 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"PhyWorldBench": A Comprehensive Evaluation of Physical Realism in Text-to-Video Models
Jul 17, 2025Video generation models have achieved remarkable progress in creating high-quality, photorealistic content. However, their ability to accurately simulate physical phenomena remains a critical and unresolved challenge. This paper presents PhyWorldBench, a comprehensive benchmark designed to evaluate video generation models based on their adherence to the laws of physics. The benchmark covers multiple levels of physical phenomena, ranging from fundamental principles like object motion and energy conservation to more complex scenarios involving rigid body interactions and human or animal motion. Additionally, we introduce a novel ""Anti-Physics"" category, where prompts intentionally violate real-world physics, enabling the assessment of whether models can follow such instructions while maintaining logical consistency. Besides large-scale human evaluation, we also design a simple yet effective method that could utilize current MLLM to evaluate the physics realism in a zero-shot fashion. We evaluate 12 state-of-the-art text-to-video generation models, including five open-source and five proprietary models, with a detailed comparison and analysis. we identify pivotal challenges models face in adhering to real-world physics. Through systematic testing of their outputs across 1,050 curated prompts-spanning fundamental, composite, and anti-physics scenarios-we identify pivotal challenges these models face in adhering to real-world physics. We then rigorously examine their performance on diverse physical phenomena with varying prompt types, deriving targeted recommendations for crafting prompts that enhance fidelity to physical principles.
Struct2D: A Perception-Guided Framework for Spatial Reasoning in Large Multimodal Models
Jun 04, 2025Unlocking spatial reasoning in Large Multimodal Models (LMMs) is crucial for enabling intelligent interaction with 3D environments. While prior efforts often rely on explicit 3D inputs or specialized model architectures, we ask: can LMMs reason about 3D space using only structured 2D representations derived from perception? We introduce Struct2D, a perception-guided prompting framework that combines bird's-eye-view (BEV) images with object marks and object-centric metadata, optionally incorporating egocentric keyframes when needed. Using Struct2D, we conduct an in-depth zero-shot analysis of closed-source LMMs (e.g., GPT-o3) and find that they exhibit surprisingly strong spatial reasoning abilities when provided with structured 2D inputs, effectively handling tasks such as relative direction estimation and route planning. Building on these insights, we construct Struct2D-Set, a large-scale instruction tuning dataset with 200K fine-grained QA pairs across eight spatial reasoning categories, generated automatically from 3D indoor scenes. We fine-tune an open-source LMM (Qwen2.5VL) on Struct2D-Set, achieving competitive performance on multiple benchmarks, including 3D question answering, dense captioning, and object grounding. Our approach demonstrates that structured 2D inputs can effectively bridge perception and language reasoning in LMMs-without requiring explicit 3D representations as input. We will release both our code and dataset to support future research.
TemporalBench: Benchmarking Fine-grained Temporal Understanding for Multimodal Video Models
Oct 15, 2024



Understanding fine-grained temporal dynamics is crucial for multimodal video comprehension and generation. Due to the lack of fine-grained temporal annotations, existing video benchmarks mostly resemble static image benchmarks and are incompetent at evaluating models for temporal understanding. In this paper, we introduce TemporalBench, a new benchmark dedicated to evaluating fine-grained temporal understanding in videos. TemporalBench consists of ~10K video question-answer pairs, derived from ~2K high-quality human annotations detailing the temporal dynamics in video clips. As a result, our benchmark provides a unique testbed for evaluating various temporal understanding and reasoning abilities such as action frequency, motion magnitude, event order, etc. Moreover, it enables evaluations on various tasks like both video question answering and captioning, both short and long video understanding, as well as different models such as multimodal video embedding models and text generation models. Results show that state-of-the-art models like GPT-4o achieve only 38.5% question answering accuracy on TemporalBench, demonstrating a significant gap (~30%) between humans and AI in temporal understanding. Furthermore, we notice a critical pitfall for multi-choice QA where LLMs can detect the subtle changes in negative captions and find a centralized description as a cue for its prediction, where we propose Multiple Binary Accuracy (MBA) to correct such bias. We hope that TemporalBench can foster research on improving models' temporal reasoning capabilities. Both dataset and evaluation code will be made available.
Towards Flexible Visual Relationship Segmentation
Aug 15, 2024Visual relationship understanding has been studied separately in human-object interaction(HOI) detection, scene graph generation(SGG), and referring relationships(RR) tasks. Given the complexity and interconnectedness of these tasks, it is crucial to have a flexible framework that can effectively address these tasks in a cohesive manner. In this work, we propose FleVRS, a single model that seamlessly integrates the above three aspects in standard and promptable visual relationship segmentation, and further possesses the capability for open-vocabulary segmentation to adapt to novel scenarios. FleVRS leverages the synergy between text and image modalities, to ground various types of relationships from images and use textual features from vision-language models to visual conceptual understanding. Empirical validation across various datasets demonstrates that our framework outperforms existing models in standard, promptable, and open-vocabulary tasks, e.g., +1.9 $mAP$ on HICO-DET, +11.4 $Acc$ on VRD, +4.7 $mAP$ on unseen HICO-DET. Our FleVRS represents a significant step towards a more intuitive, comprehensive, and scalable understanding of visual relationships.
Zero-shot Referring Expression Comprehension via Structural Similarity Between Images and Captions
Nov 28, 2023

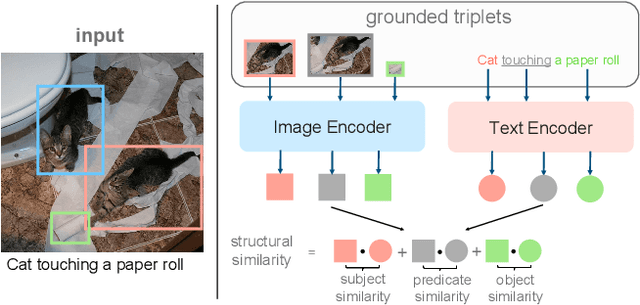

Zero-shot referring expression comprehension aims at localizing bounding boxes in an image corresponding to the provided textual prompts, which requires: (i) a fine-grained disentanglement of complex visual scene and textual context, and (ii) a capacity to understand relationships among disentangled entities. Unfortunately, existing large vision-language alignment (VLA) models, e.g., CLIP, struggle with both aspects so cannot be directly used for this task. To mitigate this gap, we leverage large foundation models to disentangle both images and texts into triplets in the format of (subject, predicate, object). After that, grounding is accomplished by calculating the structural similarity matrix between visual and textual triplets with a VLA model, and subsequently propagate it to an instance-level similarity matrix. Furthermore, to equip VLA models with the ability of relationship understanding, we design a triplet-matching objective to fine-tune the VLA models on a collection of curated dataset containing abundant entity relationships. Experiments demonstrate that our visual grounding performance increase of up to 19.5% over the SOTA zero-shot model on RefCOCO/+/g. On the more challenging Who's Waldo dataset, our zero-shot approach achieves comparable accuracy to the fully supervised model.
Diagnosing Human-object Interaction Detectors
Aug 16, 2023Although we have witnessed significant progress in human-object interaction (HOI) detection with increasingly high mAP (mean Average Precision), a single mAP score is too concise to obtain an informative summary of a model's performance and to understand why one approach is better than another. In this paper, we introduce a diagnosis toolbox for analyzing the error sources of the existing HOI detection models. We first conduct holistic investigations in the pipeline of HOI detection, consisting of human-object pair detection and then interaction classification. We define a set of errors and the oracles to fix each of them. By measuring the mAP improvement obtained from fixing an error using its oracle, we can have a detailed analysis of the significance of different errors. We then delve into the human-object detection and interaction classification, respectively, and check the model's behavior. For the first detection task, we investigate both recall and precision, measuring the coverage of ground-truth human-object pairs as well as the noisiness level in the detections. For the second classification task, we compute mAP for interaction classification only, without considering the detection scores. We also measure the performance of the models in differentiating human-object pairs with and without actual interactions using the AP (Average Precision) score. Our toolbox is applicable for different methods across different datasets and available at https://github.com/neu-vi/Diag-HOI.
A Unified Efficient Pyramid Transformer for Semantic Segmentation
Jul 29, 2021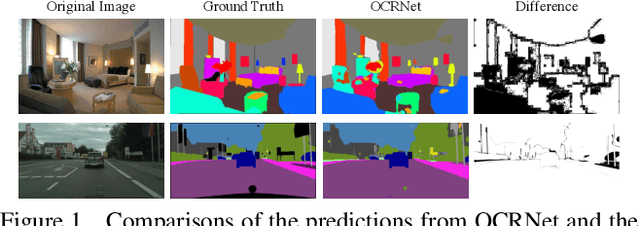
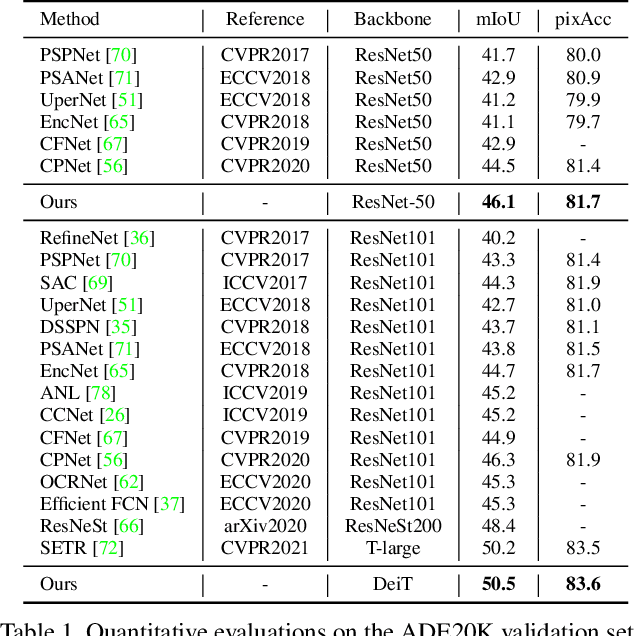
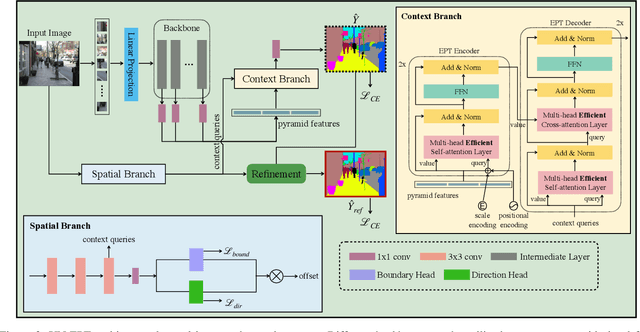
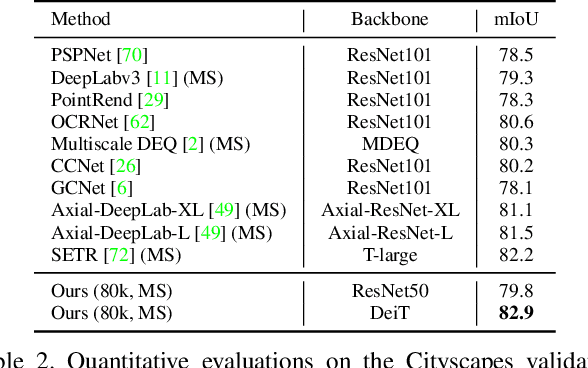
Semantic segmentation is a challenging problem due to difficulties in modeling context in complex scenes and class confusions along boundaries. Most literature either focuses on context modeling or boundary refinement, which is less generalizable in open-world scenarios. In this work, we advocate a unified framework(UN-EPT) to segment objects by considering both context information and boundary artifacts. We first adapt a sparse sampling strategy to incorporate the transformer-based attention mechanism for efficient context modeling. In addition, a separate spatial branch is introduced to capture image details for boundary refinement. The whole model can be trained in an end-to-end manner. We demonstrate promising performance on three popular benchmarks for semantic segmentation with low memory footprint. Code will be released soon.
Self-supervised Video Object Segmentation
Jun 22, 2020
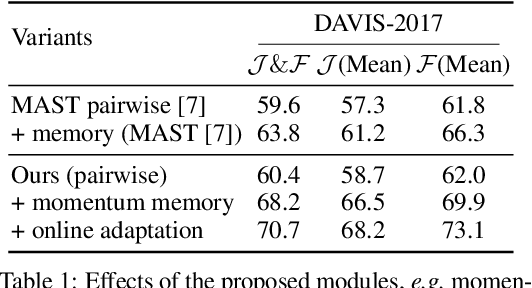
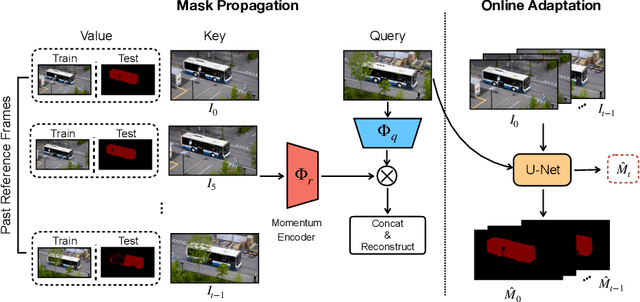

The objective of this paper is self-supervised representation learning, with the goal of solving semi-supervised video object segmentation (a.k.a. dense tracking). We make the following contributions: (i) we propose to improve the existing self-supervised approach, with a simple, yet more effective memory mechanism for long-term correspondence matching, which resolves the challenge caused by the dis-appearance and reappearance of objects; (ii) by augmenting the self-supervised approach with an online adaptation module, our method successfully alleviates tracker drifts caused by spatial-temporal discontinuity, e.g. occlusions or dis-occlusions, fast motions; (iii) we explore the efficiency of self-supervised representation learning for dense tracking, surprisingly, we show that a powerful tracking model can be trained with as few as 100 raw video clips (equivalent to a duration of 11mins), indicating that low-level statistics have already been effective for tracking tasks; (iv) we demonstrate state-of-the-art results among the self-supervised approaches on DAVIS-2017 and YouTube-VOS, as well as surpassing most of methods trained with millions of manual segmentation annotations, further bridging the gap between self-supervised and supervised learning. Codes are released to foster any further research (https://github.com/fangruizhu/self_sup_semiVOS).
Long-Term Cloth-Changing Person Re-identification
May 27, 2020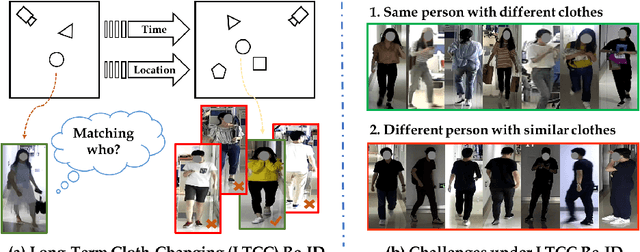
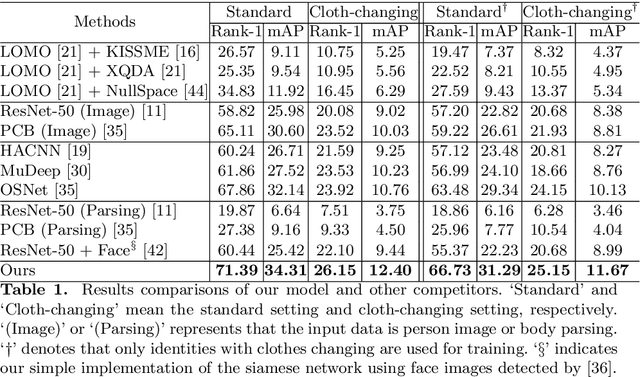
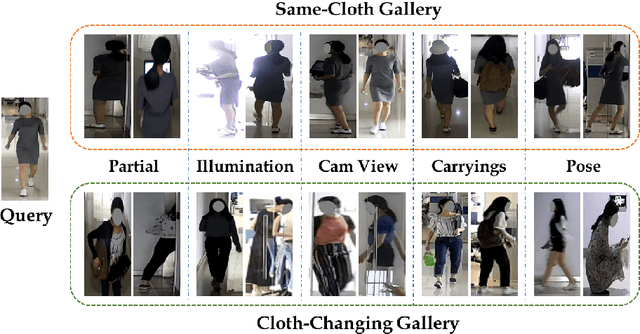
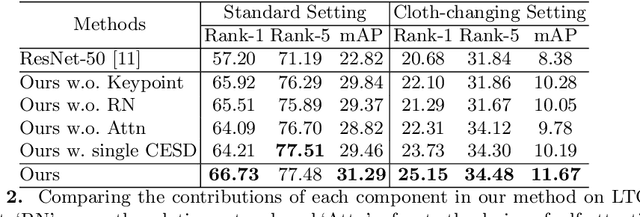
Person re-identification (Re-ID) aims to match a target person across camera views at different locations and times. Existing Re-ID studies focus on the short-term cloth-consistent setting, under which a person re-appears in different camera views with the same outfit. A discriminative feature representation learned by existing deep Re-ID models is thus dominated by the visual appearance of clothing. In this work, we focus on a much more difficult yet practical setting where person matching is conducted over long-duration, e.g., over days and months and therefore inevitably under the new challenge of changing clothes. This problem, termed Long-Term Cloth-Changing (LTCC) Re-ID is much understudied due to the lack of large scale datasets. The first contribution of this work is a new LTCC dataset containing people captured over a long period of time with frequent clothing changes. As a second contribution, we propose a novel Re-ID method specifically designed to address the cloth-changing challenge. Specifically, we consider that under cloth-changes, soft-biometrics such as body shape would be more reliable. We, therefore, introduce a shape embedding module as well as a cloth-elimination shape-distillation module aiming to eliminate the now unreliable clothing appearance features and focus on the body shape information. Extensive experiments show that superior performance is achieved by the proposed model on the new LTCC dataset. The code and dataset will be available at https://naiq.github.io/LTCC_Perosn_ReID.html.
A Two-point Method for PTZ Camera Calibration in Sports
Jan 26, 2018
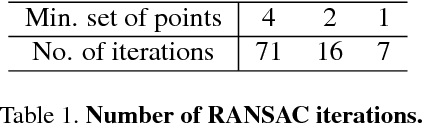

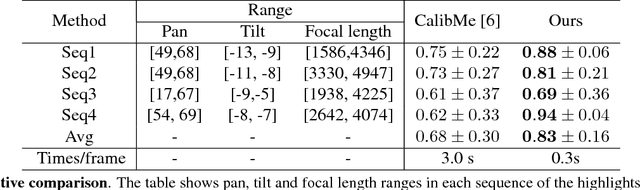
Calibrating narrow field of view soccer cameras is challenging because there are very few field markings in the image. Unlike previous solutions, we propose a two-point method, which requires only two point correspondences given the prior knowledge of base location and orientation of a pan-tilt-zoom (PTZ) camera. We deploy this new calibration method to annotate pan-tilt-zoom data from soccer videos. The collected data are used as references for new images. We also propose a fast random forest method to predict pan-tilt angles without image-to-image feature matching, leading to an efficient calibration method for new images. We demonstrate our system on synthetic data and two real soccer datasets. Our two-point approach achieves superior performance over the state-of-the-art method.