 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocAligner: Annotating Real-world Photographic Document Images by Simply Taking Pictures
Jun 12, 2023



Recently, there has been a growing interest in research concerning document image analysis and recognition in photographic scenarios. However, the lack of labeled datasets for this emerging challenge poses a significant obstacle, as manual annotation can be time-consuming and impractical. To tackle this issue, we present DocAligner, a novel method that streamlines the manual annotation process to a simple step of taking pictures. DocAligner achieves this by establishing dense correspondence between photographic document images and their clean counterparts. It enables the automatic transfer of existing annotations in clean document images to photographic ones and helps to automatically acquire labels that are unavailable through manual labeling. Considering the distinctive characteristics of document images, DocAligner incorporates several innovative features. First, we propose a non-rigid pre-alignment technique based on the document's edges, which effectively eliminates interference caused by significant global shifts and repetitive patterns present in document images. Second, to handle large shifts and ensure high accuracy, we introduce a hierarchical aligning approach that combines global and local correlation layers. Furthermore, considering the importance of fine-grained elements in document images, we present a details recurrent refinement module to enhance the output in a high-resolution space. To train DocAligner, we construct a synthetic dataset and introduce a self-supervised learning approach to enhance its robustness for real-world data. Through extensive experiments, we demonstrate the effectiveness of DocAligner and the acquired dataset. Datasets and codes will be publicly available.
M$^{6}$Doc: A Large-Scale Multi-Format, Multi-Type, Multi-Layout, Multi-Language, Multi-Annotation Category Dataset for Modern Document Layout Analysis
May 21, 2023
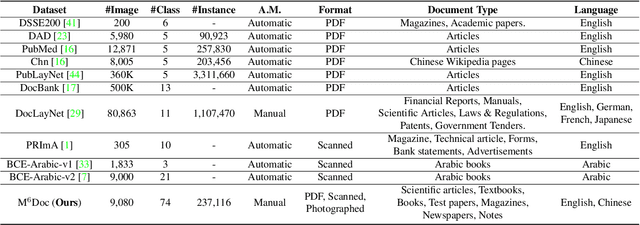
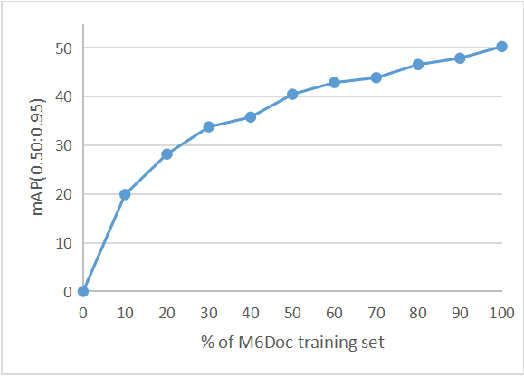
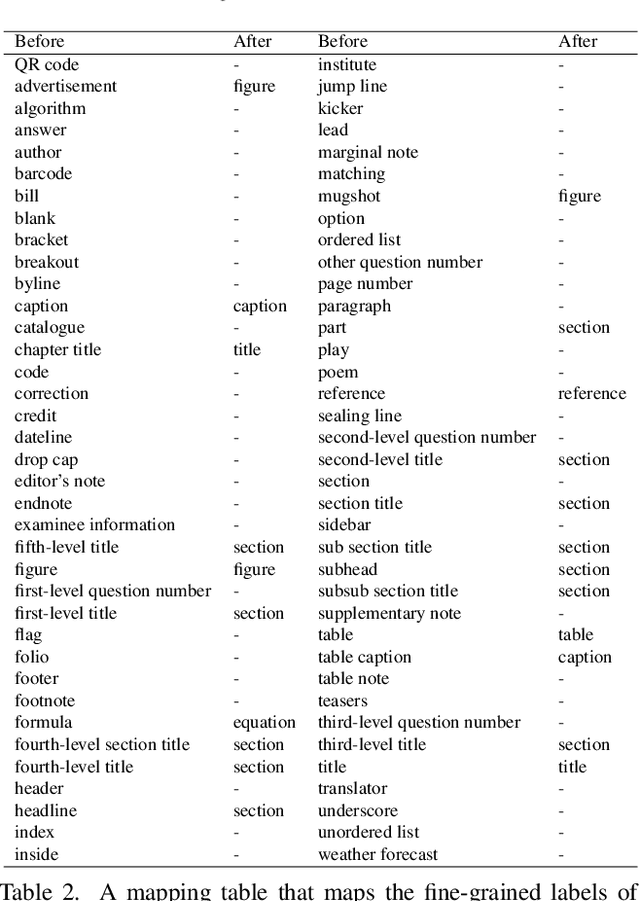
Document layout analysis is a crucial prerequisite for document understanding, including document retrieval and conversion. Most public datasets currently contain only PDF documents and lack realistic documents. Models trained on these datasets may not generalize well to real-world scenarios. Therefore, this paper introduces a large and diverse document layout analysis dataset called $M^{6}Doc$. The $M^6$ designation represents six properties: (1) Multi-Format (including scanned, photographed, and PDF documents); (2) Multi-Type (such as scientific articles, textbooks, books, test papers, magazines, newspapers, and notes); (3) Multi-Layout (rectangular, Manhattan, non-Manhattan, and multi-column Manhattan); (4) Multi-Language (Chinese and English); (5) Multi-Annotation Category (74 types of annotation labels with 237,116 annotation instances in 9,080 manually annotated pages); and (6) Modern documents. Additionally, we propose a transformer-based document layout analysis method called TransDLANet, which leverages an adaptive element matching mechanism that enables query embedding to better match ground truth to improve recall, and constructs a segmentation branch for more precise document image instance segmentation. We conduct a comprehensive evaluation of $M^{6}Doc$ with various layout analysis methods and demonstrate its effectiveness. TransDLANet achieves state-of-the-art performance on $M^{6}Doc$ with 64.5% mAP. The $M^{6}Doc$ dataset will be available at https://github.com/HCIILAB/M6Doc.