 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFollow-Your-Motion: Video Motion Transfer via Efficient Spatial-Temporal Decoupled Finetuning
Jun 05, 2025Recently, breakthroughs in the video diffusion transformer have shown remarkable capabilities in diverse motion generations. As for the motion-transfer task, current methods mainly use two-stage Low-Rank Adaptations (LoRAs) finetuning to obtain better performance. However, existing adaptation-based motion transfer still suffers from motion inconsistency and tuning inefficiency when applied to large video diffusion transformers. Naive two-stage LoRA tuning struggles to maintain motion consistency between generated and input videos due to the inherent spatial-temporal coupling in the 3D attention operator. Additionally, they require time-consuming fine-tuning processes in both stages. To tackle these issues, we propose Follow-Your-Motion, an efficient two-stage video motion transfer framework that finetunes a powerful video diffusion transformer to synthesize complex motion.Specifically, we propose a spatial-temporal decoupled LoRA to decouple the attention architecture for spatial appearance and temporal motion processing. During the second training stage, we design the sparse motion sampling and adaptive RoPE to accelerate the tuning speed. To address the lack of a benchmark for this field, we introduce MotionBench, a comprehensive benchmark comprising diverse motion, including creative camera motion, single object motion, multiple object motion, and complex human motion. We show extensive evaluations on MotionBench to verify the superiority of Follow-Your-Motion.
Delta Decompression for MoE-based LLMs Compression
Feb 24, 2025



Mixture-of-Experts (MoE) architectures in large language models (LLMs) achieve exceptional performance, but face prohibitive storage and memory requirements. To address these challenges, we present $D^2$-MoE, a new delta decompression compressor for reducing the parameters of MoE LLMs. Based on observations of expert diversity, we decompose their weights into a shared base weight and unique delta weights. Specifically, our method first merges each expert's weight into the base weight using the Fisher information matrix to capture shared components. Then, we compress delta weights through Singular Value Decomposition (SVD) by exploiting their low-rank properties. Finally, we introduce a semi-dynamical structured pruning strategy for the base weights, combining static and dynamic redundancy analysis to achieve further parameter reduction while maintaining input adaptivity. In this way, our $D^2$-MoE successfully compact MoE LLMs to high compression ratios without additional training. Extensive experiments highlight the superiority of our approach, with over 13% performance gains than other compressors on Mixtral|Phi-3.5|DeepSeek|Qwen2 MoE LLMs at 40$\sim$60% compression rates. Codes are available in https://github.com/lliai/D2MoE.
An Experimental Study on Decomposition-Based Deep Ensemble Learning for Traffic Flow Forecasting
Nov 06, 2024Traffic flow forecasting is a crucial task in intelligent transport systems. Deep learning offers an effective solution, capturing complex patterns in time-series traffic flow data to enable the accurate prediction. However, deep learning models are prone to overfitting the intricate details of flow data, leading to poor generalisation. Recent studies suggest that decomposition-based deep ensemble learning methods may address this issue by breaking down a time series into multiple simpler signals, upon which deep learning models are built and ensembled to generate the final prediction. However, few studies have compared the performance of decomposition-based ensemble methods with non-decomposition-based ones which directly utilise raw time-series data. This work compares several decomposition-based and non-decomposition-based deep ensemble learning methods. Experimental results on three traffic datasets demonstrate the superiority of decomposition-based ensemble methods, while also revealing their sensitivity to aggregation strategies and forecasting horizons.
Decentralised Traffic Incident Detection via Network Lasso
Feb 28, 2024Traffic incident detection plays a key role in intelligent transportation systems, which has gained great attention in transport engineering. In the past, traditional machine learning (ML) based detection methods achieved good performance under a centralised computing paradigm, where all data are transmitted to a central server for building ML models therein. Nowadays, deep neural networks based federated learning (FL) has become a mainstream detection approach to enable the model training in a decentralised manner while warranting local data governance. Such neural networks-centred techniques, however, have overshadowed the utility of well-established ML-based detection methods. In this work, we aim to explore the potential of potent conventional ML-based detection models in modern traffic scenarios featured by distributed data. We leverage an elegant but less explored distributed optimisation framework named Network Lasso, with guaranteed global convergence for convex problem formulations, integrate the potent convex ML model with it, and compare it with centralised learning, local learning, and federated learning methods atop a well-known traffic incident detection dataset. Experimental results show that the proposed network lasso-based approach provides a promising alternative to the FL-based approach in data-decentralised traffic scenarios, with a strong convergence guarantee while rekindling the significance of conventional ML-based detection methods.
M$^{6}$Doc: A Large-Scale Multi-Format, Multi-Type, Multi-Layout, Multi-Language, Multi-Annotation Category Dataset for Modern Document Layout Analysis
May 21, 2023
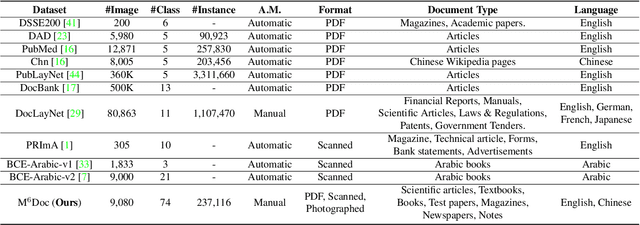
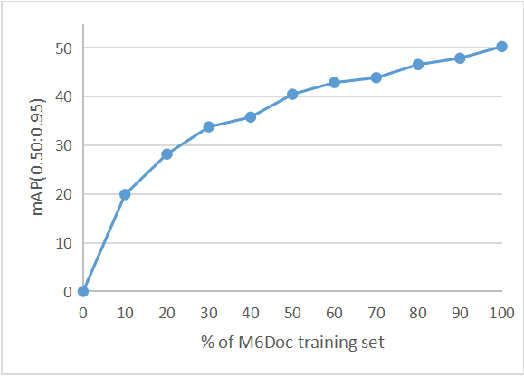
Document layout analysis is a crucial prerequisite for document understanding, including document retrieval and conversion. Most public datasets currently contain only PDF documents and lack realistic documents. Models trained on these datasets may not generalize well to real-world scenarios. Therefore, this paper introduces a large and diverse document layout analysis dataset called $M^{6}Doc$. The $M^6$ designation represents six properties: (1) Multi-Format (including scanned, photographed, and PDF documents); (2) Multi-Type (such as scientific articles, textbooks, books, test papers, magazines, newspapers, and notes); (3) Multi-Layout (rectangular, Manhattan, non-Manhattan, and multi-column Manhattan); (4) Multi-Language (Chinese and English); (5) Multi-Annotation Category (74 types of annotation labels with 237,116 annotation instances in 9,080 manually annotated pages); and (6) Modern documents. Additionally, we propose a transformer-based document layout analysis method called TransDLANet, which leverages an adaptive element matching mechanism that enables query embedding to better match ground truth to improve recall, and constructs a segmentation branch for more precise document image instance segmentation. We conduct a comprehensive evaluation of $M^{6}Doc$ with various layout analysis methods and demonstrate its effectiveness. TransDLANet achieves state-of-the-art performance on $M^{6}Doc$ with 64.5% mAP. The $M^{6}Doc$ dataset will be available at https://github.com/HCIILAB/M6Doc.
Look Closer to Supervise Better: One-Shot Font Generation via Component-Based Discriminator
Apr 30, 2022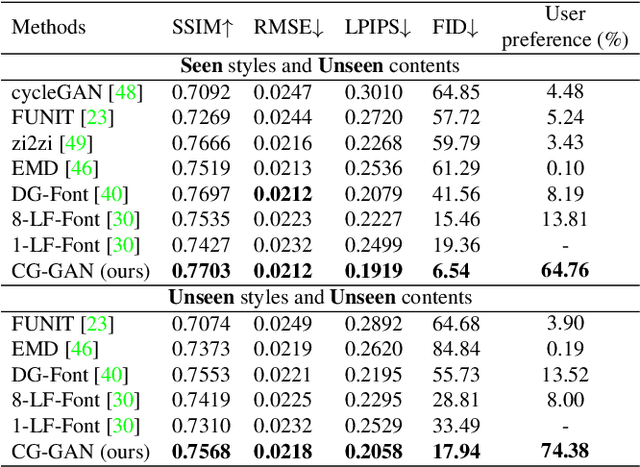
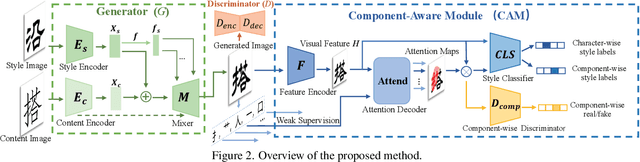


Automatic font generation remains a challenging research issue due to the large amounts of characters with complicated structures. Typically, only a few samples can serve as the style/content reference (termed few-shot learning), which further increases the difficulty to preserve local style patterns or detailed glyph structures. We investigate the drawbacks of previous studies and find that a coarse-grained discriminator is insufficient for supervising a font generator. To this end, we propose a novel Component-Aware Module (CAM), which supervises the generator to decouple content and style at a more fine-grained level, \textit{i.e.}, the component level. Different from previous studies struggling to increase the complexity of generators, we aim to perform more effective supervision for a relatively simple generator to achieve its full potential, which is a brand new perspective for font generation. The whole framework achieves remarkable results by coupling component-level supervision with adversarial learning, hence we call it Component-Guided GAN, shortly CG-GAN. Extensive experiments show that our approach outperforms state-of-the-art one-shot font generation methods. Furthermore, it can be applied to handwritten word synthesis and scene text image editing, suggesting the generalization of our approach.