 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocAligner: Annotating Real-world Photographic Document Images by Simply Taking Pictures
Jun 12, 2023



Recently, there has been a growing interest in research concerning document image analysis and recognition in photographic scenarios. However, the lack of labeled datasets for this emerging challenge poses a significant obstacle, as manual annotation can be time-consuming and impractical. To tackle this issue, we present DocAligner, a novel method that streamlines the manual annotation process to a simple step of taking pictures. DocAligner achieves this by establishing dense correspondence between photographic document images and their clean counterparts. It enables the automatic transfer of existing annotations in clean document images to photographic ones and helps to automatically acquire labels that are unavailable through manual labeling. Considering the distinctive characteristics of document images, DocAligner incorporates several innovative features. First, we propose a non-rigid pre-alignment technique based on the document's edges, which effectively eliminates interference caused by significant global shifts and repetitive patterns present in document images. Second, to handle large shifts and ensure high accuracy, we introduce a hierarchical aligning approach that combines global and local correlation layers. Furthermore, considering the importance of fine-grained elements in document images, we present a details recurrent refinement module to enhance the output in a high-resolution space. To train DocAligner, we construct a synthetic dataset and introduce a self-supervised learning approach to enhance its robustness for real-world data. Through extensive experiments, we demonstrate the effectiveness of DocAligner and the acquired dataset. Datasets and codes will be publicly available.
Don't Forget Me: Accurate Background Recovery for Text Removal via Modeling Local-Global Context
Jul 21, 2022
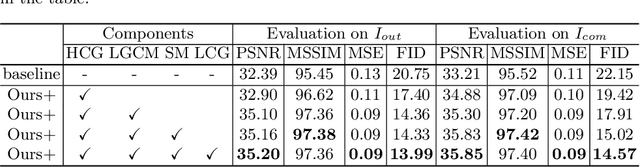
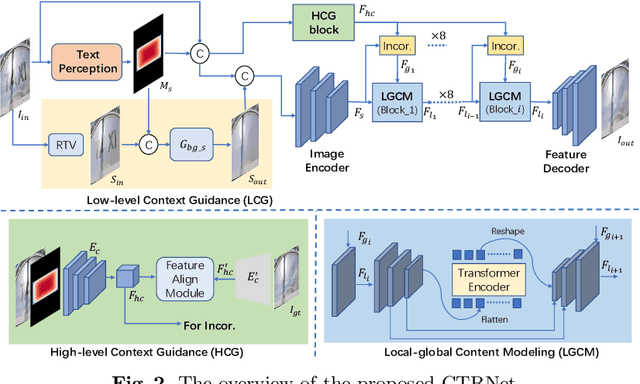
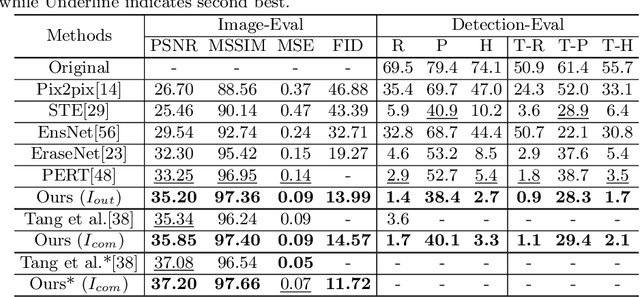
Text removal has attracted increasingly attention due to its various applications on privacy protection, document restoration, and text editing. It has shown significant progress with deep neural network. However, most of the existing methods often generate inconsistent results for complex background. To address this issue, we propose a Contextual-guided Text Removal Network, termed as CTRNet. CTRNet explores both low-level structure and high-level discriminative context feature as prior knowledge to guide the process of background restoration. We further propose a Local-global Content Modeling (LGCM) block with CNNs and Transformer-Encoder to capture local features and establish the long-term relationship among pixels globally. Finally, we incorporate LGCM with context guidance for feature modeling and decoding. Experiments on benchmark datasets, SCUT-EnsText and SCUT-Syn show that CTRNet significantly outperforms the existing state-of-the-art methods. Furthermore, a qualitative experiment on examination papers also demonstrates the generalization ability of our method. The codes and supplement materials are available at https://github.com/lcy0604/CTRNet.