 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmoVid: A Multimodal Emotion Video Dataset for Emotion-Centric Video Understanding and Generation
Nov 14, 2025



Emotion plays a pivotal role in video-based expression, but existing video generation systems predominantly focus on low-level visual metrics while neglecting affective dimensions. Although emotion analysis has made progress in the visual domain, the video community lacks dedicated resources to bridge emotion understanding with generative tasks, particularly for stylized and non-realistic contexts. To address this gap, we introduce EmoVid, the first multimodal, emotion-annotated video dataset specifically designed for creative media, which includes cartoon animations, movie clips, and animated stickers. Each video is annotated with emotion labels, visual attributes (brightness, colorfulness, hue), and text captions. Through systematic analysis, we uncover spatial and temporal patterns linking visual features to emotional perceptions across diverse video forms. Building on these insights, we develop an emotion-conditioned video generation technique by fine-tuning the Wan2.1 model. The results show a significant improvement in both quantitative metrics and the visual quality of generated videos for text-to-video and image-to-video tasks. EmoVid establishes a new benchmark for affective video computing. Our work not only offers valuable insights into visual emotion analysis in artistically styled videos, but also provides practical methods for enhancing emotional expression in video generation.
MagicAnime: A Hierarchically Annotated, Multimodal and Multitasking Dataset with Benchmarks for Cartoon Animation Generation
Jul 27, 2025Generating high-quality cartoon animations multimodal control is challenging due to the complexity of non-human characters, stylistically diverse motions and fine-grained emotions. There is a huge domain gap between real-world videos and cartoon animation, as cartoon animation is usually abstract and has exaggerated motion. Meanwhile, public multimodal cartoon data are extremely scarce due to the difficulty of large-scale automatic annotation processes compared with real-life scenarios. To bridge this gap, We propose the MagicAnime dataset, a large-scale, hierarchically annotated, and multimodal dataset designed to support multiple video generation tasks, along with the benchmarks it includes. Containing 400k video clips for image-to-video generation, 50k pairs of video clips and keypoints for whole-body annotation, 12k pairs of video clips for video-to-video face animation, and 2.9k pairs of video and audio clips for audio-driven face animation. Meanwhile, we also build a set of multi-modal cartoon animation benchmarks, called MagicAnime-Bench, to support the comparisons of different methods in the tasks above. Comprehensive experiments on four tasks, including video-driven face animation, audio-driven face animation, image-to-video animation, and pose-driven character animation, validate its effectiveness in supporting high-fidelity, fine-grained, and controllable generation.
DiT4Edit: Diffusion Transformer for Image Editing
Nov 05, 2024

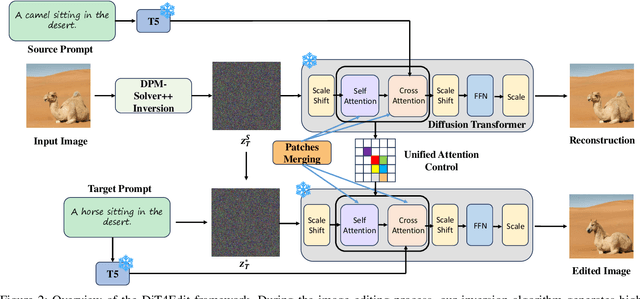

Despite recent advances in UNet-based image editing, methods for shape-aware object editing in high-resolution images are still lacking. Compared to UNet, Diffusion Transformers (DiT) demonstrate superior capabilities to effectively capture the long-range dependencies among patches, leading to higher-quality image generation. In this paper, we propose DiT4Edit, the first Diffusion Transformer-based image editing framework. Specifically, DiT4Edit uses the DPM-Solver inversion algorithm to obtain the inverted latents, reducing the number of steps compared to the DDIM inversion algorithm commonly used in UNet-based frameworks. Additionally, we design unified attention control and patches merging, tailored for transformer computation streams. This integration allows our framework to generate higher-quality edited images faster. Our design leverages the advantages of DiT, enabling it to surpass UNet structures in image editing, especially in high-resolution and arbitrary-size images. Extensive experiments demonstrate the strong performance of DiT4Edit across various editing scenarios, highlighting the potential of Diffusion Transformers in supporting image editing.
Diffusion-Based Visual Art Creation: A Survey and New Perspectives
Aug 22, 2024The integration of generative AI in visual art has revolutionized not only how visual content is created but also how AI interacts with and reflects the underlying domain knowledge. This survey explores the emerging realm of diffusion-based visual art creation, examining its development from both artistic and technical perspectives. We structure the survey into three phases, data feature and framework identification, detailed analyses using a structured coding process, and open-ended prospective outlooks. Our findings reveal how artistic requirements are transformed into technical challenges and highlight the design and application of diffusion-based methods within visual art creation. We also provide insights into future directions from technical and synergistic perspectives, suggesting that the confluence of generative AI and art has shifted the creative paradigm and opened up new possibilities. By summarizing the development and trends of this emerging interdisciplinary area, we aim to shed light on the mechanisms through which AI systems emulate and possibly, enhance human capacities in artistic perception and creativity.
MagicScroll: Nontypical Aspect-Ratio Image Generation for Visual Storytelling via Multi-Layered Semantic-Aware Denoising
Dec 18, 2023Visual storytelling often uses nontypical aspect-ratio images like scroll paintings, comic strips, and panoramas to create an expressive and compelling narrative. While generative AI has achieved great success and shown the potential to reshape the creative industry, it remains a challenge to generate coherent and engaging content with arbitrary size and controllable style, concept, and layout, all of which are essential for visual storytelling. To overcome the shortcomings of previous methods including repetitive content, style inconsistency, and lack of controllability, we propose MagicScroll, a multi-layered, progressive diffusion-based image generation framework with a novel semantic-aware denoising process. The model enables fine-grained control over the generated image on object, scene, and background levels with text, image, and layout conditions. We also establish the first benchmark for nontypical aspect-ratio image generation for visual storytelling including mediums like paintings, comics, and cinematic panoramas, with customized metrics for systematic evaluation. Through comparative and ablation studies, MagicScroll showcases promising results in aligning with the narrative text, improving visual coherence, and engaging the audience. We plan to release the code and benchmark in the hope of a better collaboration between AI researchers and creative practitioners involving visual storytelling.