 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2026 Challenge on Robust AI-Generated Image Detection in the Wild
Apr 13, 2026This paper presents an overview of the NTIRE 2026 Challenge on Robust AI-Generated Image Detection in the Wild, held in conjunction with the NTIRE workshop at CVPR 2026. The goal of this challenge was to develop detection models capable of distinguishing real images from generated ones in realistic scenarios: the images are often transformed (cropped, resized, compressed, blurred) for practical usage, and therefore, the detection models should be robust to such transformations. The challenge is based on a novel dataset consisting of 108,750 real and 185,750 AI-generated images from 42 generators comprising a large variety of open-source and closed-source models of various architectures, augmented with 36 image transformations. Methods were evaluated using ROC AUC on the full test set, including both transformed and untransformed images. A total of 511 participants registered, with 20 teams submitting valid final solutions. This report provides a comprehensive overview of the challenge, describes the proposed solutions, and can be used as a valuable reference for researchers and practitioners in increasing the robustness of the detection models to real-world transformations.
NTIRE 2026 Challenge on Single Image Reflection Removal in the Wild: Datasets, Results, and Methods
Apr 11, 2026In this paper, we review the NTIRE 2026 challenge on single-image reflection removal (SIRR) in the Wild. SIRR is a fundamental task in image restoration. Despite progress in academic research, most methods are tested on synthetic images or limited real-world images, creating a gap in real-world applications. In this challenge, we provide participants with the OpenRR-5k dataset, which requires them to process real-world images that cover a range of reflection scenarios and intensities, with the goal of generating clean images without reflections. The challenge attracted more than 100 registrations, with 11 of them participating in the final testing phase. The top-ranked methods advanced the state-of-the-art reflection removal performance and earned unanimous recognition from the five experts in the field. The proposed OpenRR-5k dataset is available at https://huggingface.co/datasets/qiuzhangTiTi/OpenRR-5k, and the homepage of this challenge is at https://github.com/caijie0620/OpenRR-5k. Due to page limitations, this article only presents partial content; the full report and detailed analyses are available in the extended arXiv version.
LOGER: Local--Global Ensemble for Robust Deepfake Detection in the Wild
Apr 04, 2026Robust deepfake detection in the wild remains challenging due to the ever-growing variety of manipulation techniques and uncontrolled real-world degradations. Forensic cues for deepfake detection reside at two complementary levels: global-level anomalies in semantics and statistics that require holistic image understanding, and local-level forgery traces concentrated in manipulated regions that are easily diluted by global averaging. Since no single backbone or input scale can effectively cover both levels, we propose LOGER, a LOcal--Global Ensemble framework for Robust deepfake detection. The global branch employs heterogeneous vision foundation model backbones at multiple resolutions to capture holistic anomalies with diverse visual priors. The local branch performs patch-level modeling with a Multiple Instance Learning top-$k$ aggregation strategy that selectively pools only the most suspicious regions, mitigating evidence dilution caused by the dominance of normal patches; dual-level supervision at both the aggregated image level and individual patch level keeps local responses discriminative. Because the two branches differ in both granularity and backbone, their errors are largely decorrelated, a property that logit-space fusion exploits for more robust prediction. LOGER achieves 2nd place in the NTIRE 2026 Robust Deepfake Detection Challenge, and further evaluation on multiple public benchmarks confirms its strong robustness and generalization across diverse manipulation methods and real-world degradation conditions.
HEDGE: Heterogeneous Ensemble for Detection of AI-GEnerated Images in the Wild
Apr 04, 2026Robust detection of AI-generated images in the wild remains challenging due to the rapid evolution of generative models and varied real-world distortions. We argue that relying on a single training regime, resolution, or backbone is insufficient to handle all conditions, and that structured heterogeneity across these dimensions is essential for robust detection. To this end, we propose HEDGE, a Heterogeneous Ensemble for Detection of AI-GEnerated images, that introduces complementary detection routes along three axes: diverse training data with strong augmentation, multi-scale feature extraction, and backbone heterogeneity. Specifically, Route~A progressively constructs DINOv3-based detectors through staged data expansion and augmentation escalation, Route~B incorporates a higher-resolution branch for fine-grained forensic cues, and Route~C adds a MetaCLIP2-based branch for backbone diversity. All outputs are fused via logit-space weighted averaging, refined by a lightweight dual-gating mechanism that handles branch-level outliers and majority-dominated fusion errors. HEDGE achieves 4th place in the NTIRE 2026 Robust AI-Generated Image Detection in the Wild Challenge and attains state-of-the-art performance with strong robustness on multiple AIGC image detection benchmarks.
PosterVerse: A Full-Workflow Framework for Commercial-Grade Poster Generation with HTML-Based Scalable Typography
Jan 07, 2026Commercial-grade poster design demands the seamless integration of aesthetic appeal with precise, informative content delivery. Current automated poster generation systems face significant limitations, including incomplete design workflows, poor text rendering accuracy, and insufficient flexibility for commercial applications. To address these challenges, we propose PosterVerse, a full-workflow, commercial-grade poster generation method that seamlessly automates the entire design process while delivering high-density and scalable text rendering. PosterVerse replicates professional design through three key stages: (1) blueprint creation using fine-tuned LLMs to extract key design elements from user requirements, (2) graphical background generation via customized diffusion models to create visually appealing imagery, and (3) unified layout-text rendering with an MLLM-powered HTML engine to guarantee high text accuracy and flexible customization. In addition, we introduce PosterDNA, a commercial-grade, HTML-based dataset tailored for training and validating poster design models. To the best of our knowledge, PosterDNA is the first Chinese poster generation dataset to introduce HTML typography files, enabling scalable text rendering and fundamentally solving the challenges of rendering small and high-density text. Experimental results demonstrate that PosterVerse consistently produces commercial-grade posters with appealing visuals, accurate text alignment, and customizable layouts, making it a promising solution for automating commercial poster design. The code and model are available at https://github.com/wuhaer/PosterVerse.
NTIRE 2025 Challenge on Image Super-Resolution ($\times$4): Methods and Results
Apr 20, 2025This paper presents the NTIRE 2025 image super-resolution ($\times$4) challenge, one of the associated competitions of the 10th NTIRE Workshop at CVPR 2025. The challenge aims to recover high-resolution (HR) images from low-resolution (LR) counterparts generated through bicubic downsampling with a $\times$4 scaling factor. The objective is to develop effective network designs or solutions that achieve state-of-the-art SR performance. To reflect the dual objectives of image SR research, the challenge includes two sub-tracks: (1) a restoration track, emphasizes pixel-wise accuracy and ranks submissions based on PSNR; (2) a perceptual track, focuses on visual realism and ranks results by a perceptual score. A total of 286 participants registered for the competition, with 25 teams submitting valid entries. This report summarizes the challenge design, datasets, evaluation protocol, the main results, and methods of each team. The challenge serves as a benchmark to advance the state of the art and foster progress in image SR.
Omni-IML: Towards Unified Image Manipulation Localization
Nov 22, 2024

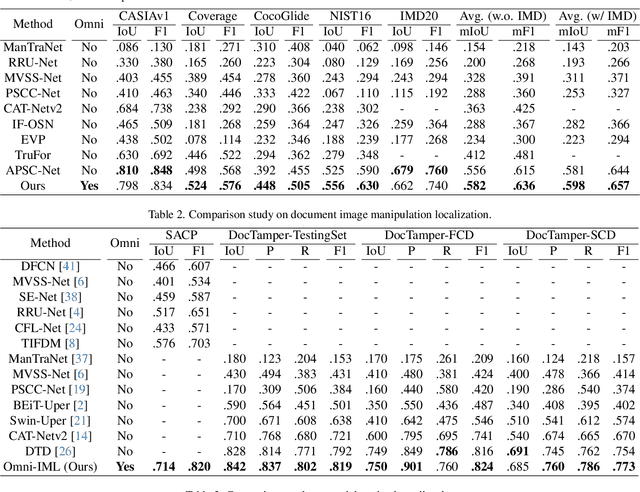

Image manipulation can lead to misinterpretation of visual content, posing significant risks to information security. Image Manipulation Localization (IML) has thus received increasing attention. However, existing IML methods rely heavily on task-specific designs, making them perform well only on one target image type but are mostly random guessing on other image types, and even joint training on multiple image types causes significant performance degradation. This hinders the deployment for real applications as it notably increases maintenance costs and the misclassification of image types leads to serious error accumulation. To this end, we propose Omni-IML, the first generalist model to unify diverse IML tasks. Specifically, Omni-IML achieves generalism by adopting the Modal Gate Encoder and the Dynamic Weight Decoder to adaptively determine the optimal encoding modality and the optimal decoder filters for each sample. We additionally propose an Anomaly Enhancement module that enhances the features of tampered regions with box supervision and helps the generalist model to extract common features across different IML tasks. We validate our approach on IML tasks across three major scenarios: natural images, document images, and face images. Without bells and whistles, our Omni-IML achieves state-of-the-art performance on all three tasks with a single unified model, providing valuable strategies and insights for real-world application and future research in generalist image forensics. Our code will be publicly available.
Generalized Tampered Scene Text Detection in the era of Generative AI
Jul 31, 2024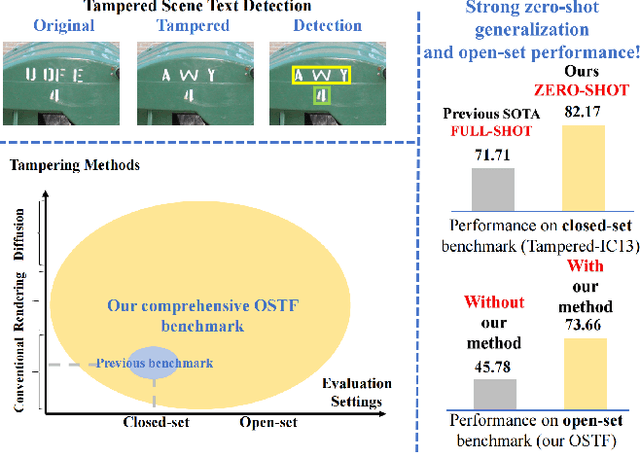

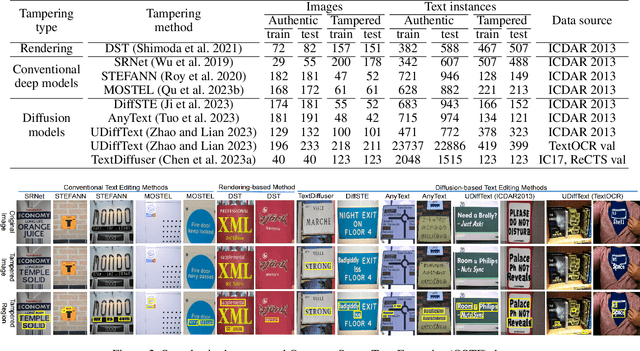

The rapid advancements of generative AI have fueled the potential of generative text image editing while simultaneously escalating the threat of misinformation spreading. However, existing forensics methods struggle to detect unseen forgery types that they have not been trained on, leaving the development of a model capable of generalized detection of tampered scene text as an unresolved issue. To tackle this, we propose a novel task: open-set tampered scene text detection, which evaluates forensics models on their ability to identify both seen and previously unseen forgery types. We have curated a comprehensive, high-quality dataset, featuring the texts tampered by eight text editing models, to thoroughly assess the open-set generalization capabilities. Further, we introduce a novel and effective pre-training paradigm that subtly alters the texture of selected texts within an image and trains the model to identify these regions. This approach not only mitigates the scarcity of high-quality training data but also enhances models' fine-grained perception and open-set generalization abilities. Additionally, we present DAF, a novel framework that improves open-set generalization by distinguishing between the features of authentic and tampered text, rather than focusing solely on the tampered text's features. Our extensive experiments validate the remarkable efficacy of our methods. For example, our zero-shot performance can even beat the previous state-of-the-art full-shot model by a large margin. Our dataset and code will be open-source.
SemanticMIM: Marring Masked Image Modeling with Semantics Compression for General Visual Representation
Jun 15, 2024



This paper represents a neat yet effective framework, named SemanticMIM, to integrate the advantages of masked image modeling (MIM) and contrastive learning (CL) for general visual representation. We conduct a thorough comparative analysis between CL and MIM, revealing that their complementary advantages fundamentally stem from two distinct phases, i.e., compression and reconstruction. Specifically, SemanticMIM leverages a proxy architecture that customizes interaction between image and mask tokens, bridging these two phases to achieve general visual representation with the property of abundant semantic and positional awareness. Through extensive qualitative and quantitative evaluations, we demonstrate that SemanticMIM effectively amalgamates the benefits of CL and MIM, leading to significant enhancement of performance and feature linear separability. SemanticMIM also offers notable interpretability through attention response visualization. Codes are available at https://github.com/yyk-wew/SemanticMIM.
UPOCR: Towards Unified Pixel-Level OCR Interface
Dec 05, 2023In recent years, the optical character recognition (OCR) field has been proliferating with plentiful cutting-edge approaches for a wide spectrum of tasks. However, these approaches are task-specifically designed with divergent paradigms, architectures, and training strategies, which significantly increases the complexity of research and maintenance and hinders the fast deployment in applications. To this end, we propose UPOCR, a simple-yet-effective generalist model for Unified Pixel-level OCR interface. Specifically, the UPOCR unifies the paradigm of diverse OCR tasks as image-to-image transformation and the architecture as a vision Transformer (ViT)-based encoder-decoder. Learnable task prompts are introduced to push the general feature representations extracted by the encoder toward task-specific spaces, endowing the decoder with task awareness. Moreover, the model training is uniformly aimed at minimizing the discrepancy between the generated and ground-truth images regardless of the inhomogeneity among tasks. Experiments are conducted on three pixel-level OCR tasks including text removal, text segmentation, and tampered text detection. Without bells and whistles, the experimental results showcase that the proposed method can simultaneously achieve state-of-the-art performance on three tasks with a unified single model, which provides valuable strategies and insights for future research on generalist OCR models. Code will be publicly available.