 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFollow-Your-Shape: Shape-Aware Image Editing via Trajectory-Guided Region Control
Aug 12, 2025



While recent flow-based image editing models demonstrate general-purpose capabilities across diverse tasks, they often struggle to specialize in challenging scenarios -- particularly those involving large-scale shape transformations. When performing such structural edits, these methods either fail to achieve the intended shape change or inadvertently alter non-target regions, resulting in degraded background quality. We propose Follow-Your-Shape, a training-free and mask-free framework that supports precise and controllable editing of object shapes while strictly preserving non-target content. Motivated by the divergence between inversion and editing trajectories, we compute a Trajectory Divergence Map (TDM) by comparing token-wise velocity differences between the inversion and denoising paths. The TDM enables precise localization of editable regions and guides a Scheduled KV Injection mechanism that ensures stable and faithful editing. To facilitate a rigorous evaluation, we introduce ReShapeBench, a new benchmark comprising 120 new images and enriched prompt pairs specifically curated for shape-aware editing. Experiments demonstrate that our method achieves superior editability and visual fidelity, particularly in tasks requiring large-scale shape replacement.
Follow-Your-Instruction: A Comprehensive MLLM Agent for World Data Synthesis
Aug 07, 2025With the growing demands of AI-generated content (AIGC), the need for high-quality, diverse, and scalable data has become increasingly crucial. However, collecting large-scale real-world data remains costly and time-consuming, hindering the development of downstream applications. While some works attempt to collect task-specific data via a rendering process, most approaches still rely on manual scene construction, limiting their scalability and accuracy. To address these challenges, we propose Follow-Your-Instruction, a Multimodal Large Language Model (MLLM)-driven framework for automatically synthesizing high-quality 2D, 3D, and 4D data. Our \textbf{Follow-Your-Instruction} first collects assets and their associated descriptions through multimodal inputs using the MLLM-Collector. Then it constructs 3D layouts, and leverages Vision-Language Models (VLMs) for semantic refinement through multi-view scenes with the MLLM-Generator and MLLM-Optimizer, respectively. Finally, it uses MLLM-Planner to generate temporally coherent future frames. We evaluate the quality of the generated data through comprehensive experiments on the 2D, 3D, and 4D generative tasks. The results show that our synthetic data significantly boosts the performance of existing baseline models, demonstrating Follow-Your-Instruction's potential as a scalable and effective data engine for generative intelligence.
Follow-Your-Motion: Video Motion Transfer via Efficient Spatial-Temporal Decoupled Finetuning
Jun 05, 2025Recently, breakthroughs in the video diffusion transformer have shown remarkable capabilities in diverse motion generations. As for the motion-transfer task, current methods mainly use two-stage Low-Rank Adaptations (LoRAs) finetuning to obtain better performance. However, existing adaptation-based motion transfer still suffers from motion inconsistency and tuning inefficiency when applied to large video diffusion transformers. Naive two-stage LoRA tuning struggles to maintain motion consistency between generated and input videos due to the inherent spatial-temporal coupling in the 3D attention operator. Additionally, they require time-consuming fine-tuning processes in both stages. To tackle these issues, we propose Follow-Your-Motion, an efficient two-stage video motion transfer framework that finetunes a powerful video diffusion transformer to synthesize complex motion.Specifically, we propose a spatial-temporal decoupled LoRA to decouple the attention architecture for spatial appearance and temporal motion processing. During the second training stage, we design the sparse motion sampling and adaptive RoPE to accelerate the tuning speed. To address the lack of a benchmark for this field, we introduce MotionBench, a comprehensive benchmark comprising diverse motion, including creative camera motion, single object motion, multiple object motion, and complex human motion. We show extensive evaluations on MotionBench to verify the superiority of Follow-Your-Motion.
Follow-Your-Creation: Empowering 4D Creation through Video Inpainting
Jun 05, 2025



We introduce Follow-Your-Creation, a novel 4D video creation framework capable of both generating and editing 4D content from a single monocular video input. By leveraging a powerful video inpainting foundation model as a generative prior, we reformulate 4D video creation as a video inpainting task, enabling the model to fill in missing content caused by camera trajectory changes or user edits. To facilitate this, we generate composite masked inpainting video data to effectively fine-tune the model for 4D video generation. Given an input video and its associated camera trajectory, we first perform depth-based point cloud rendering to obtain invisibility masks that indicate the regions that should be completed. Simultaneously, editing masks are introduced to specify user-defined modifications, and these are combined with the invisibility masks to create a composite masks dataset. During training, we randomly sample different types of masks to construct diverse and challenging inpainting scenarios, enhancing the model's generalization and robustness in various 4D editing and generation tasks. To handle temporal consistency under large camera motion, we design a self-iterative tuning strategy that gradually increases the viewing angles during training, where the model is used to generate the next-stage training data after each fine-tuning iteration. Moreover, we introduce a temporal packaging module during inference to enhance generation quality. Our method effectively leverages the prior knowledge of the base model without degrading its original performance, enabling the generation of 4D videos with consistent multi-view coherence. In addition, our approach supports prompt-based content editing, demonstrating strong flexibility and significantly outperforming state-of-the-art methods in both quality and versatility.
Towards Effective and Sparse Adversarial Attack on Spiking Neural Networks via Breaking Invisible Surrogate Gradients
Mar 05, 2025Spiking neural networks (SNNs) have shown their competence in handling spatial-temporal event-based data with low energy consumption. Similar to conventional artificial neural networks (ANNs), SNNs are also vulnerable to gradient-based adversarial attacks, wherein gradients are calculated by spatial-temporal back-propagation (STBP) and surrogate gradients (SGs). However, the SGs may be invisible for an inference-only model as they do not influence the inference results, and current gradient-based attacks are ineffective for binary dynamic images captured by the dynamic vision sensor (DVS). While some approaches addressed the issue of invisible SGs through universal SGs, their SGs lack a correlation with the victim model, resulting in sub-optimal performance. Moreover, the imperceptibility of existing SNN-based binary attacks is still insufficient. In this paper, we introduce an innovative potential-dependent surrogate gradient (PDSG) method to establish a robust connection between the SG and the model, thereby enhancing the adaptability of adversarial attacks across various models with invisible SGs. Additionally, we propose the sparse dynamic attack (SDA) to effectively attack binary dynamic images. Utilizing a generation-reduction paradigm, SDA can fully optimize the sparsity of adversarial perturbations. Experimental results demonstrate that our PDSG and SDA outperform state-of-the-art SNN-based attacks across various models and datasets. Specifically, our PDSG achieves 100% attack success rate on ImageNet, and our SDA obtains 82% attack success rate by modifying only 0.24% of the pixels on CIFAR10DVS. The code is available at https://github.com/ryime/PDSG-SDA .
DiT4Edit: Diffusion Transformer for Image Editing
Nov 05, 2024

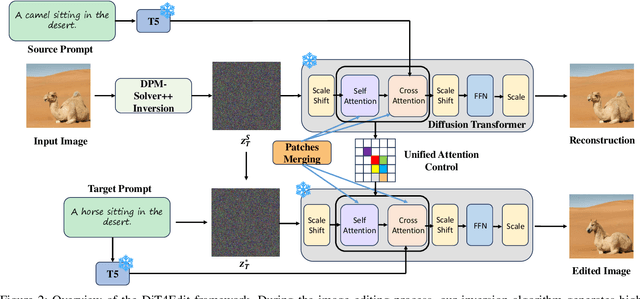

Despite recent advances in UNet-based image editing, methods for shape-aware object editing in high-resolution images are still lacking. Compared to UNet, Diffusion Transformers (DiT) demonstrate superior capabilities to effectively capture the long-range dependencies among patches, leading to higher-quality image generation. In this paper, we propose DiT4Edit, the first Diffusion Transformer-based image editing framework. Specifically, DiT4Edit uses the DPM-Solver inversion algorithm to obtain the inverted latents, reducing the number of steps compared to the DDIM inversion algorithm commonly used in UNet-based frameworks. Additionally, we design unified attention control and patches merging, tailored for transformer computation streams. This integration allows our framework to generate higher-quality edited images faster. Our design leverages the advantages of DiT, enabling it to surpass UNet structures in image editing, especially in high-resolution and arbitrary-size images. Extensive experiments demonstrate the strong performance of DiT4Edit across various editing scenarios, highlighting the potential of Diffusion Transformers in supporting image editing.