiple Binary Accuracy (MBA) to correct such bias. We hope that TemporalBench can foster research on improving models' temporal reasoning capabilities. Both dataset and evaluation code will be made available.
Improving Minimum Bayes Risk Decoding with Multi-Prompt
Jul 22, 2024



While instruction fine-tuned LLMs are effective text generators, sensitivity to prompt construction makes performance unstable and sub-optimal in practice. Relying on a single "best" prompt cannot capture all differing approaches to a generation problem. Using this observation, we propose multi-prompt decoding, where many candidate generations are decoded from a prompt bank at inference-time. To ensemble candidates, we use Minimum Bayes Risk (MBR) decoding, which selects a final output using a trained value metric. We show multi-prompt improves MBR across a comprehensive set of conditional generation tasks, and show this is a result of estimating a more diverse and higher quality candidate space than that of a single prompt. Further experiments confirm multi-prompt improves generation across tasks, models and metrics.
GPT-4 Jailbreaks Itself with Near-Perfect Success Using Self-Explanation
May 21, 2024Research on jailbreaking has been valuable for testing and understanding the safety and security issues of large language models (LLMs). In this paper, we introduce Iterative Refinement Induced Self-Jailbreak (IRIS), a novel approach that leverages the reflective capabilities of LLMs for jailbreaking with only black-box access. Unlike previous methods, IRIS simplifies the jailbreaking process by using a single model as both the attacker and target. This method first iteratively refines adversarial prompts through self-explanation, which is crucial for ensuring that even well-aligned LLMs obey adversarial instructions. IRIS then rates and enhances the output given the refined prompt to increase its harmfulness. We find IRIS achieves jailbreak success rates of 98% on GPT-4 and 92% on GPT-4 Turbo in under 7 queries. It significantly outperforms prior approaches in automatic, black-box and interpretable jailbreaking, while requiring substantially fewer queries, thereby establishing a new standard for interpretable jailbreaking methods.
Reducing Privacy Risks in Online Self-Disclosures with Language Models
Nov 16, 2023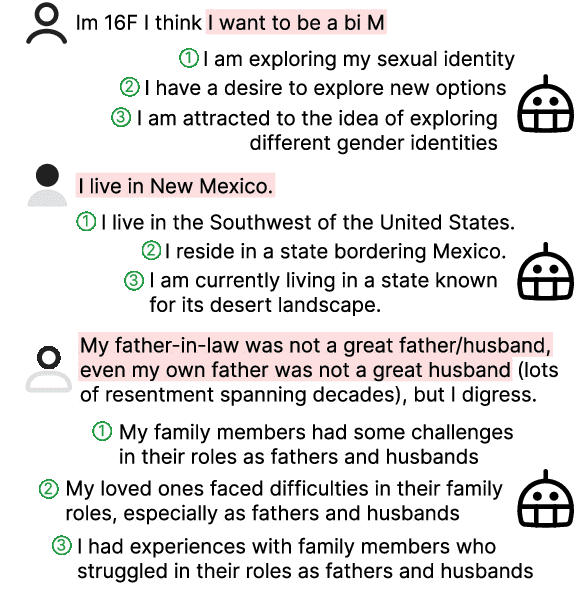

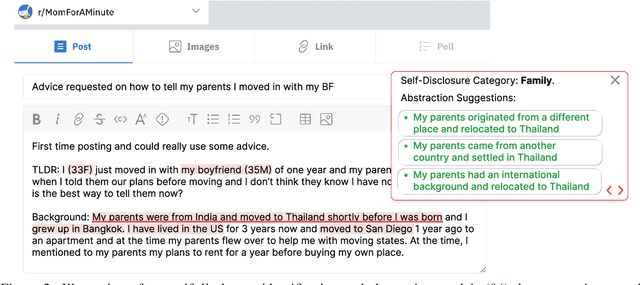
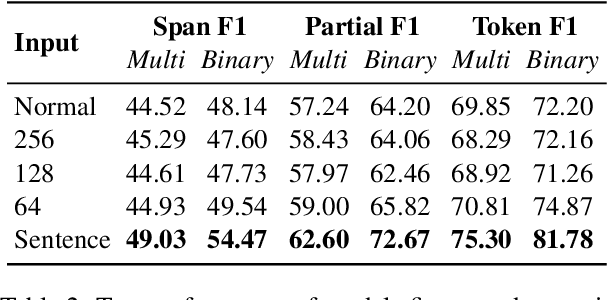
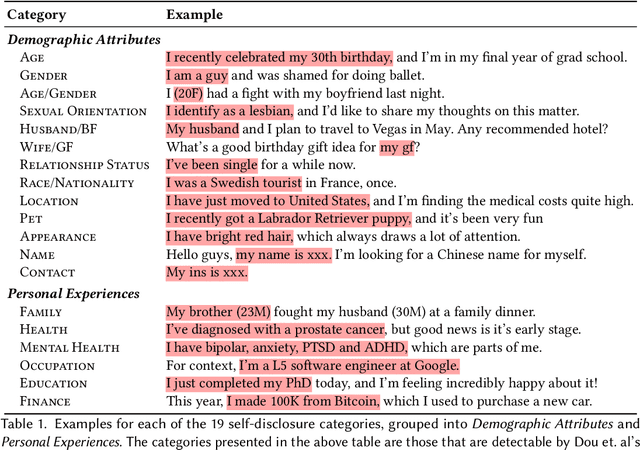
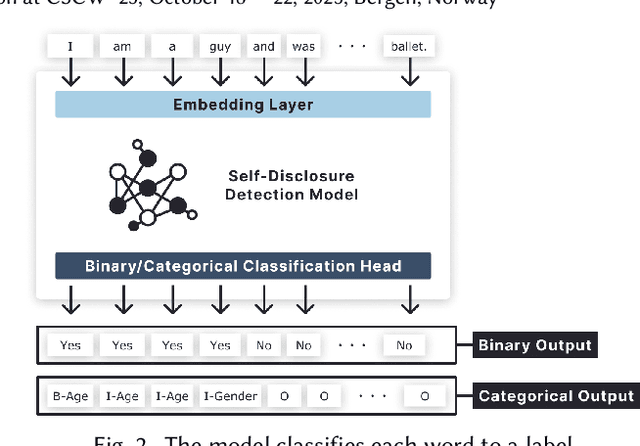
Self-disclosure, while being common and rewarding in social media interaction, also poses privacy risks. In this paper, we take the initiative to protect the user-side privacy associated with online self-disclosure through identification and abstraction. We develop a taxonomy of 19 self-disclosure categories, and curate a large corpus consisting of 4.8K annotated disclosure spans. We then fine-tune a language model for identification, achieving over 75% in Token F$_1$. We further conduct a HCI user study, with 82\% of participants viewing the model positively, highlighting its real world applicability. Motivated by the user feedback, we introduce the task of self-disclosure abstraction. We experiment with both one-span abstraction and three-span abstraction settings, and explore multiple fine-tuning strategies. Our best model can generate diverse abstractions that moderately reduce privacy risks while maintaining high utility according to human evaluation.
Automatic and Human-AI Interactive Text Generation
Oct 05, 2023In this tutorial, we focus on text-to-text generation, a class of natural language generation (NLG) tasks, that takes a piece of text as input and then generates a revision that is improved according to some specific criteria (e.g., readability or linguistic styles), while largely retaining the original meaning and the length of the text. This includes many useful applications, such as text simplification, paraphrase generation, style transfer, etc. In contrast to text summarization and open-ended text completion (e.g., story), the text-to-text generation tasks we discuss in this tutorial are more constrained in terms of semantic consistency and targeted language styles. This level of control makes these tasks ideal testbeds for studying the ability of models to generate text that is both semantically adequate and stylistically appropriate. Moreover, these tasks are interesting from a technical standpoint, as they require complex combinations of lexical and syntactical transformations, stylistic control, and adherence to factual knowledge, -- all at once. With a special focus on text simplification and revision, this tutorial aims to provide an overview of the state-of-the-art natural language generation research from four major aspects -- Data, Models, Human-AI Collaboration, and Evaluation -- and to discuss and showcase a few significant and recent advances: (1) the use of non-retrogressive approaches; (2) the shift from fine-tuning to prompting with large language models; (3) the development of new learnable metric and fine-grained human evaluation framework; (4) a growing body of studies and datasets on non-English languages; (5) the rise of HCI+NLP+Accessibility interdisciplinary research to create real-world writing assistant systems.
Thresh: A Unified, Customizable and Deployable Platform for Fine-Grained Text Evaluation
Aug 15, 2023



Fine-grained, span-level human evaluation has emerged as a reliable and robust method for evaluating text generation tasks such as summarization, simplification, machine translation and news generation, and the derived annotations have been useful for training automatic metrics and improving language models. However, existing annotation tools implemented for these evaluation frameworks lack the adaptability to be extended to different domains or languages, or modify annotation settings according to user needs. And the absence of a unified annotated data format inhibits the research in multi-task learning. In this paper, we introduce Thresh, a unified, customizable and deployable platform for fine-grained evaluation. By simply creating a YAML configuration file, users can build and test an annotation interface for any framework within minutes -- all in one web browser window. To facilitate collaboration and sharing, Thresh provides a community hub that hosts a collection of fine-grained frameworks and corresponding annotations made and collected by the community, covering a wide range of NLP tasks. For deployment, Thresh offers multiple options for any scale of annotation projects from small manual inspections to large crowdsourcing ones. Additionally, we introduce a Python library to streamline the entire process from typology design and deployment to annotation processing. Thresh is publicly accessible at https://thresh.tools.