 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM$^3$Eval: Multi-Modal Memory Evaluation through Cognitively-Grounded Video Tasks
Jun 03, 2026As multi-modal models advance towards long-form video understanding, memory emerges as a critical capability. Despite substantial efforts in developing video datasets and benchmarks, existing works primarily focus on perception and reasoning, without systematically evaluating memory: what models retain, how faithfully information is preserved, and how robust memory remains under interference. To address this gap, we introduce M$^3$Eval, the first comprehensive evaluation framework and benchmark for probing different memory dimensions in multi-modal models. Grounded in cognitive psychology, our design features carefully constructed tasks that isolate key aspects of memory. Leveraging M$^3$Eval, we conduct extensive experiments across representative multi-modal models, revealing consistent weaknesses and distinctive behaviors. We find that models struggle to maintain disentangled representations when processing parallel video streams, exhibit interference patterns differing substantially from those observed in human memory, ground memory sources more reliably in the spatial domain than the temporal domain, and demonstrate limited symbolic memory. Collectively, our benchmark provides a valuable resource for future research, while our findings highlight memory as a fundamental yet underexplored capability and offer insights for designing more effective memory mechanisms in multi-modal models. Our code and dataset are available at https://pku-value-lab.github.io/m3eval-homepage.
Preserve Support, Not Correspondence: Dynamic Routing for Offline Reinforcement Learning
Apr 24, 2026One-step offline RL actors are attractive because they avoid backpropagating through long iterative samplers and keep inference cheap, but they still have to improve under a critic without drifting away from actions that the dataset can support. In recent one-step extraction pipelines, a strong iterative teacher provides one target action for each latent draw, and the same student output is asked to do both jobs: move toward higher Q and stay near that paired endpoint. If those two directions disagree, the loss resolves them as a compromise on that same sample, even when a nearby better action remains locally supported by the data. We propose DROL, a latent-conditioned one-step actor trained with top-1 dynamic routing. For each state, the actor samples $K$ candidate actions from a bounded latent prior, assigns each dataset action to its nearest candidate, and updates only that winner with Behavior Cloning and critic guidance. Because the routing is recomputed from the current candidate geometry, ownership of a supported region can shift across candidates over the course of learning. This gives a one-step actor room to make local improvements that pointwise extraction struggles to capture, while retaining single-pass inference at test time. On OGBench and D4RL, DROL is competitive with the one-step FQL baseline, improving many OGBench task groups while remaining strong on both AntMaze and Adroit. Project page: https://muzhancun.github.io/preprints/DROL.
TextShield-R1: Reinforced Reasoning for Tampered Text Detection
Feb 23, 2026The growing prevalence of tampered images poses serious security threats, highlighting the urgent need for reliable detection methods. Multimodal large language models (MLLMs) demonstrate strong potential in analyzing tampered images and generating interpretations. However, they still struggle with identifying micro-level artifacts, exhibit low accuracy in localizing tampered text regions, and heavily rely on expensive annotations for forgery interpretation. To this end, we introduce TextShield-R1, the first reinforcement learning based MLLM solution for tampered text detection and reasoning. Specifically, our approach introduces Forensic Continual Pre-training, an easy-to-hard curriculum that well prepares the MLLM for tampered text detection by harnessing the large-scale cheap data from natural image forensic and OCR tasks. During fine-tuning, we perform Group Relative Policy Optimization with novel reward functions to reduce annotation dependency and improve reasoning capabilities. At inference time, we enhance localization accuracy via OCR Rectification, a method that leverages the MLLM's strong text recognition abilities to refine its predictions. Furthermore, to support rigorous evaluation, we introduce the Text Forensics Reasoning (TFR) benchmark, comprising over 45k real and tampered images across 16 languages, 10 tampering techniques, and diverse domains. Rich reasoning-style annotations are included, allowing for comprehensive assessment. Our TFR benchmark simultaneously addresses seven major limitations of existing benchmarks and enables robust evaluation under cross-style, cross-method, and cross-language conditions. Extensive experiments demonstrate that TextShield-R1 significantly advances the state of the art in interpretable tampered text detection.
Rethinking Chain-of-Thought Reasoning for Videos
Dec 10, 2025Chain-of-thought (CoT) reasoning has been highly successful in solving complex tasks in natural language processing, and recent multimodal large language models (MLLMs) have extended this paradigm to video reasoning. However, these models typically build on lengthy reasoning chains and large numbers of input visual tokens. Motivated by empirical observations from our benchmark study, we hypothesize that concise reasoning combined with a reduced set of visual tokens can be sufficient for effective video reasoning. To evaluate this hypothesis, we design and validate an efficient post-training and inference framework that enhances a video MLLM's reasoning capability. Our framework enables models to operate on compressed visual tokens and generate brief reasoning traces prior to answering. The resulting models achieve substantially improved inference efficiency, deliver competitive performance across diverse benchmarks, and avoid reliance on manual CoT annotations or supervised fine-tuning. Collectively, our results suggest that long, human-like CoT reasoning may not be necessary for general video reasoning, and that concise reasoning can be both effective and efficient. Our code will be released at https://github.com/LaVi-Lab/Rethink_CoT_Video.
Webly-Supervised Image Manipulation Localization via Category-Aware Auto-Annotation
Aug 28, 2025
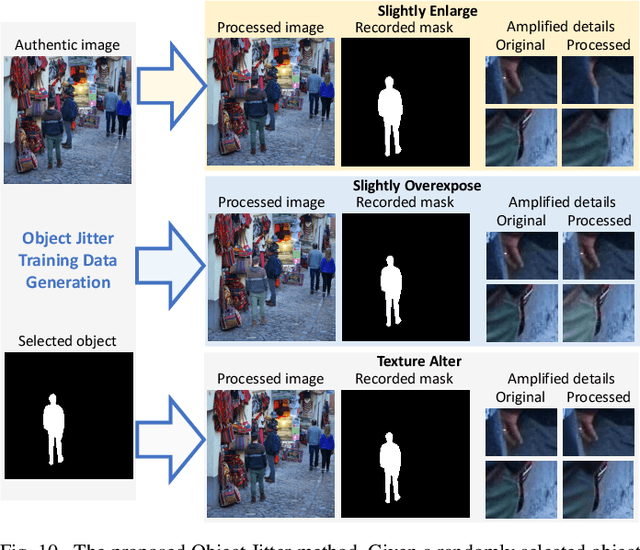
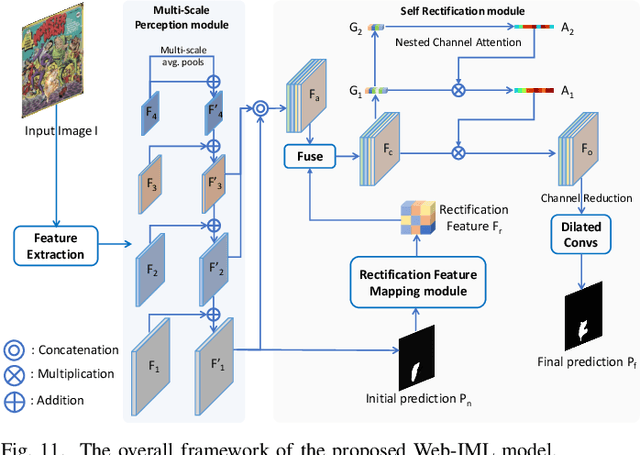

Images manipulated using image editing tools can mislead viewers and pose significant risks to social security. However, accurately localizing the manipulated regions within an image remains a challenging problem. One of the main barriers in this area is the high cost of data acquisition and the severe lack of high-quality annotated datasets. To address this challenge, we introduce novel methods that mitigate data scarcity by leveraging readily available web data. We utilize a large collection of manually forged images from the web, as well as automatically generated annotations derived from a simpler auxiliary task, constrained image manipulation localization. Specifically, we introduce a new paradigm CAAAv2, which automatically and accurately annotates manipulated regions at the pixel level. To further improve annotation quality, we propose a novel metric, QES, which filters out unreliable annotations. Through CAAA v2 and QES, we construct MIMLv2, a large-scale, diverse, and high-quality dataset containing 246,212 manually forged images with pixel-level mask annotations. This is over 120x larger than existing handcrafted datasets like IMD20. Additionally, we introduce Object Jitter, a technique that further enhances model training by generating high-quality manipulation artifacts. Building on these advances, we develop a new model, Web-IML, designed to effectively leverage web-scale supervision for the image manipulation localization task. Extensive experiments demonstrate that our approach substantially alleviates the data scarcity problem and significantly improves the performance of various models on multiple real-world forgery benchmarks. With the proposed web supervision, Web-IML achieves a striking performance gain of 31% and surpasses previous SOTA TruFor by 24.1 average IoU points. The dataset and code will be made publicly available at https://github.com/qcf-568/MIML.
PAVE: Patching and Adapting Video Large Language Models
Mar 25, 2025Pre-trained video large language models (Video LLMs) exhibit remarkable reasoning capabilities, yet adapting these models to new tasks involving additional modalities or data types (e.g., audio or 3D information) remains challenging. In this paper, we present PAVE, a flexible framework for adapting pre-trained Video LLMs to downstream tasks with side-channel signals, such as audio, 3D cues, or multi-view videos. PAVE introduces lightweight adapters, referred to as "patches," which add a small number of parameters and operations to a base model without modifying its architecture or pre-trained weights. In doing so, PAVE can effectively adapt the pre-trained base model to support diverse downstream tasks, including audio-visual question answering, 3D reasoning, multi-view video recognition, and high frame rate video understanding. Across these tasks, PAVE significantly enhances the performance of the base model, surpassing state-of-the-art task-specific models while incurring a minor cost of ~0.1% additional FLOPs and parameters. Further, PAVE supports multi-task learning and generalizes well across different Video LLMs. Our code is available at https://github.com/dragonlzm/PAVE.
AIM: Adaptive Inference of Multi-Modal LLMs via Token Merging and Pruning
Dec 04, 2024Large language models (LLMs) have enabled the creation of multi-modal LLMs that exhibit strong comprehension of visual data such as images and videos. However, these models usually rely on extensive visual tokens from visual encoders, leading to high computational demands, which limits their applicability in resource-constrained environments and for long-context tasks. In this work, we propose a training-free adaptive inference method for multi-modal LLMs that can accommodate a broad range of efficiency requirements with a minimum performance drop. Our method consists of a) iterative token merging based on embedding similarity before LLMs, and b) progressive token pruning within LLM layers based on multi-modal importance. With a minimalist design, our method can be applied to both video and image LLMs. Extensive experiments on diverse video and image benchmarks demonstrate that, our method substantially reduces computation load (e.g., a $\textbf{7-fold}$ reduction in FLOPs) while preserving the performance of video and image LLMs. Further, under a similar computational cost, our method outperforms the state-of-the-art methods in long video understanding (e.g., $\textbf{+4.6}$ on MLVU). Additionally, our in-depth analysis provides insights into token redundancy and LLM layer behaviors, offering guidance for future research in designing efficient multi-modal LLMs. Our code will be available at https://github.com/LaVi-Lab/AIM.
Omni-IML: Towards Unified Image Manipulation Localization
Nov 22, 2024

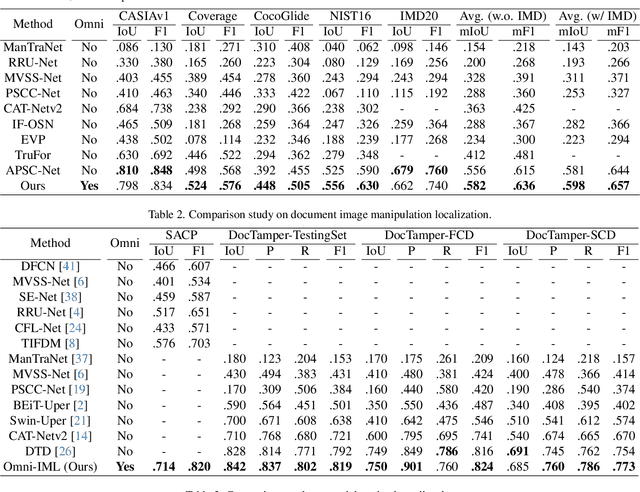

Image manipulation can lead to misinterpretation of visual content, posing significant risks to information security. Image Manipulation Localization (IML) has thus received increasing attention. However, existing IML methods rely heavily on task-specific designs, making them perform well only on one target image type but are mostly random guessing on other image types, and even joint training on multiple image types causes significant performance degradation. This hinders the deployment for real applications as it notably increases maintenance costs and the misclassification of image types leads to serious error accumulation. To this end, we propose Omni-IML, the first generalist model to unify diverse IML tasks. Specifically, Omni-IML achieves generalism by adopting the Modal Gate Encoder and the Dynamic Weight Decoder to adaptively determine the optimal encoding modality and the optimal decoder filters for each sample. We additionally propose an Anomaly Enhancement module that enhances the features of tampered regions with box supervision and helps the generalist model to extract common features across different IML tasks. We validate our approach on IML tasks across three major scenarios: natural images, document images, and face images. Without bells and whistles, our Omni-IML achieves state-of-the-art performance on all three tasks with a single unified model, providing valuable strategies and insights for real-world application and future research in generalist image forensics. Our code will be publicly available.
TemporalBench: Benchmarking Fine-grained Temporal Understanding for Multimodal Video Models
Oct 15, 2024



Understanding fine-grained temporal dynamics is crucial for multimodal video comprehension and generation. Due to the lack of fine-grained temporal annotations, existing video benchmarks mostly resemble static image benchmarks and are incompetent at evaluating models for temporal understanding. In this paper, we introduce TemporalBench, a new benchmark dedicated to evaluating fine-grained temporal understanding in videos. TemporalBench consists of ~10K video question-answer pairs, derived from ~2K high-quality human annotations detailing the temporal dynamics in video clips. As a result, our benchmark provides a unique testbed for evaluating various temporal understanding and reasoning abilities such as action frequency, motion magnitude, event order, etc. Moreover, it enables evaluations on various tasks like both video question answering and captioning, both short and long video understanding, as well as different models such as multimodal video embedding models and text generation models. Results show that state-of-the-art models like GPT-4o achieve only 38.5% question answering accuracy on TemporalBench, demonstrating a significant gap (~30%) between humans and AI in temporal understanding. Furthermore, we notice a critical pitfall for multi-choice QA where LLMs can detect the subtle changes in negative captions and find a centralized description as a cue for its prediction, where we propose Multiple Binary Accuracy (MBA) to correct such bias. We hope that TemporalBench can foster research on improving models' temporal reasoning capabilities. Both dataset and evaluation code will be made available.
Enhancing Temporal Modeling of Video LLMs via Time Gating
Oct 08, 2024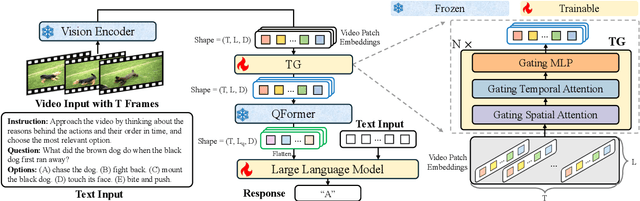


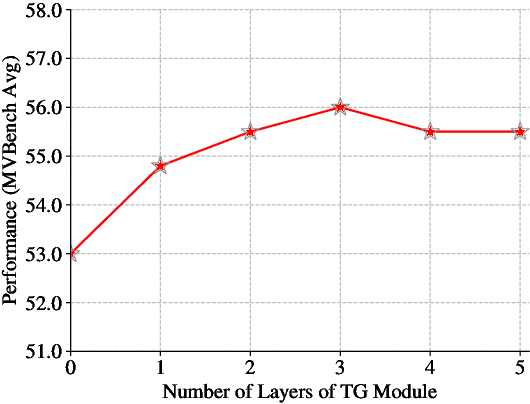
Video Large Language Models (Video LLMs) have achieved impressive performance on video-and-language tasks, such as video question answering. However, most existing Video LLMs neglect temporal information in video data, leading to struggles with temporal-aware video understanding. To address this gap, we propose a Time Gating Video LLM (TG-Vid) designed to enhance temporal modeling through a novel Time Gating module (TG). The TG module employs a time gating mechanism on its sub-modules, comprising gating spatial attention, gating temporal attention, and gating MLP. This architecture enables our model to achieve a robust understanding of temporal information within videos. Extensive evaluation of temporal-sensitive video benchmarks (i.e., MVBench, TempCompass, and NExT-QA) demonstrates that our TG-Vid model significantly outperforms the existing Video LLMs. Further, comprehensive ablation studies validate that the performance gains are attributed to the designs of our TG module. Our code is available at https://github.com/LaVi-Lab/TG-Vid.